Transformer无疑是过去几年内机器学习领域最流行的模型。
自2017年在论文「Attention is All You Need」中提出之后,这个新的网络结构,刷爆了各大翻译任务,同时创造了多项新的记录。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
但Transformer在处理长字节序列时有个硬伤,就是算力损耗严重,而Meta的研究人员的最新成果则可以很好地解决这一缺陷。
他们推出了一种全新的模型架构,能跨多种格式生成超过100万个token,并超越GPT-4等模型背后的现有 Transformer架构的功能。
这个模型被称为「兆字节」(Megabyte),是一种多尺度解码器架构(Multi-scale Decoder Architecture),可以对超过一百万字节的序列进行端到端可微分建模。

论文链接:https://arxiv.org/abs/2305.07185

Megabyte为什么比Transformer强,就得先看看Transformer的不足之处在哪。
Transformer的不足
迄今为止几类高性能的生成式AI模型,如OpenAI的GPT-4、Google的Bard,都是基于Transformer架构的模型。
但Meta的研究团队认为,流行的Transformer架构可能正达到其阈值,其中主要理由是Transformer设计中固有的两个重要缺陷:
- 随着输入和输出字节长度的增加,自注意力的成本也迅速增加,如输入的音乐、图像或视频文件通常包含数兆字节,然而大型解码器 (LLM)通常只使用几千个上下文标记
- 前馈网络通过一系列数学运算和转换帮助语言模型理解和处理单词,但在每个位置的基础上难以实现可扩展性,这些网络独立地对字符组或位置进行操作,从而导致大量的计算开销
Megabyte强在哪
相比Transformer,Megabyte模型展示了一种独特的不同架构,将输入和输出序列划分为patch而不是单个token。
