
构建一个高效的知识库是打造智能ai应用的关键一步。dify平台提供了完整的知识库管理能力,从文档上传到向量化检索,每个环节都有精细的参数可供调整。本文基于dify实际操作界面,详细解析知识库构建的核心流程和关键参数配置,帮助开发者快速上手并优化检索效果。
文章适合已经部署好Dify环境、需要深入了解知识库配置细节的开发者。如果你正在为检索准确率低、文档分段不合理等问题困扰,这篇文章能给你提供具体的调优思路。
在开始构建知识库之前,需要确保以下组件已经就绪:
Dify平台:建议使用最新版本,本文基于Dify云端版本演示向量数据库:Weaviate需要1.27.0或更高版本(低于此版本会出现兼容性警告)Embedding模型:至少配置一个文本嵌入模型,如text-embedding-3-largeRerank模型(可选):用于二次排序提升检索精度☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在Dify的设置面板中,模型供应商管理是构建知识库的第一步。系统支持多种模型类型的配置,每种类型在知识库中扮演不同角色。
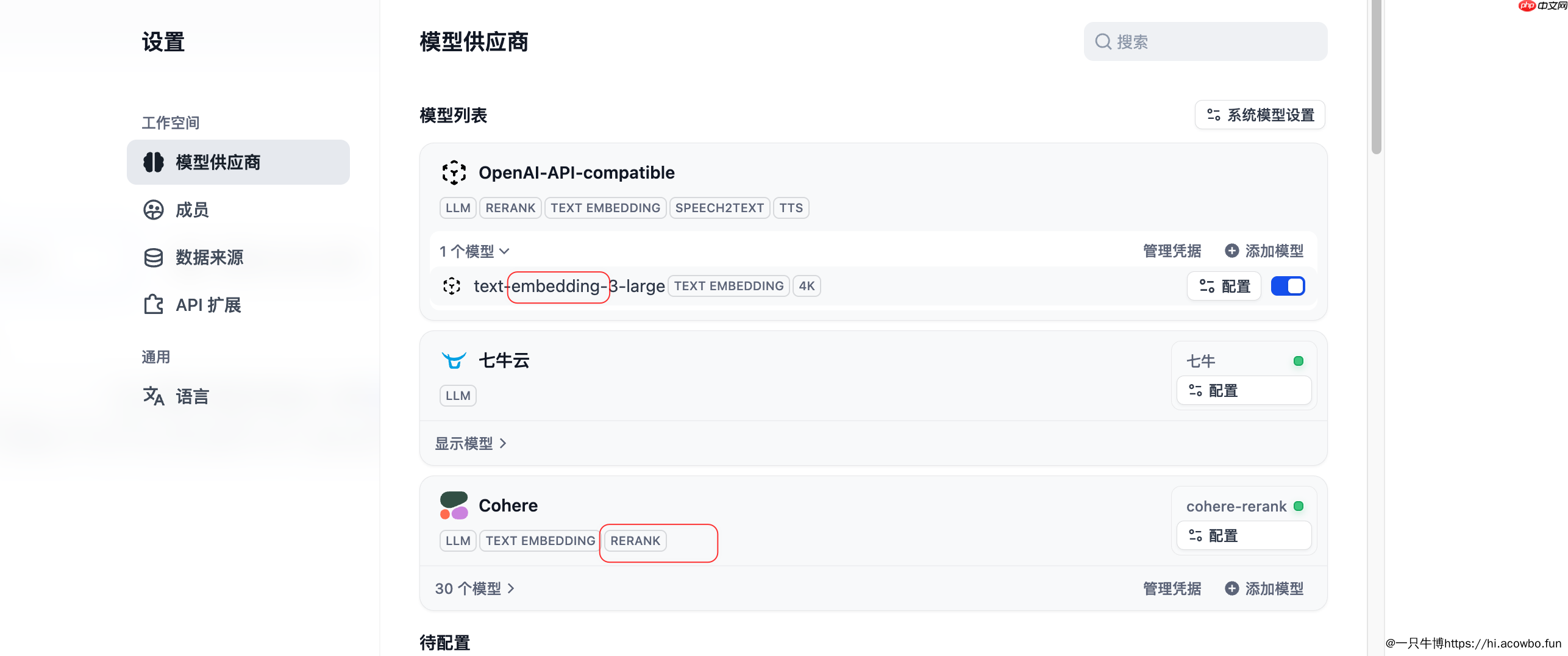
从界面可以看到,Dify将模型分为五大类:LLM(大语言模型)、RERANK(重排序模型)、TEXT EMBEDDING(文本嵌入模型)、SPEECH2TEXT(语音转文字)和TTS(文字转语音)。对于知识库构建而言,TEXT EMBEDDING和RERANK是最核心的两个配置项。
