
前面的文章我们详细讲过,大型语言模型虽在自然语言处理领域展现卓越能力,但仍面临幻觉问题、知识时效性不足及领域专业性缺失的问题,结合rag通过“检索外部知识+增强模型生成”的范式,作为大模型的“外置知识库”有效缓解上述痛点,无需重新训练即可动态整合最新领域知识,显著提升回答准确性与可信度。
然而,传统 RAG 系统在处理大规模知识库时存在显著局限:全局检索模式易受噪声干扰,高维嵌入导致存储与延迟的可扩展性瓶颈,且上下文输入中冗余信息占比高,造成计算资源浪费。
KMeans++ 聚类算法通过优化初始中心选择策略,提升了传统 K-means 的稳定性,能够将高维文本嵌入按语义相似性划分为独立分区,实现“先聚类后检索”的二级优化架构,可以有效解决传统 RAG 的检索效率与准确性瓶颈。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

传统 KMeans 算法在实际应用中存在三大核心局限:需预先确定簇数、对噪声数据敏感,以及聚类结果严重依赖簇中心初始位置。其中初始中心选择的随机性可能导致聚类质量显著波动——在相同数据集上,不同随机初始点可能产生差异较大的簇划分结果,甚至陷入局部最优解。这种不稳定性在高维数据场景(如文本向量聚类)中尤为突出,直接影响后续任务的可靠性。
为解决这一问题,KMeans++ 算法通过改进初始簇中心的选择策略,使聚类过程更可能收敛至全局较优解。其核心创新在于基于距离加权的概率采样机制,即离已选中心越远的样本点被选为下一个中心的概率越高。
前一篇文章我们已经详细讲机过了KMeans,今天我们通过示例强化一下Kmeans++的运行逻辑,这个示例实现了 K-Means++ 聚类算法的完整可视化过程,包括初始化阶段和聚类迭代阶段,先看看示例的重点部分,附录中附上完整代码:
1.1 初始设置和导入库
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.animation import FuncAnimationfrom matplotlib import cmimport matplotlib.colors as mcolorsimport osimport imageio # 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = False
1.2 创建输出目录
if not os.path.exists('kmeans_frames'): os.makedirs('kmeans_frames')1.3 生成示例数据
np.random.seed(42)n_samples = 100n_clusters = 4# 生成四个高斯分布的数据点X1 = np.random.normal([2, 2], 0.5, [n_samples//4, 2])X2 = np.random.normal([-2, 2], 0.5, [n_samples//4, 2])X3 = np.random.normal([-2, -2], 0.5, [n_samples//4, 2])X4 = np.random.normal([2, -2], 0.5, [n_samples//4, 2])X = np.vstack([X1, X2, X3, X4])
1.4 初始化图形界面
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))fig.suptitle('K-Means++ 算法原理动态演示', fontsize=16) # 左图:K-Means++ 初始化过程ax1.set_xlim(-4, 4)ax1.set_ylim(-4, 4)ax1.set_title('K-Means++ 初始化过程')ax1.grid(True, linestyle='--', alpha=0.7) # 右图:K-Means 聚类过程ax2.set_xlim(-4, 4)ax2.set_ylim(-4, 4)ax2.set_title('K-Means 聚类过程')ax2.grid(True, linestyle='--', alpha=0.7)1.5 初始化变量和颜色设置
# 绘制初始数据点scatter1 = ax1.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7)scatter2 = ax2.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7) # 初始化变量centers = []probabilities = np.ones(len(X)) / len(X) # 初始概率均匀分布current_center_idx = Nonedistance_text = ax1.text(0.02, 0.98, "", transform=ax1.transAxes, fontsize=10, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))info_text = ax2.text(0.02, 0.98, "", transform=ax2.transAxes, fontsize=10, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8)) # 颜色映射colors = list(mcolors.TABLEAU_COLORS.values())cluster_colors = colors[:n_clusters] # 为每个簇分配一个颜色 # 存储中心点轨迹center_trajectories = [[] for _ in range(n_clusters)] # K-Means 聚类变量labels = Noneiteration = 0max_iterations = 10 # 存储所有帧frames = []
1.6 初始化函数
def init(): """初始化动画""" scatter1.set_offsets(X) scatter2.set_offsets(X) distance_text.set_text("") info_text.set_text("准备开始 K-Means++ 初始化...") return scatter1, scatter2, distance_text, info_text1.7 K-Means++ 初始化步骤函数
def kmeans_plus_plus_init_step(i): """K-Means++ 初始化步骤""" global centers, current_center_idx, probabilities if i == 0: # 第一步:随机选择第一个中心点 # ...(详细代码) elif i == 1 and len(centers) < n_clusters: # 第二步:计算距离并显示 # ...(详细代码) elif i == 2 and len(centers) < n_clusters: # 第三步:选择下一个中心点 # ...(详细代码) elif i >= 3 and len(centers) < n_clusters: # 重复步骤2-3直到选择足够的中心点 # ...(详细代码) elif len(centers) == n_clusters: # 初始化完成,开始 K-Means 聚类 # ...(详细代码) return scatter1, scatter2, distance_text, info_text