如下图,在每个patch中,本地AI模型生成结果,而全局模型管理和协调所有patch的最终输出。
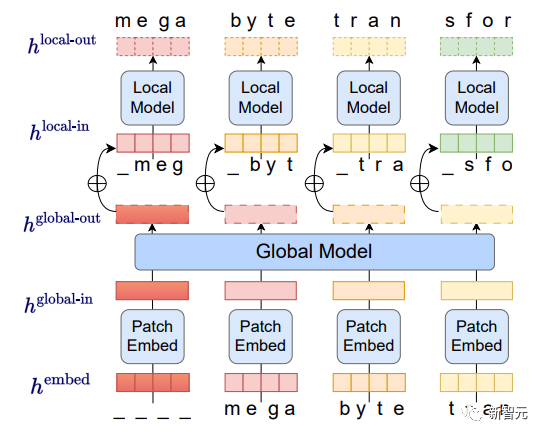
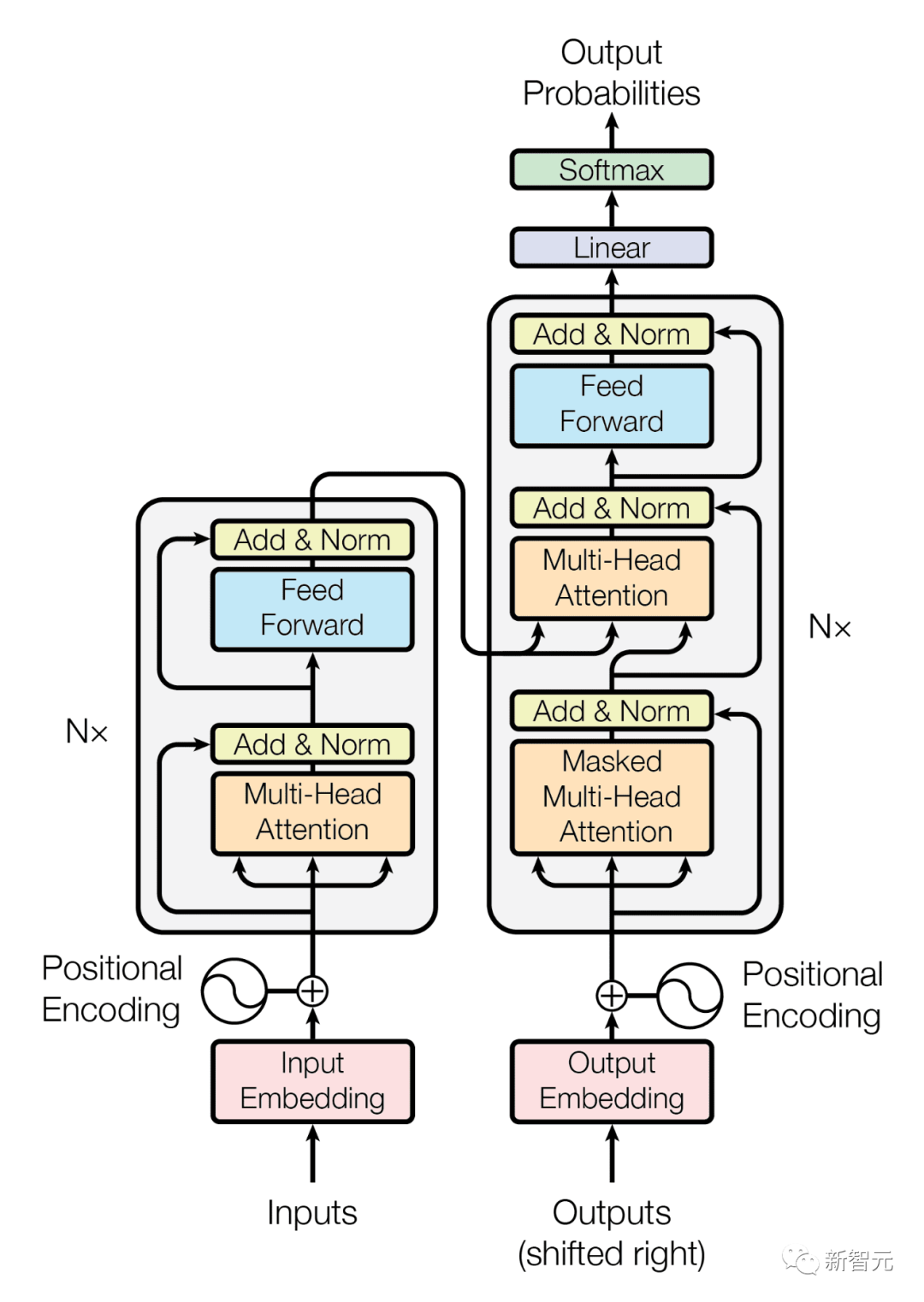
首先,字节序列被分割成固定大小的patch,大致类似于token,这个模型由三部分组成:
(1) patch嵌入器:通过无损地连接每个字节的嵌入来简单地编码patch
(2) 一个全局模型:一个输入和输出patch表示的大型自回归变换器
(3) 一个本地模型:一个预测patch中字节的小型自回归模型
研究人员观察到,对于多数任务而言字节预测都相对容易(如完成给定前几个字符的单词),这意味着每个字节的大型网络是不必要的,并且可以使用更小的模型进行内部预测。
这种方法解决了当今AI模型中普遍存在的可扩展性挑战,Megabyte 模型的patch系统允许单个前馈网络在包含多个token的patch上运行,从而有效解决了自注意力缩放问题。
其中,Megabyte架构对长序列建模的Transformer进行了三项主要改进:
- 二次自注意力(Sub-quadratic self-attention)
大多数关于长序列模型的工作都集中在减轻自注意力的二次成本上,而Megabyte将长序列分解为两个较短的序列,即使对于长序列也仍然易于处理。
- patch前馈层(Per-patch feedforward layers)
在GPT-3大小的模型中,超过98%的FLOPS用于计算位置前馈层,Megabyte每个patch使用大型前馈层,以相同的成本实现更大、性能更强的模型。在patch大小为P的情况下,基线转换器将使用具有m个参数的相同前馈层P次,兆字节可以以相同的成本使用具有mP个参数的层一次。
- 解码中的并行性(Parallelism in Decoding)
Transformers必须在生成期间串行执行所有计算,因为每个时间步的输入是前一个时间步的输出,通过并行生成patch的表示,Megabyte允许在生成过程中实现更大的并行性。