配置Embedding模型时需要特别注意模型的维度参数。以text-embedding-3-large为例,它支持4K的上下文长度,能够处理较长的文本分段。不同模型的向量维度不同,一旦选定后更换模型需要重新索引所有文档,因此初期选型要慎重考虑。
模型类型 |
在知识库中的作用 |
配置优先级 |
|---|---|---|
TEXT EMBEDDING |
将文本转换为向量,是检索的基础 |
必须配置 |
RERANK |
对检索结果二次排序,提升准确性 |
强烈推荐 |
LLM |
基于检索结果生成回答 |
应用层使用 |
文档上传后,Dify会进入文本分段与清洗界面,这是整个知识库构建中参数最多、也最需要精细调整的环节。

Dify提供了三种分段模式,适用于不同的文档类型和检索场景:

通用分段是最常用的模式,文本被均匀切分成指定长度的块,检索和召回使用相同的分段。Q&A分段会使用AI自动从文档中提取问答对,特别适合已有的FAQ文档或客服知识库。父子分段是一种高级策略,使用较小的子块进行精确检索,但返回包含更多上下文的父块,兼顾了检索精度和上下文完整性。
分段设置界面提供了三个关键参数需要配置:
参数名称 |
默认值 |
说明 |
调优建议 |
|---|---|---|---|
分段标识符 |
优先按此标识切分文本 |
根据文档格式调整,如Markdown用## |
|
分段最大长度 |
1024 characters |
每个文本块的最大字符数 |