1.8 K-Means 聚类步骤函数
def kmeans_step(i): """K-Means 聚类步骤""" global centers, labels, iteration, cluster_colors, center_trajectories if len(centers) < n_clusters: return scatter1, scatter2, distance_text, info_text # 确保centers是NumPy数组 centers_array = np.array(centers) # 第一次迭代 if iteration == 0: # 分配步骤:将每个点分配到最近的中心点 # ...(详细代码) elif iteration < max_iterations: if iteration % 2 == 1: # 更新步骤:重新计算中心点 # ...(详细代码) else: # 分配步骤:重新分配点 # ...(详细代码) else: info_text.set_text("K-Means 算法已收敛!聚类完成") # 绘制中心点轨迹 for j in range(n_clusters): if len(center_trajectories[j]) > 1: trajectory = np.array(center_trajectories[j]) ax2.plot(trajectory[:, 0], trajectory[:, 1], '--', color=cluster_colors[j], alpha=0.7) return scatter1, scatter2, distance_text, info_text1.9 更新函数
def update(i): """更新函数""" if i < 12: # 前12帧用于K-Means++初始化 return kmeans_plus_plus_init_step(i) else: # 后续帧用于K-Means聚类 return kmeans_step(i - 12)
1.10 主循环和步骤图生成
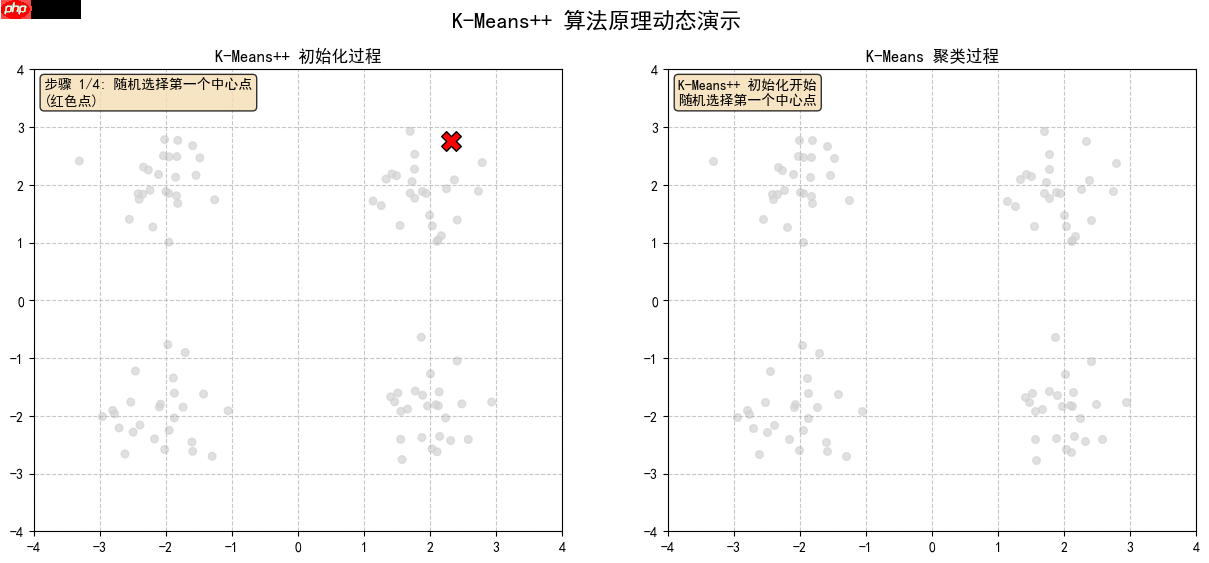
# 创建动画并保存每一帧for i in range(25): # 清除右图中的轨迹线,但保留中心点 if i >= 12: # 清除之前的轨迹线 for line in ax2.get_lines(): line.remove() # 更新动画 update(i) # 保存当前帧 frame_path = f'kmeans_frames/frame_{i:02d}.png' plt.savefig(frame_path, dpi=100, bbox_inches='tight') frames.append(imageio.imread(frame_path)) print(f'已保存第 {i+1}/25 帧') plt.tight_layout()plt.show()2.1 随机选择第一个中心点(红色点)
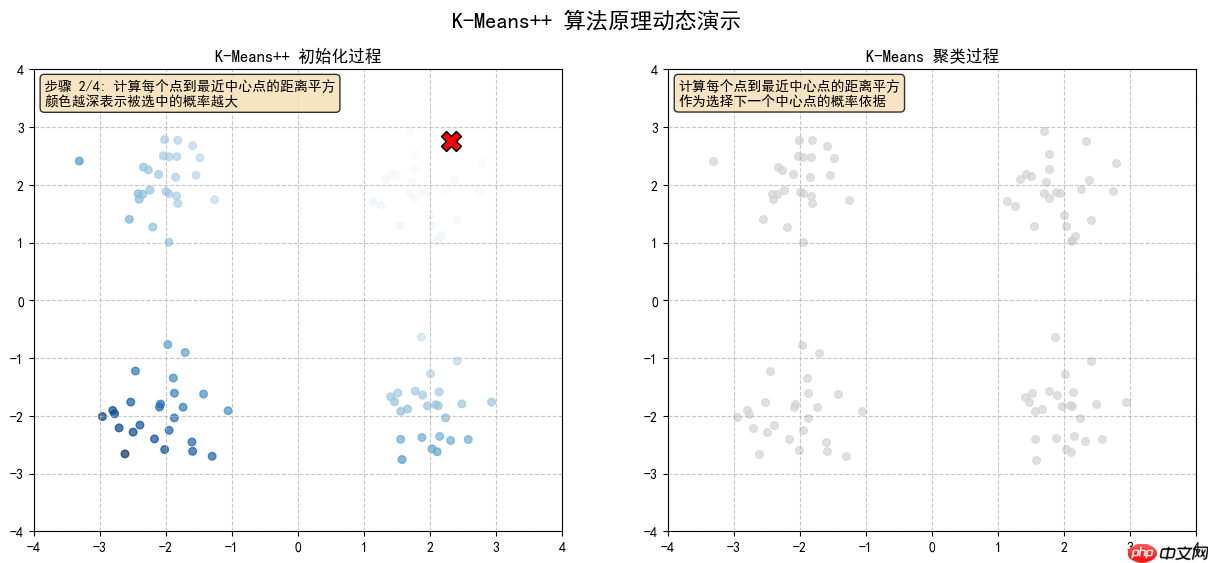
2.2 计算每个点到最近中心点的距离平方,颜色越深表示被选中的概率越大
2.3 根据概率选择下一个中心点,(黄色高亮点)

2.4 计算每个点到最近中心点的距离平方,颜色越深表示被选中的概率越大
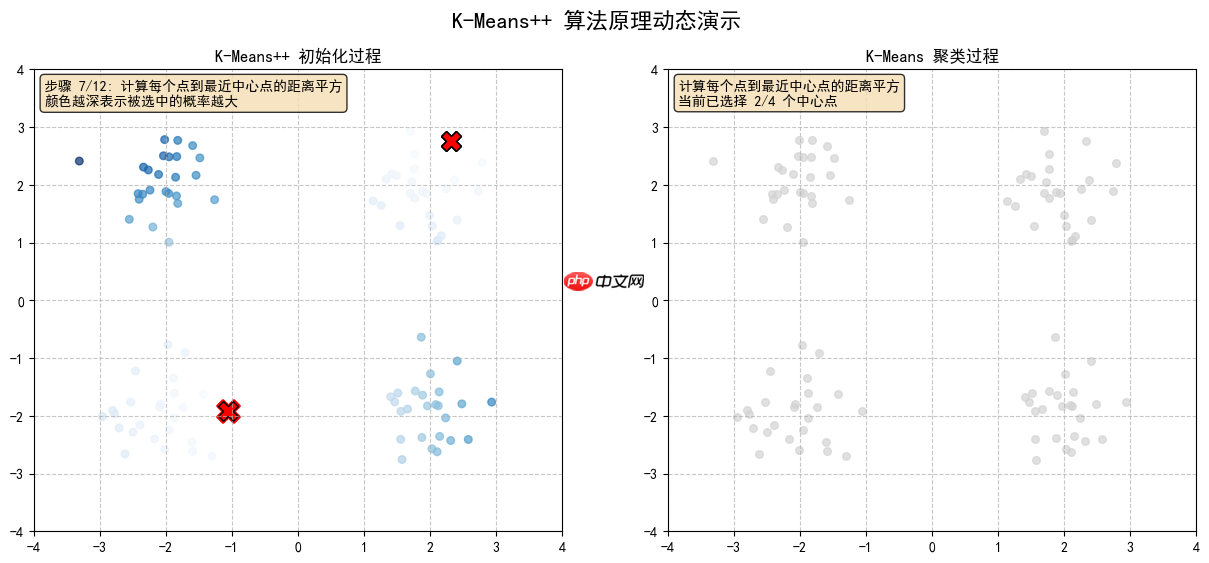
2.5 根据概率选择下一个中心点,(黄色高亮点)
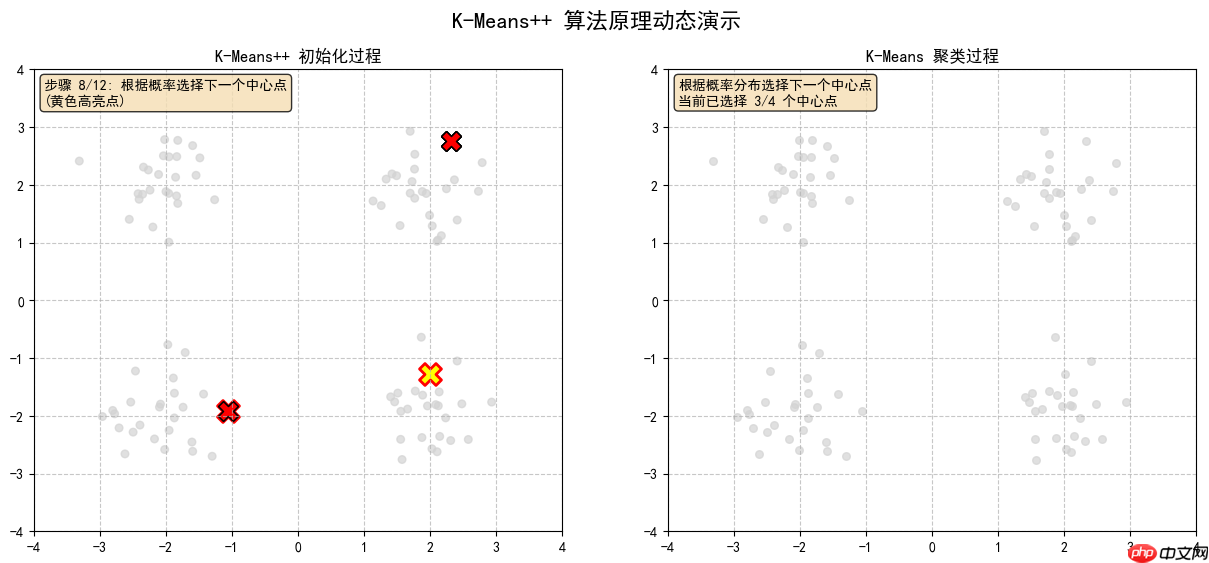
2.6 计算每个点到最近中心点的距离平方,颜色越深表示被选中的概率越大

2.7 根据概率选择下一个中心点,(黄色高亮点)

2.8 K-Means++ 初始化完成!已选择所有初始中心点
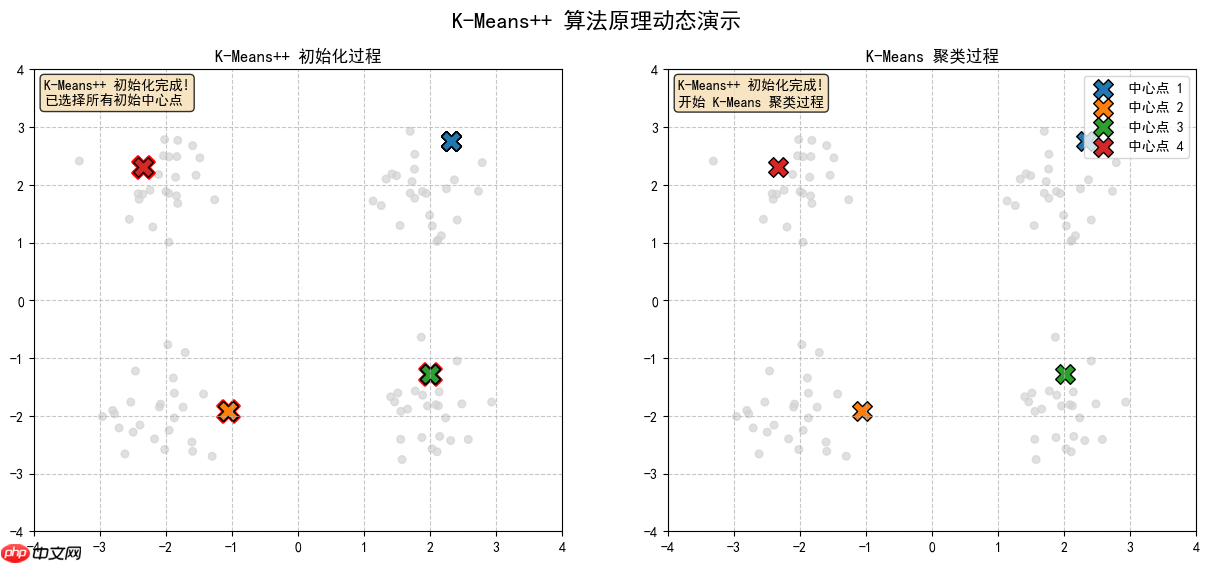
2.9 K-Means聚类,形成最终结果
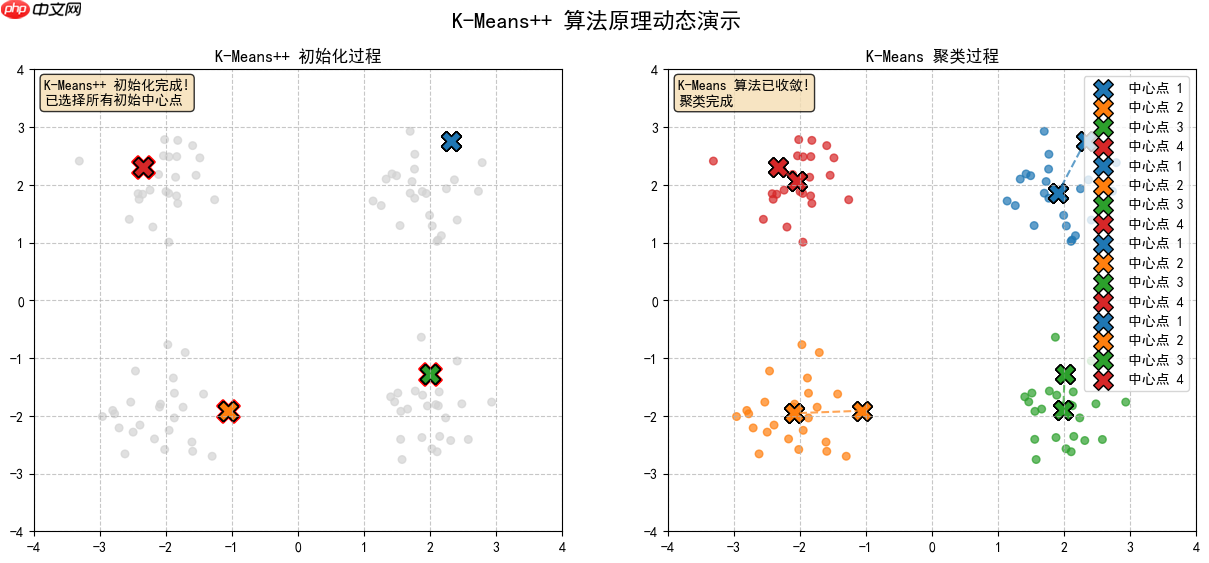
开始|生成数据(四个高斯分布)|初始化图形(两个子图)|初始化变量(中心点列表、概率、轨迹等)|循环25次,每次循环为一帧:||--> 如果当前帧数<12:执行K-Means++初始化步骤| || |--> 帧0:随机选择第一个中心点| |--> 帧1:计算每个点到最近中心点的距离平方,显示概率分布| |--> 帧2:根据概率选择下一个中心点| |--> 帧3-5:重复计算距离、选择中心点、显示概率(选择第三个中心点)| |--> 帧6-8:重复(选择第四个中心点)| |--> 帧9-11:完成初始化,显示最终中心点||--> 否则(帧数>=12):执行K-Means聚类步骤| || |--> 清除右图轨迹线(为了重新绘制)| |--> 如果是第一次进入聚类(帧12):执行分配步骤(iteration=0)| |--> 帧13:执行更新步骤(iteration=1)| |--> 帧14:执行分配步骤(iteration=2)| |--> ... 依次交替,直到帧24:执行第10次迭代(iteration=9,更新步骤)| |--> 绘制中心点轨迹||--> 保存当前帧为PNG图片|循环结束|结束
K-Means++ 初始化:
随机选择第一个中心点计算每个点到最近中心点的距离平方根据距离平方的概率分布选择下一个中心点重复步骤 2-3 直到选择足够数量的中心点K-Means 聚类:
分配步骤:将每个点分配到最近的中心点更新步骤:重新计算每个簇的中心点位置重复步骤 1-2 直到收敛或达到最大迭代次数这段示例实现了一个完整的文档聚类分析系统,使用K-Means++算法对中文文档进行聚类,生成簇的名称和描述,并将查询映射到向量,找到最相关的簇,并返回最相关的文档
1.1 数据准备与向量化