例如,具有1.5B参数的Megabyte模型生成序列的速度比标准的350MTransformer快40%,同时在使用相同的计算量进行训练时还能改善困惑度。
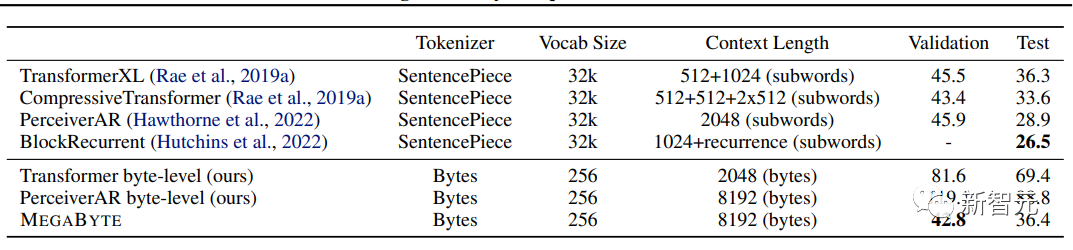
Megabyte远远优于其他模型,并提供与在子词上训练的 sota 模型竞争的结果
相比之下,OpenAI 的GPT-4有32,000个token的限制,而Anthropic的Claude有100,000个token的限制。
此外,在运算效率方面,在固定模型大小和序列长度范围内,Megabyte比同等大小的Transformers和Linear Transformers使用更少的token,允许以相同的计算成本使用更大的模型。
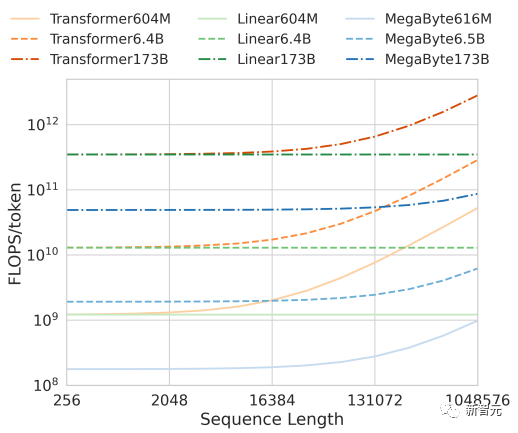
总之,这些改进使我们能够在相同的计算预算下训练更大、性能更好的模型,扩展到非常长的序列,并提高部署期间的生成速度。
未来将会如何
随着AI军备竞赛进行地如火如荼,模型性能越来越强,参数也越来越高。
虽然GPT-3.5在175B个参数上进行了训练,但有人猜测功能更强大的GPT-4在1万亿个参数上进行了训练。
OpenAI的CEO Sam Altman最近也建议转变战略,他表示公司正在考虑舍弃对庞大模型的训练,而专注于其他性能的优化。
他将AI模型的未来等同于iPhone芯片,而大多数消费者对原始技术规格一无所知。
Meta的研究人员相信他们的创新架构来得正是时候,但也承认还有其他优化途径。
例如采用修补技术的更高效的编码器模型、将序列分解为更小块的解码模型以及将序列预处理为压缩token等,并且可以扩展现有Transformer架构的能力以构建新一代模型。
前特斯拉AI总监Andrej Karpathy也在这篇论文中发表了看法,他在推特上写道:
这是非常有希望的,每个人都应该希望我们能在大模型中扔掉标记化,也不需要那些过长字节的序列。