技术文档建议500-800,FAQ建议200-400 |
分段重叠长度 |
50 characters |
相邻分段的重叠区域 |
建议为最大长度的5-10% |
分段长度的设置需要在两个因素间取得平衡:过长的分段包含更多上下文但检索精度下降,过短的分段检索精确但可能丢失必要的上下文信息。

界面下方的预处理选项同样重要,Dify提供了两个默认开启的清洗规则:
替换掉连续的空格、换行符和制表符:去除文档中的多余空白,使文本更加紧凑删除所有URL和电子邮件地址:移除可能干扰语义理解的链接信息这些规则的开关需要根据实际业务场景决定。如果你的知识库需要保留URL作为引用来源,就需要关闭第二个选项。
索引方式的选择直接影响知识库的检索效果和运营成本。Dify提供了两种主要的索引方式:

高质量索引使用Embedding模型将每个数据块转换为向量,支持语义级别的检索。这种方式能够理解文本的含义,即使查询词与文档用词不同也能匹配到相关内容。缺点是需要消耗Embedding模型的tokens,有一定成本。
经济索引则通过LLM生成每个数据块的关键词(默认10个),使用倒排索引结构进行检索。这种方式不消耗任何tokens,但会以降低检索准确性为代价,更适合对成本敏感的大规模知识库场景。
从界面截图可以看到,推荐使用高质量索引配合混合检索策略,这种组合在实际应用中效果最为稳定。
检索设置决定了系统在回答问题时从知识库中召回多少相关内容。界面中显示的Top K参数是最核心的配置项:
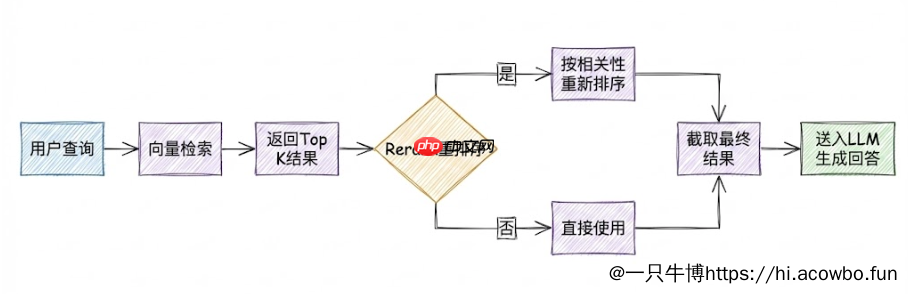
Top K值设置为3意味着每次检索返回相关性最高的3个文本块。这个值需要根据问题复杂度和文档特点调整:简单的事实性问题设置较小的K值即可,复杂的综合性问题则需要召回更多内容供LLM参考。
完成上述配置后,就可以开始上传文档了。Dify支持多种文档格式,包括TXT、MD、PDF、DOCX等常见类型。

上传完成后,界面会展示处理结果的摘要信息,包括分段模式、最大分段长度、文本预处理规则、索引方式和检索设置。这些信息帮助你确认配置是否符合预期。
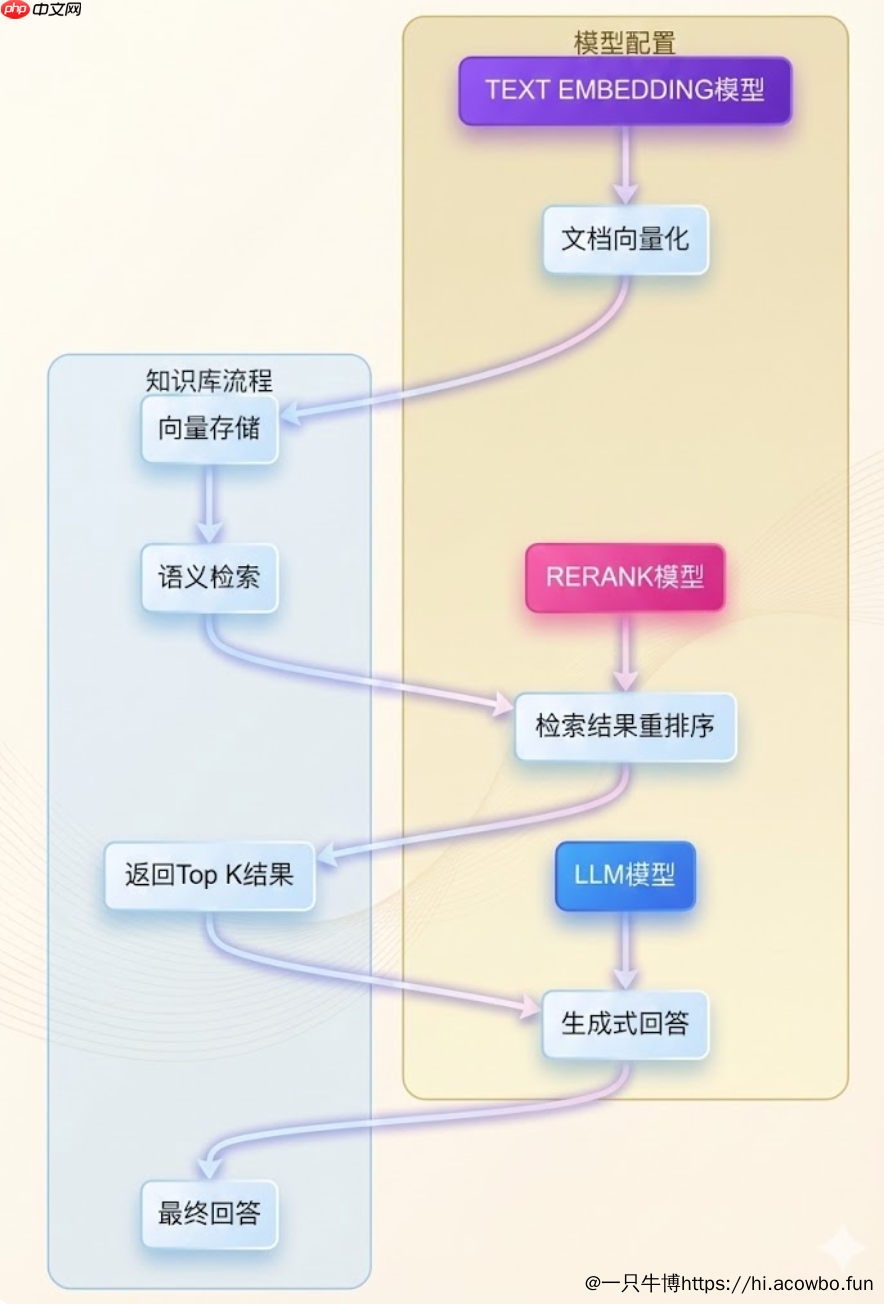
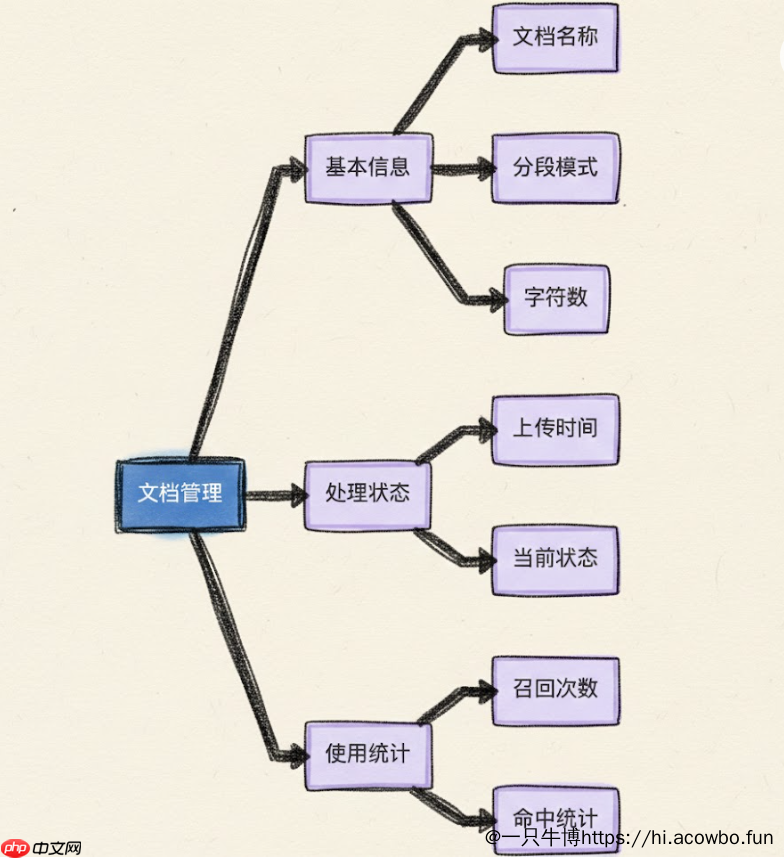
整个文档处理流程可以用下图表示:

如果在处理过程中遇到Weaviate版本警告(如截图中显示的"Weaviate version 1.19.0 is not supported"),需要将向量数据库升级到1.27.0或更高版本才能继续使用。
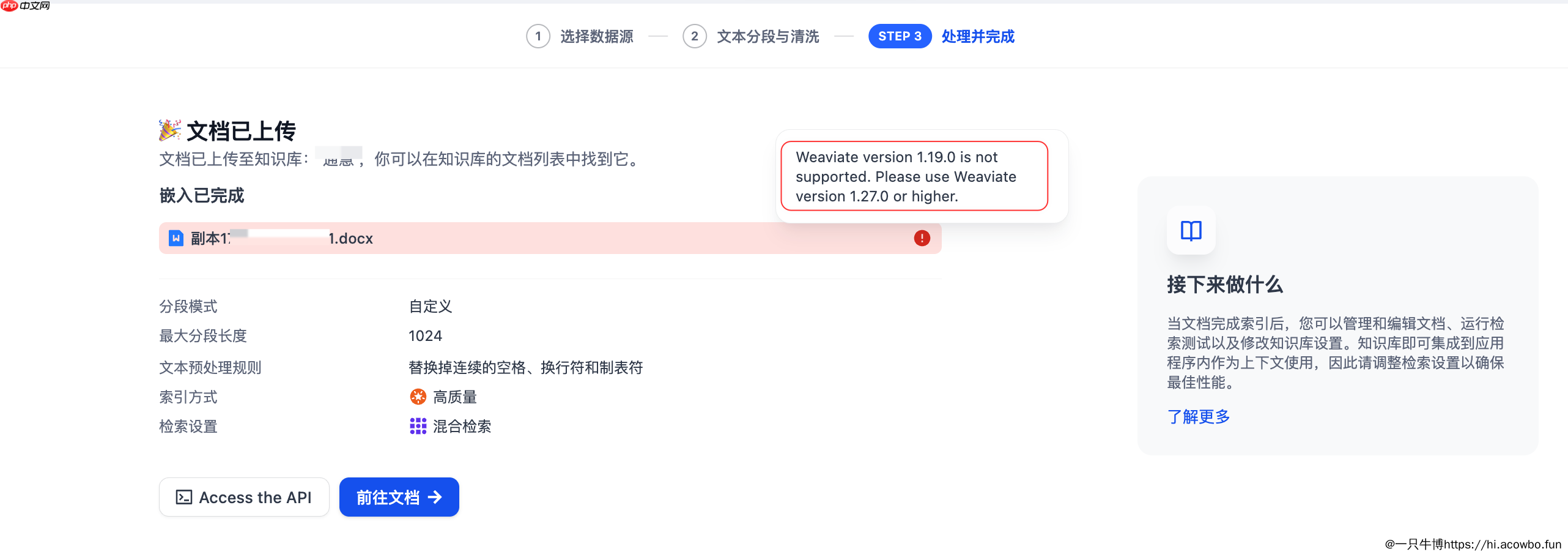
文档处理完成后,可以在知识库的文档列表中管理所有已上传的文件。
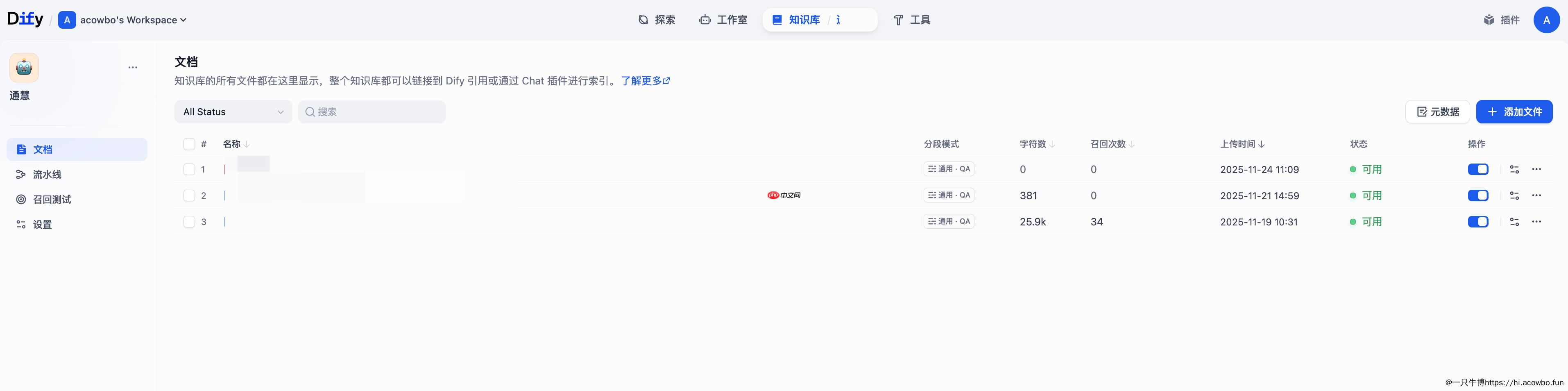
列表界面展示了每个文档的关键信息:
从截图可以看到,文档状态显示为"可用"表示已完成索引构建,可以被检索调用。召回次数是一个重要的运营指标,它记录了该文档被检索命中的次数,帮助你了解哪些文档被频繁使用、哪些可能需要优化或更新。