# 1. 准备示例数据documents = [ "股市在经济复苏中创历史新高,投资者信心大增", "新研究显示地中海饮食对心脏健康的显著益处", # ... 20个中文文档] # 2. 文档向量化embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')document_embeddings = embedder.encode(documents)1.2 自定义K-Means++实现
def kmeans_plus_plus(X, n_clusters, max_iter=100, tol=1e-4): # K-Means++ 初始化 centers = np.zeros((n_clusters, n_features)) # 随机选择第一个中心点 first_idx = np.random.randint(n_samples) centers[0] = X[first_idx] # 选择剩余的中心点(基于概率分布) for i in range(1, n_clusters): distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers[:i]]) for x in X]) probabilities = distances / np.sum(distances) next_idx = np.random.choice(n_samples, p=probabilities) centers[i] = X[next_idx] # 迭代优化 for iteration in range(max_iter): # 分配样本到最近的中心点 labels = np.argmin(np.linalg.norm(X[:, np.newaxis] - centers, axis=2), axis=1) # 计算新的中心点 new_centers = np.zeros((n_clusters, n_features)) for i in range(n_clusters): cluster_points = X[labels == i] if len(cluster_points) > 0: new_centers[i] = np.mean(cluster_points, axis=0) else: # 如果簇为空,重新初始化 new_centers[i] = X[np.random.randint(n_samples)] # 检查收敛 if np.all(np.linalg.norm(new_centers - centers, axis=1) < tol): break centers = new_centers return labels, centers
1.3 关键词提取与簇命名
def extract_keywords(texts, top_n=5): """从文本中提取关键词""" words = [] for text in texts: # 移除标点符号 text_clean = re.sub(r'[^\w\s]', '', text) # 按空格和常见分隔符分割 text_words = re.split(r'[\s、,。;:!?]+', text_clean) words.extend([w for w in text_words if len(w) > 1]) # 计算词频 word_counts = Counter(words) return [word for word, count in word_counts.most_common(top_n)] def generate_cluster_name(keywords): """根据关键词生成簇名称""" if len(keywords) >= 2: return f"{keywords[0]}与{keywords[1]}" else: return f"{keywords[0]}相关"1.4 可视化展示
# 使用PCA降维pca = PCA(n_components=2)reduced_embeddings = pca.fit_transform(document_embeddings)reduced_centers = pca.transform(cluster_centers) # 创建颜色映射colors = ['red', 'blue', 'green', 'purple', 'orange', 'brown', 'pink', 'gray']cluster_colors = [colors[label % len(colors)] for label in cluster_labels] # 绘制散点图plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1], c=cluster_colors, s=100, alpha=0.7) # 标记簇中心plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1], c='black', marker='X', s=200, label='簇中心') # 为每个点添加文档索引for i, (x, y) in enumerate(reduced_embeddings): plt.annotate(str(i), (x, y), xytext=(5, 5), textcoords='offset points', fontsize=8)
1.5 簇分析与统计
# 计算簇内文档的平均相似度cluster_embeddings = document_embeddings[info['doc_indices']]if len(cluster_embeddings) > 1: similarities = [] for i in range(len(cluster_embeddings)): for j in range(i+1, len(cluster_embeddings)): sim = np.dot(cluster_embeddings[i], cluster_embeddings[j]) / ( np.linalg.norm(cluster_embeddings[i]) * np.linalg.norm(cluster_embeddings[j])) similarities.append(sim) avg_similarity = np.mean(similarities) if similarities else 0 print(f"簇内平均相似度: {avg_similarity:.3f}")1.6 查询处理功能
def find_relevant_cluster(query_embedding, cluster_centers): """找到与查询最相关的簇""" similarities = [] for center in cluster_centers: similarity = np.dot(query_embedding, center) / ( np.linalg.norm(query_embedding) * np.linalg.norm(center)) similarities.append(similarity) return np.argmax(similarities), similarities def retrieve_documents(query, top_k=3): """检索与查询相关的文档""" # 将查询转换为向量 query_embedding = embedder.encode([query])[0] # 找到最相关的簇 relevant_cluster, cluster_similarities = find_relevant_cluster(query_embedding, cluster_centers) # 计算查询与簇内文档的相似度 cluster_doc_indices = cluster_info[relevant_cluster]['doc_indices'] cluster_embeddings = document_embeddings[cluster_doc_indices] similarities = [] for emb in cluster_embeddings: similarity = np.dot(query_embedding, emb) / ( np.linalg.norm(query_embedding) * np.linalg.norm(emb)) similarities.append(similarity) # 获取最相关的文档 similarities = np.array(similarities) top_indices = np.argsort(similarities)[-top_k:][::-1] results = [] for idx in top_indices: doc_idx = cluster_doc_indices[idx] results.append((doc_idx, documents[doc_idx], similarities[idx])) return results, relevant_cluster
===================================================================文档聚类详细结果===================================================================
簇 0: 股市在经济复苏中创历史新高投资者信心大增与地方选举结果公布现任政党成功保持多数席位 (包含 9 个文档) 关键词: 股市在经济复苏中创历史新高投资者信心大增, 地方选举结果公布现任政党成功保持多数席位, 科技巨头发布最新智能手机搭载先进AI摄影功能, COVID19疫苗加强针现已向所有成年人开放接种, 苹果公司发布新一代iPhone相机系统全面升级描述: 包含9个文档,主要涉及股市在经济复苏中创历史新高投资者信心大增与地方选举结果公布现任政党成功保持多数席位。示例文档:股市在经济复苏中创历史新高,投资者信心大增;地方选举结果公布,现任政党成功保持多数席位;科技巨头发布最新智能手机,搭载先进AI摄影功能文档列表: [0] 股市在经济复苏中创历史新高,投资者信心大增 [2] 地方选举结果公布,现任政党成功保持多数席位 [3] 科技巨头发布最新智能手机,搭载先进AI摄影功能 [6] COVID-19疫苗加强针现已向所有成年人开放接种 [9] 苹果公司发布新一代iPhone,相机系统全面升级 [11] 最新研究将空气污染与阿尔茨海默病风险增加联系起来 [12] 市议会批准50亿预算用于新建公共交通系统 [15] 财政部长发表对数字货币未来发展的评论 [18] 谷歌发布核心搜索算法重大更新簇内平均相似度: 0.144------------------------------------------------------------
簇 1: 科学家在亚马逊雨林发现数十个新物种与全球气候峰会达成历史性碳排放减少协议 (包含 3 个文档) 关键词: 科学家在亚马逊雨林发现数十个新物种, 全球气候峰会达成历史性碳排放减少协议, 当地公园发现稀有鸟类物种观鸟爱好者蜂拥而至描述: 包含3个文档,主要涉及科学家在亚马逊雨林发现数十个新物种与全球气候峰会达成历史性碳排放减少协议。示例文档:科学家在亚马逊雨林发现数十个新物种;全球气候峰会达成历史性碳排放减少协议;当地公园发现稀有鸟类物种,观鸟爱好者蜂拥而至文档列表: [4] 科学家在亚马逊雨林发现数十个新物种 [8] 全球气候峰会达成历史性碳排放减少协议 [14] 当地公园发现稀有鸟类物种,观鸟爱好者蜂拥而至簇内平均相似度: 0.251------------------------------------------------------------
簇 2: 新研究显示地中海饮食对心脏健康的显著益处与癌症治疗领域突破性进展在临床试验中显示良好效果 (包含 3 个文档) 关键词: 新研究显示地中海饮食对心脏健康的显著益处, 癌症治疗领域突破性进展在临床试验中显示良好效果, 飓风逼近东部海岸居民被敦促立即撤离描述: 包含3个文档,主要涉及新研究显示地中海饮食对心脏健康的显著益处与癌症治疗领域突破性进展在临床试验中显示良好效果。示例文档:新研究显示地中海饮食对心脏健康的显著益处;癌症治疗领域突破性进展在临床试验中显示良好效果;飓风逼近东部海岸,居民被敦促立即撤离文档列表: [1] 新研究显示地中海饮食对心脏健康的显著益处 [16] 癌症治疗领域突破性进展在临床试验中显示良好效果 [19] 飓风逼近东部海岸,居民被敦促立即撤离簇内平均相似度: 0.149------------------------------------------------------------
簇 3: 美联储暗示下季度可能实施降息政策与足球队在戏剧性点球大战后赢得冠军奖杯 (包含 5 个文档) 关键词: 美联储暗示下季度可能实施降息政策, 足球队在戏剧性点球大战后赢得冠军奖杯, 央行宣布新货币政策以遏制通货膨胀趋势, 三星推出新款可折叠手机挑战市场竞争格局, 市长候选人承诺制定全面计划解决无家可归危机描述: 包含5个文档,主要涉及美联储暗示下季度可能实施降息政策与足球队在戏剧性点球大战后赢得冠军奖杯。示例文档:美联储暗示下季度可能实施降息政策;足球队在戏剧性点球大战后赢得冠军奖杯;央行宣布新货币政策以遏制通货膨胀趋势文档列表: [5] 美联储暗示下季度可能实施降息政策 [7] 足球队在戏剧性点球大战后赢得冠军奖杯 [10] 央行宣布新货币政策以遏制通货膨胀趋势 [13] 三星推出新款可折叠手机,挑战市场竞争格局 [17] 市长候选人承诺制定全面计划解决无家可归危机簇内平均相似度: 0.083------------------------------------------------------------===================================================================簇分类统计===================================================================文档总数: 20簇 0 (股市在经济复苏中创历史新高投资者信心大增与地方选举结果公布现任政党成功保持多数席位): 9 文档 (45.0%)簇 1 (科学家在亚马逊雨林发现数十个新物种与全球气候峰会达成历史性碳排放减少协议): 3 文档 (15.0%)簇 2 (新研究显示地中海饮食对心脏健康的显著益处与癌症治疗领域突破性进展在临床试验中显示良好效果): 3 文档 (15.0%)簇 3 (美联储暗示下季度可能实施降息政策与足球队在戏剧性点球大战后赢得冠军奖杯): 5 文档 (25.0%)

===================================================================查询处理示例===================================================================
查询: '科技公司发布了什么新产品?'