分段模式列显示了每个文档采用的分段策略,界面中可以看到"通用"和"QA"两种模式并存,说明Dify支持同一知识库中混合使用不同的分段策略,这在处理异构文档时非常实用。
对于不同类型的业务场景,参数配置策略也有所不同:
场景 |
分段长度 |
重叠长度 |
索引方式 |
Top K |
|---|---|---|---|---|
客服FAQ |
300 |
30 |
高质量 |
3 |
技术文档 |
800 |
80 |
高质量+混合 |
5 |
产品手册 |
500 |
50 |
高质量 |
4 |
法律合同 |
1000 |
100 |
高质量 |
6 |
Dify知识库的构建核心在于三个环节的精细配置:模型选择决定了向量化的质量基础,TEXT EMBEDDING模型的选型需要综合考虑维度、成本和业务场景;分段策略直接影响检索的颗粒度,通用分段适合大多数场景,而父子分段和Q&A分段则为特定文档类型提供了更优的处理方式;索引方式和检索参数的组合配置是最终检索效果的保障,高质量索引配合混合检索和Rerank重排序能够在大多数场景下获得最佳效果。实际运营中,应该持续关注召回次数等指标,根据用户查询的命中情况不断迭代优化参数配置,这是一个需要持续投入但回报显著的过程。
以上就是Dify 知识库构建实战指南的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 497
497





