查询最相关的是簇 0 (股市在经济复苏中创历史新高投资者信心大增与地方选举结果公布现任政党成功保持多数席位), 相似度: 0.424从簇 0 (股市在经济复苏中创历史新高投资者信心大增与地方选举结果公布现任政党成功保持多数席位) 中找到 2 个相关文档: [文档 3, 相似度: 0.439]: 科技巨头发布最新智能手机,搭载先进AI摄影功能 [文档 9, 相似度: 0.346]: 苹果公司发布新一代iPhone,相机系统全面升级
查询: '健康医学方面有什么新发现?'
查询最相关的是簇 2 (新研究显示地中海饮食对心脏健康的显著益处与癌症治疗领域突破性进展在临床试验中显示良好效果), 相似度: 0.385从簇 2 (新研究显示地中海饮食对心脏健康的显著益处与癌症治疗领域突破性进展在临床试验中显示良好效果) 中找到 2 个相关文档: [文档 16, 相似度: 0.454]: 癌症治疗领域突破性进展在临床试验中显示良好效果 [文档 1, 相似度: 0.321]: 新研究显示地中海饮食对心脏健康的显著益处
查询: '经济政策有什么变化?'
查询最相关的是簇 3 (美联储暗示下季度可能实施降息政策与足球队在戏剧性点球大战后赢得冠军奖杯), 相似度: 0.335从簇 3 (美联储暗示下季度可能实施降息政策与足球队在戏剧性点球大战后赢得冠军奖杯) 中找到 2 个相关文档: [文档 5, 相似度: 0.354]: 美联储暗示下季度可能实施降息政策 [文档 10, 相似度: 0.315]: 央行宣布新货币政策以遏制通货膨胀趋势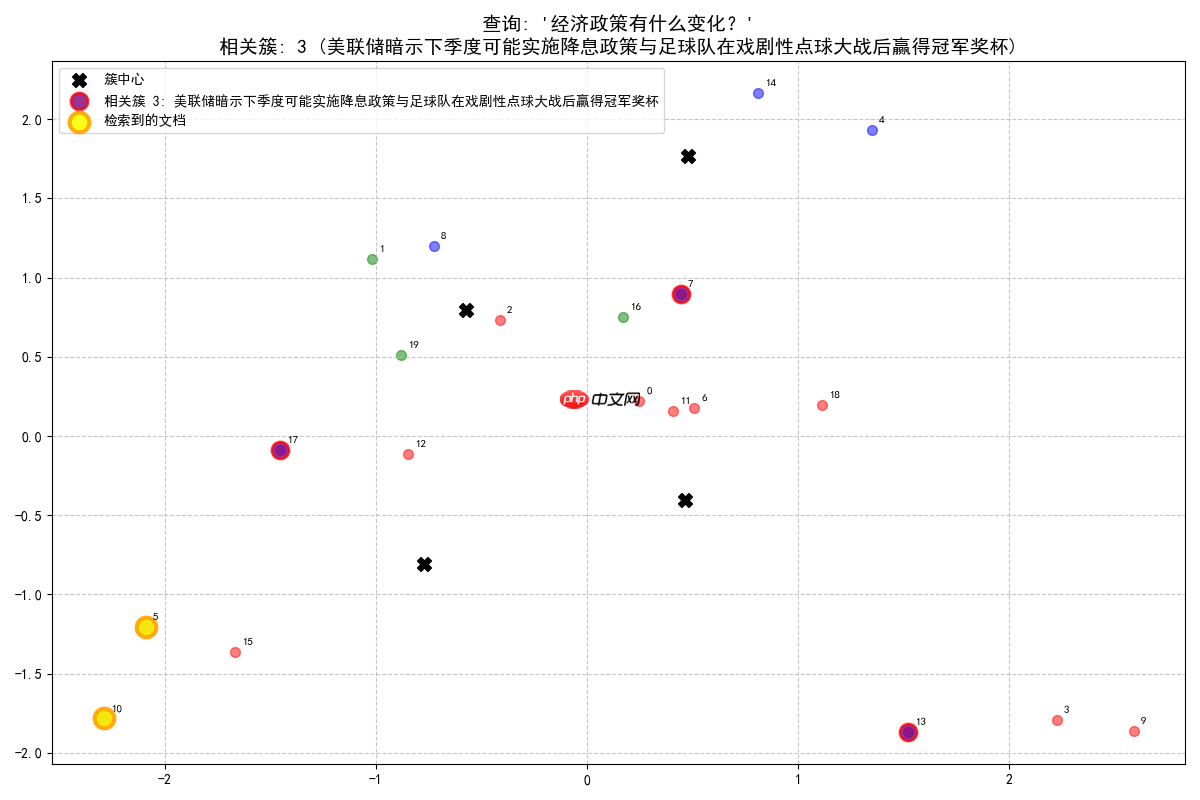
查询: '环境保护有哪些进展?'
查询最相关的是簇 1 (科学家在亚马逊雨林发现数十个新物种与全球气候峰会达成历史性碳排放减少协议), 相似度: 0.461从簇 1 (科学家在亚马逊雨林发现数十个新物种与全球气候峰会达成历史性碳排放减少协议) 中找到 2 个相关文档: [文档 8, 相似度: 0.468]: 全球气候峰会达成历史性碳排放减少协议 [文档 14, 相似度: 0.259]: 当地公园发现稀有鸟类物种,观鸟爱好者蜂拥而至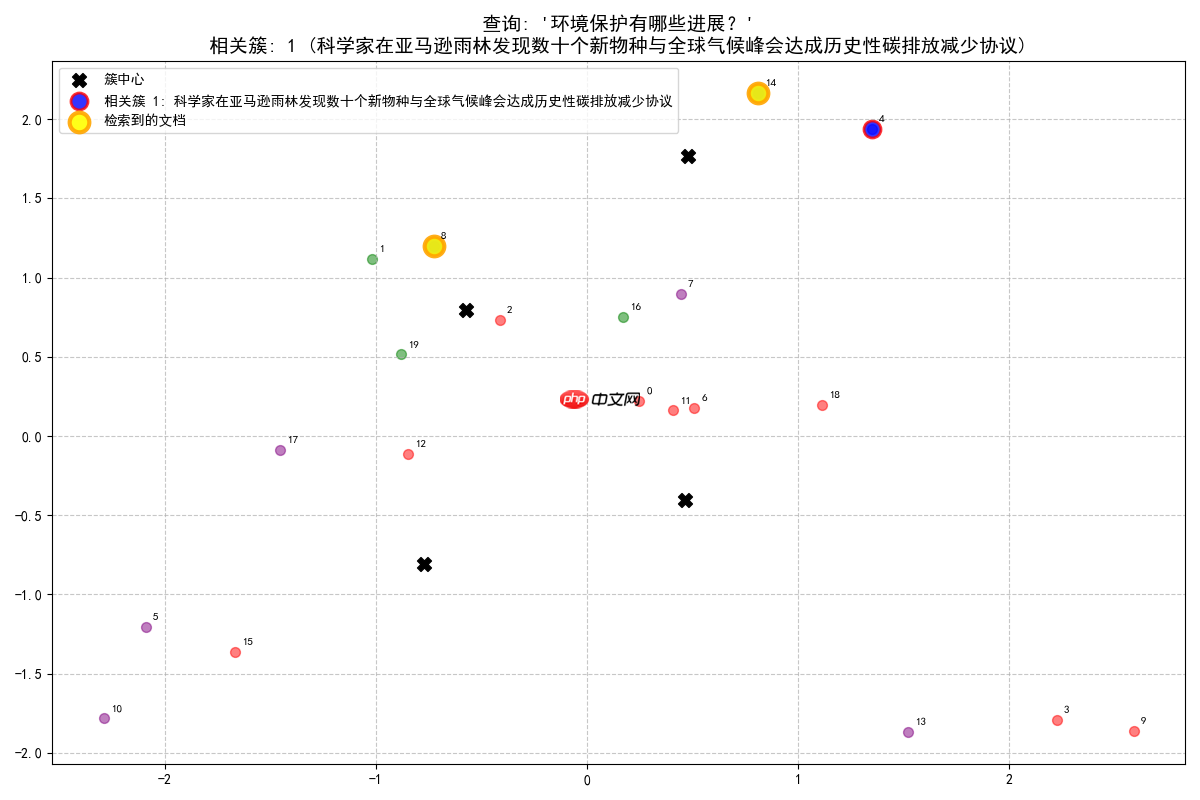
KMeans++与RAG系统的融合技术主要通过知识库多分区构建与检索结果优化两大场景实现性能提升,其核心逻辑是利用聚类算法的语义分组能力优化信息组织与检索流程,解决传统RAG系统中存在的效率瓶颈与质量偏差问题。
KMeans++与RAG系统的创新性结合,构建了一个高效、智能的文档处理与信息检索系统。通过将传统机器学习算法与现代大语言模型相结合,我们实现了从海量文档中自动发现知识结构并提供精准问答的能力。
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.animation import FuncAnimationfrom matplotlib import cmimport matplotlib.colors as mcolorsimport osimport imageio # 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = False # 创建输出目录if not os.path.exists('kmeans_frames'): os.makedirs('kmeans_frames') # 生成示例数据np.random.seed(42)n_samples = 100n_clusters = 4 # 生成四个高斯分布的数据点X1 = np.random.normal([2, 2], 0.5, [n_samples//4, 2])X2 = np.random.normal([-2, 2], 0.5, [n_samples//4, 2])X3 = np.random.normal([-2, -2], 0.5, [n_samples//4, 2])X4 = np.random.normal([2, -2], 0.5, [n_samples//4, 2])X = np.vstack([X1, X2, X3, X4]) # 初始化图形fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))fig.suptitle('K-Means++ 算法原理动态演示', fontsize=16) # 左图:K-Means++ 初始化过程ax1.set_xlim(-4, 4)ax1.set_ylim(-4, 4)ax1.set_title('K-Means++ 初始化过程')ax1.grid(True, linestyle='--', alpha=0.7) # 右图:K-Means 聚类过程ax2.set_xlim(-4, 4)ax2.set_ylim(-4, 4)ax2.set_title('K-Means 聚类过程')ax2.grid(True, linestyle='--', alpha=0.7) # 绘制初始数据点scatter1 = ax1.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7)scatter2 = ax2.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7) # 初始化变量centers = []probabilities = np.ones(len(X)) / len(X) # 初始概率均匀分布current_center_idx = Nonedistance_text = ax1.text(0.02, 0.98, "", transform=ax1.transAxes, fontsize=10, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))info_text = ax2.text(0.02, 0.98, "", transform=ax2.transAxes, fontsize=10, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8)) # 颜色映射colors = list(mcolors.TABLEAU_COLORS.values())cluster_colors = colors[:n_clusters] # 为每个簇分配一个颜色 # 存储中心点轨迹center_trajectories = [[] for _ in range(n_clusters)] # K-Means 聚类变量labels = Noneiteration = 0max_iterations = 10 # 存储所有帧frames = [] def init(): """初始化动画""" scatter1.set_offsets(X) scatter2.set_offsets(X) distance_text.set_text("") info_text.set_text("准备开始 K-Means++ 初始化...") return scatter1, scatter2, distance_text, info_text def kmeans_plus_plus_init_step(i): """K-Means++ 初始化步骤""" global centers, current_center_idx, probabilities if i == 0: # 第一步:随机选择第一个中心点 first_idx = np.random.randint(len(X)) centers.append(X[first_idx].copy()) current_center_idx = first_idx # 记录中心点轨迹 center_trajectories[0].append(centers[0].copy()) # 更新显示 scatter1.set_offsets(X) scatter1.set_facecolors(['lightgray'] * len(X)) face_colors = ['red' if j == first_idx else 'lightgray' for j in range(len(X))] scatter1.set_facecolors(face_colors) # 绘制中心点 ax1.scatter(centers[0][0], centers[0][1], c='red', s=200, marker='X', edgecolors='black') distance_text.set_text("步骤 1/4: 随机选择第一个中心点(红色点)") info_text.set_text("K-Means++ 初始化开始随机选择第一个中心点") elif i == 1 and len(centers) < n_clusters: # 第二步:计算距离并显示 distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X]) probabilities = distances / np.sum(distances) # 更新显示 scatter1.set_offsets(X) # 使用颜色深浅表示概率大小 norm = plt.Normalize(probabilities.min(), probabilities.max()) prob_colors = cm.Blues(norm(probabilities)) scatter1.set_facecolors(prob_colors) # 绘制已选中心点 for idx, center in enumerate(centers): ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black') distance_text.set_text("步骤 2/4: 计算每个点到最近中心点的距离平方颜色越深表示被选中的概率越大") info_text.set_text("计算每个点到最近中心点的距离平方作为选择下一个中心点的概率依据") elif i == 2 and len(centers) < n_clusters: # 第三步:选择下一个中心点 distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X]) probabilities = distances / np.sum(distances) next_idx = np.random.choice(len(X), p=probabilities) centers.append(X[next_idx].copy()) current_center_idx = next_idx # 记录中心点轨迹 center_trajectories[len(centers)-1].append(centers[-1].copy()) # 更新显示 scatter1.set_offsets(X) scatter1.set_facecolors(['lightgray'] * len(X)) # 绘制所有中心点 for idx, center in enumerate(centers): ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black') # 高亮显示当前选择的中心点 ax1.scatter(centers[-1][0], centers[-1][1], c='yellow', s=250, marker='X', edgecolors='red', linewidth=2) distance_text.set_text(f"步骤 3/4: 根据概率选择下一个中心点(黄色高亮点)") info_text.set_text(f"根据概率分布选择下一个中心点当前已选择 {len(centers)}/{n_clusters} 个中心点") elif i >= 3 and len(centers) < n_clusters: # 重复步骤2-3直到选择足够的中心点 if (i - 3) % 3 == 0: # 计算距离 distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X]) probabilities = distances / np.sum(distances) # 更新显示 scatter1.set_offsets(X) norm = plt.Normalize(probabilities.min(), probabilities.max()) prob_colors = cm.Blues(norm(probabilities)) scatter1.set_facecolors(prob_colors) # 绘制已选中心点 for idx, center in enumerate(centers): ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black') step = len(centers) + 1 distance_text.set_text(f"步骤 {step*3-2}/12: 计算每个点到最近中心点的距离平方颜色越深表示被选中的概率越大") info_text.set_text(f"计算每个点到最近中心点的距离平方当前已选择 {len(centers)}/{n_clusters} 个中心点") elif (i - 3) % 3 == 1: # 选择中心点 distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X]) probabilities = distances / np.sum(distances) next_idx = np.random.choice(len(X), p=probabilities) centers.append(X[next_idx].copy()) current_center_idx = next_idx # 记录中心点轨迹 center_trajectories[len(centers)-1].append(centers[-1].copy()) # 更新显示 scatter1.set_offsets(X) scatter1.set_facecolors(['lightgray'] * len(X)) # 绘制所有中心点 for idx, center in enumerate(centers): ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black') # 高亮显示当前选择的中心点 ax1.scatter(centers[-1][0], centers[-1][1], c='yellow', s=250, marker='X', edgecolors='red', linewidth=2) step = len(centers) distance_text.set_text(f"步骤 {step*3-1}/12: 根据概率选择下一个中心点(黄色高亮点)") info_text.set_text(f"根据概率分布选择下一个中心点当前已选择 {len(centers)}/{n_clusters} 个中心点") else: # 显示概率分布 distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X]) probabilities = distances / np.sum(distances) # 更新显示 scatter1.set_offsets(X) norm = plt.Normalize(probabilities.min(), probabilities.max()) prob_colors = cm.Blues(norm(probabilities)) scatter1.set_facecolors(prob_colors) # 绘制已选中心点 for idx, center in enumerate(centers): ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black') step = len(centers) distance_text.set_text(f"步骤 {step*3}/12: 更新概率分布颜色越深表示被选中的概率越大") info_text.set_text(f"更新概率分布,准备选择下一个中心点当前已选择 {len(centers)}/{n_clusters} 个中心点") elif len(centers) == n_clusters: # 初始化完成,开始 K-Means 聚类 distance_text.set_text("K-Means++ 初始化完成!已选择所有初始中心点") info_text.set_text("K-Means++ 初始化完成!开始 K-Means 聚类过程") # 绘制最终的中心点 scatter1.set_offsets(X) scatter1.set_facecolors(['lightgray'] * len(X)) for idx, center in enumerate(centers): ax1.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black') # 在右图绘制初始中心点 scatter2.set_offsets(X) scatter2.set_facecolors(['lightgray'] * len(X)) for idx, center in enumerate(centers): ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black', label=f'中心点 {idx+1}') ax2.legend(loc='upper right') return scatter1, scatter2, distance_text, info_text def kmeans_step(i): """K-Means 聚类步骤""" global centers, labels, iteration, cluster_colors, center_trajectories if len(centers) < n_clusters: return scatter1, scatter2, distance_text, info_text # 确保centers是NumPy数组 centers_array = np.array(centers) # 第一次迭代 if iteration == 0: # 分配步骤:将每个点分配到最近的中心点 # 修复:使用正确的数组索引 distances = np.array([np.linalg.norm(X - center, axis=1) for center in centers_array]) labels = np.argmin(distances, axis=0) # 更新显示 scatter2.set_offsets(X) scatter2.set_facecolors([cluster_colors[label] for label in labels]) # 绘制中心点 for idx, center in enumerate(centers_array): ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black') # 记录中心点轨迹 center_trajectories[idx].append(center.copy()) info_text.set_text(f"迭代 {iteration+1}: 分配步骤将每个点分配到最近的中心点") iteration += 1 elif iteration < max_iterations: if iteration % 2 == 1: # 更新步骤:重新计算中心点 new_centers = np.array([X[labels == j].mean(axis=0) if np.sum(labels == j) > 0 else centers_array[j] for j in range(n_clusters)]) # 绘制中心点移动轨迹 for j in range(n_clusters): ax2.plot([centers_array[j][0], new_centers[j][0]], [centers_array[j][1], new_centers[j][1]], 'k--', alpha=0.5) # 记录中心点轨迹 center_trajectories[j].append(new_centers[j].copy()) centers = new_centers.tolist() # 转换为列表以保持一致性 # 更新显示 scatter2.set_offsets(X) scatter2.set_facecolors([cluster_colors[label] for label in labels]) # 绘制中心点 for idx, center in enumerate(new_centers): ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black') info_text.set_text(f"迭代 {iteration+1}: 更新步骤重新计算每个簇的中心点位置") iteration += 1 else: # 分配步骤:重新分配点 # 确保centers是NumPy数组 centers_array = np.array(centers) # 分配步骤:将每个点分配到最近的中心点 distances = np.array([np.linalg.norm(X - center, axis=1) for center in centers_array]) labels = np.argmin(distances, axis=0) # 更新显示 scatter2.set_offsets(X) scatter2.set_facecolors([cluster_colors[label] for label in labels]) # 绘制中心点 for idx, center in enumerate(centers_array): ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black') info_text.set_text(f"迭代 {iteration+1}: 分配步骤根据新中心点重新分配点") iteration += 1 else: info_text.set_text("K-Means 算法已收敛!聚类完成") # 绘制中心点轨迹 for j in range(n_clusters): if len(center_trajectories[j]) > 1: trajectory = np.array(center_trajectories[j]) ax2.plot(trajectory[:, 0], trajectory[:, 1], '--', color=cluster_colors[j], alpha=0.7) return scatter1, scatter2, distance_text, info_text def update(i): """更新函数""" if i < 12: # 前12帧用于K-Means++初始化 return kmeans_plus_plus_init_step(i) else: # 后续帧用于K-Means聚类 return kmeans_step(i - 12) # 创建动画并保存每一帧for i in range(25): # 清除右图中的轨迹线,但保留中心点 if i >= 12: # 清除之前的轨迹线 for line in ax2.get_lines(): line.remove() # 更新动画 update(i) # 保存当前帧 frame_path = f'kmeans_frames/frame_{i:02d}.png' plt.savefig(frame_path, dpi=100, bbox_inches='tight') frames.append(imageio.imread(frame_path)) print(f'已保存第 {i+1}/25 帧') plt.tight_layout()plt.show()import numpy as npfrom sentence_transformers import SentenceTransformerfrom sklearn.decomposition import PCAimport matplotlib.pyplot as pltimport matplotlib.patches as mpatchesimport warningswarnings.filterwarnings('ignore')import refrom collections import Counter # 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = False # 1. 准备示例数据documents = [ "股市在经济复苏中创历史新高,投资者信心大增", "新研究显示地中海饮食对心脏健康的显著益处", "地方选举结果公布,现任政党成功保持多数席位", "科技巨头发布最新智能手机,搭载先进AI摄影功能", "科学家在亚马逊雨林发现数十个新物种", "美联储暗示下季度可能实施降息政策", "COVID-19疫苗加强针现已向所有成年人开放接种", "足球队在戏剧性点球大战后赢得冠军奖杯", "全球气候峰会达成历史性碳排放减少协议", "苹果公司发布新一代iPhone,相机系统全面升级", "央行宣布新货币政策以遏制通货膨胀趋势", "最新研究将空气污染与阿尔茨海默病风险增加联系起来", "市议会批准50亿预算用于新建公共交通系统", "三星推出新款可折叠手机,挑战市场竞争格局", "当地公园发现稀有鸟类物种,观鸟爱好者蜂拥而至", "财政部长发表对数字货币未来发展的评论", "癌症治疗领域突破性进展在临床试验中显示良好效果", "市长候选人承诺制定全面计划解决无家可归危机", "谷歌发布核心搜索算法重大更新", "飓风逼近东部海岸,居民被敦促立即撤离"] # 2. 文档向量化print("正在加载嵌入模型...")embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')print("正在生成文档嵌入向量...")document_embeddings = embedder.encode(documents) # 3. 自定义 K-Means++ 实现def kmeans_plus_plus(X, n_clusters, max_iter=100, tol=1e-4): """自定义 K-Means++ 实现""" n_samples, n_features = X.shape # K-Means++ 初始化 centers = np.zeros((n_clusters, n_features)) # 随机选择第一个中心点 first_idx = np.random.randint(n_samples) centers[0] = X[first_idx] # 选择剩余的中心点 for i in range(1, n_clusters): # 计算每个样本到最近中心点的距离平方 distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers[:i]]) for x in X]) # 按概率选择下一个中心点 probabilities = distances / np.sum(distances) next_idx = np.random.choice(n_samples, p=probabilities) centers[i] = X[next_idx] # 迭代优化 for iteration in range(max_iter): # 分配样本到最近的中心点 labels = np.argmin(np.linalg.norm(X[:, np.newaxis] - centers, axis=2), axis=1) # 计算新的中心点 new_centers = np.zeros((n_clusters, n_features)) for i in range(n_clusters): cluster_points = X[labels == i] if len(cluster_points) > 0: new_centers[i] = np.mean(cluster_points, axis=0) else: # 如果簇为空,重新初始化 new_centers[i] = X[np.random.randint(n_samples)] # 检查收敛 if np.all(np.linalg.norm(new_centers - centers, axis=1) < tol): break centers = new_centers return labels, centers # 使用自定义 K-Means++ 进行聚类print("正在进行文档聚类...")n_clusters = 4cluster_labels, cluster_centers = kmeans_plus_plus(document_embeddings, n_clusters) # 4. 生成簇名称和分类信息def extract_keywords(texts, top_n=5): """从文本中提取关键词""" # 中文文本简单分词(按常见分隔符分割) words = [] for text in texts: # 移除标点符号 text_clean = re.sub(r'[^\w\s]', '', text) # 按空格和常见分隔符分割 text_words = re.split(r'[\s、,。;:!?]+', text_clean) words.extend([w for w in text_words if len(w) > 1]) # 只保留长度大于1的词 # 计算词频 word_counts = Counter(words) return [word for word, count in word_counts.most_common(top_n)] def generate_cluster_name(keywords): """根据关键词生成簇名称""" if not keywords: return "未命名簇" # 简单规则:取前两个关键词组合 if len(keywords) >= 2: return f"{keywords[0]}与{keywords[1]}" else: return f"{keywords[0]}相关" # 为每个簇生成名称和描述cluster_info = {}for cluster_id in range(n_clusters): cluster_docs = [documents[i] for i, label in enumerate(cluster_labels) if label == cluster_id] # 提取关键词 keywords = extract_keywords(cluster_docs) # 生成簇名称 cluster_name = generate_cluster_name(keywords) # 生成簇描述 if len(cluster_docs) > 0: # 取前几个文档作为示例 sample_docs = cluster_docs[:min(3, len(cluster_docs))] description = f"包含{len(cluster_docs)}个文档,主要涉及{cluster_name}。示例文档:{';'.join(sample_docs)}" else: description = "空簇" cluster_info[cluster_id] = { 'name': cluster_name, 'keywords': keywords, 'description': description, 'doc_count': len(cluster_docs), 'doc_indices': [i for i, label in enumerate(cluster_labels) if label == cluster_id] } # 5. 可视化聚类结果print("正在生成可视化图表...")pca = PCA(n_components=2)reduced_embeddings = pca.fit_transform(document_embeddings)reduced_centers = pca.transform(cluster_centers) # 创建颜色映射colors = ['red', 'blue', 'green', 'purple', 'orange', 'brown', 'pink', 'gray']cluster_colors = [colors[label % len(colors)] for label in cluster_labels] plt.figure(figsize=(16, 12))scatter = plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1], c=cluster_colors, s=100, alpha=0.7) # 标记簇中心plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1], c='black', marker='X', s=200, label='簇中心') # 为每个点添加文档索引for i, (x, y) in enumerate(reduced_embeddings): plt.annotate(str(i), (x, y), xytext=(5, 5), textcoords='offset points', fontsize=8) # 添加簇名称标注for cluster_id in range(n_clusters): center_x, center_y = reduced_centers[cluster_id] plt.annotate( f"簇 {cluster_id}: {cluster_info[cluster_id]['name']}", xy=(center_x, center_y), xytext=(center_x + 0.5, center_y + 0.5), fontsize=12, weight='bold', color=colors[cluster_id % len(colors)], bbox=dict(boxstyle="round,pad=0.3", facecolor="lightyellow", alpha=0.7), arrowprops=dict(arrowstyle="->", color='black', lw=1.5) ) # 添加图例legend_patches = [mpatches.Patch(color=colors[i], label=f'簇 {i}: {cluster_info[i]["name"]} ({cluster_info[i]["doc_count"]}文档)') for i in range(n_clusters)]plt.legend(handles=legend_patches, loc='center left', bbox_to_anchor=(1, 0.5)) plt.title('文档聚类可视化 (K-Means++)数字代表文档索引', fontsize=16)plt.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()plt.savefig('kmeans_clustering.png', dpi=300, bbox_inches='tight')plt.show() # 6. 打印详细的聚类结果print("=" * 80)print("文档聚类详细结果")print("=" * 80) for cluster_id in range(n_clusters): info = cluster_info[cluster_id] print(f"--- 簇 {cluster_id}: {info['name']} (包含 {info['doc_count']} 个文档) ---") print(f"关键词: {', '.join(info['keywords'])}") print(f"描述: {info['description']}") print("文档列表:") for doc_idx in info['doc_indices']: print(f" [{doc_idx}] {documents[doc_idx]}") # 计算簇内文档的平均相似度 cluster_embeddings = document_embeddings[info['doc_indices']] if len(cluster_embeddings) > 1: # 计算簇内所有文档两两之间的余弦相似度 similarities = [] for i in range(len(cluster_embeddings)): for j in range(i+1, len(cluster_embeddings)): sim = np.dot(cluster_embeddings[i], cluster_embeddings[j]) / ( np.linalg.norm(cluster_embeddings[i]) * np.linalg.norm(cluster_embeddings[j])) similarities.append(sim) avg_similarity = np.mean(similarities) if similarities else 0 print(f"簇内平均相似度: {avg_similarity:.3f}") print("-" * 60) # 7. 生成簇分类统计print("" + "=" * 80)print("簇分类统计")print("=" * 80) # 统计每个簇的大小cluster_sizes = [cluster_info[i]['doc_count'] for i in range(n_clusters)]total_docs = len(documents) print(f"文档总数: {total_docs}")for cluster_id in range(n_clusters): percentage = (cluster_info[cluster_id]['doc_count'] / total_docs) * 100 print(f"簇 {cluster_id} ({cluster_info[cluster_id]['name']}): {cluster_info[cluster_id]['doc_count']} 文档 ({percentage:.1f}%)") # 8. 模拟查询处理def find_relevant_cluster(query_embedding, cluster_centers): """找到与查询最相关的簇""" # 计算查询与每个簇中心的余弦相似度 similarities = [] for center in cluster_centers: similarity = np.dot(query_embedding, center) / (np.linalg.norm(query_embedding) * np.linalg.norm(center)) similarities.append(similarity) return np.argmax(similarities), similarities def retrieve_documents(query, top_k=3): """检索与查询相关的文档""" # 将查询转换为向量 query_embedding = embedder.encode([query])[0] # 找到最相关的簇 relevant_cluster, cluster_similarities = find_relevant_cluster(query_embedding, cluster_centers) cluster_name = cluster_info[relevant_cluster]['name'] print(f"查询最相关的是簇 {relevant_cluster} ({cluster_name}), 相似度: {cluster_similarities[relevant_cluster]:.3f}") # 获取簇内的所有文档 cluster_doc_indices = cluster_info[relevant_cluster]['doc_indices'] cluster_embeddings = document_embeddings[cluster_doc_indices] # 计算查询与簇内文档的相似度 similarities = [] for emb in cluster_embeddings: similarity = np.dot(query_embedding, emb) / (np.linalg.norm(query_embedding) * np.linalg.norm(emb)) similarities.append(similarity) similarities = np.array(similarities) top_indices = np.argsort(similarities)[-top_k:][::-1] # 获取最相关的文档 results = [] for idx in top_indices: doc_idx = cluster_doc_indices[idx] results.append((doc_idx, documents[doc_idx], similarities[idx])) return results, relevant_cluster # 示例查询queries = [ "科技公司发布了什么新产品?", "健康医学方面有什么新发现?", "经济政策有什么变化?", "环境保护有哪些进展?"] print("" + "=" * 80)print("查询处理示例")print("=" * 80) for query in queries: print(f"查询: '{query}'") results, cluster_id = retrieve_documents(query, top_k=2) cluster_name = cluster_info[cluster_id]['name'] print(f"从簇 {cluster_id} ({cluster_name}) 中找到 {len(results)} 个相关文档:") for doc_idx, doc_text, similarity in results: print(f" [文档 {doc_idx}, 相似度: {similarity:.3f}]: {doc_text}") # 可视化查询结果 plt.figure(figsize=(12, 8)) # 绘制所有文档点 for i, (x, y) in enumerate(reduced_embeddings): plt.scatter(x, y, c=cluster_colors[i], s=50, alpha=0.5) plt.annotate(str(i), (x, y), xytext=(5, 5), textcoords='offset points', fontsize=8) # 标记簇中心 plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1], c='black', marker='X', s=100, label='簇中心') # 高亮显示相关簇 relevant_points = reduced_embeddings[cluster_labels == cluster_id] plt.scatter(relevant_points[:, 0], relevant_points[:, 1], c=colors[cluster_id % len(colors)], s=150, alpha=0.8, edgecolors='red', linewidth=2, label=f'相关簇 {cluster_id}: {cluster_name}') # 高亮显示检索到的文档 retrieved_indices = [doc_idx for doc_idx, _, _ in results] retrieved_points = reduced_embeddings[retrieved_indices] plt.scatter(retrieved_points[:, 0], retrieved_points[:, 1], c='yellow', s=200, alpha=0.9, edgecolors='orange', linewidth=3, label='检索到的文档') plt.title(f"查询: '{query}'相关簇: {cluster_id} ({cluster_name})", fontsize=14) plt.legend() plt.grid(True, linestyle='--', alpha=0.7) plt.tight_layout() plt.savefig(f'query_result_{queries.index(query)}.png', dpi=300, bbox_inches='tight') plt.show() print("=== 分析完成 ===")以上就是构建AI智能体:K-Means++与RAG的融合创新:智能聚类与检索增强生成的深度应用的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 793
793






















