本项目针对工业工件表面缺陷检测,解决传统人工检测的主观化、低效率等问题,以及样本标签不完整等难题。方案先用百度飞桨PaddleX构建分类网络完成图像分类,再通过卷积特征图生成热力图,经阈值分割、轮廓查找实现缺陷定位,还给出了环境配置、数据准备、模型训练等代码实现过程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1、项目说明
在复杂的生产过程中难以避免产出表面带有缺陷的劣质工件。工件表面存在 缺陷不仅影响其外观质量,还影响其使用寿命与稳定性,由于复杂的生产工艺以及不确定的环境因素难以避免生产出一些表面带有缺陷的劣质工件。工件表面存在缺陷直接影响工件的外观质量,工件外观质量又决定着工件的价值,且直接关系着使用过程中的安全性和稳定性。
例如: 
传统的工件表面缺陷检测方式常常为人工检测,而传统的人工检测存在以下不足:
- 受技术人员的经验、认知、思维等主观因素以及光照、环境等客观因素的影响,容易导致检测结果主观化、非标准化;
- 经过长时间重复工作的情况下技术人员难免精神疲惫、视觉疲劳,容易导致检测结果存在漏检与误检现象;
- 针对微小缺陷以及颜色、纹理不清楚的缺陷工件表面检测较为困难;
- 当基于接触式工件表面缺陷人工检测,可能会对待检测工件造成二次损伤;
- 由于人本身精力有限,传统的人工检测工作方式效率低。
- 实际应用中很多样本集存在标签不完整、无边框标注信息等问题,如工件无人工标注的边框信息,而标注过程较为繁琐
本项目内容为工业上工件表面缺陷分类,完成工件缺乏边框标注信息的缺陷定位。
2、项目方案
2.1 图像分类
使用百度飞浆PaddleX快速构建分类网络
PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
2.2 缺陷定位
利用卷积特征图计算出热力图,并对热力图进行 RGB 通道分离,在 G 通道进行阈值分割获得缺陷部区域,阈值分割公式。热力图的每一个像素点的灰度值大于阈值则输出值为 255,否则为 0。最后利用二值 化图像进行轮廓查找,保留最外轮廓,最后求得轮廓的外接矩形即完成缺陷定位。
Sij={255, heatmapij>th0, otherwise

3、代码实现
3.0 环境配置
#安装paddlex!pip install paddlex==2.1.0
3.1 数据集准备
本项目使用,mvtec_ad工业质检著名数据集 ,一共有15个类别,这里以carpet和grid为例已将数据集划分好保存在mydata和grid目录下
#解压数据集!unzip -o -q -d /home/aistudio/work /home/aistudio/data/data116256/mvtec_anomaly_detection.zip
#批量修改文件名import os#设定文件路径path='work/grid/test/broken'i=1#对目录下的文件进行遍历for file in os.listdir(path):#判断是否是文件
if os.path.isfile(os.path.join(path,file))==True:#设置新文件名
new_name=file.replace(file,"broken_%d.png"%i)#重命名
os.rename(os.path.join(path,file),os.path.join(path,new_name))
i+=1#结束print ("End")
End
#移动图片到mydata目录import shutil#这个库复制文件比较省事import osfrom PIL import Image
dirname_read="work/grid/test/thread/" # 注意后面的斜杠dirname_write="grid/notgood/"names_all=os.listdir(dirname_read)def file_filter(f):
if f[-4:] in ['.jpg', '.png', '.bmp']: return True
else: return Falsepicture_nmmes = list(filter(file_filter, names_all))print(picture_nmmes)print(len(picture_nmmes))print(dirname_read)for i in picture_nmmes:
new_obj_name = i print(new_obj_name)
shutil.copy(dirname_read + '/' + new_obj_name, dirname_write + '/' + new_obj_name)
#划分carpet数据集!paddlex --split_dataset --format ImageNet --dataset_dir mydata --val_value 0.2 --test_value 0.1
#划分grid数据集!paddlex --split_dataset --format ImageNet --dataset_dir grid --val_value 0.2 --test_value 0.1
3.2 训练分类模型
训练模型
train训练参数
Args:
num_epochs (int): 训练迭代轮数。
train_dataset (paddlex.datasets): 训练数据读取器。
train_batch_size (int): 训练数据batch大小。同时作为验证数据batch大小。默认值为64。
eval_dataset (paddlex.datasets: 验证数据读取器。
save_interval_epochs (int): 模型保存间隔(单位:迭代轮数)。默认为1。
log_interval_steps (int): 训练日志输出间隔(单位:迭代步数)。默认为2。
save_dir (str): 模型保存路径。
pretrain_weights (str): 若指定为路径时,则加载路径下预训练模型;若为字符串'IMAGENET',
则自动下载在ImageNet图片数据上预训练的模型权重;若为None,则不使用预训练模型。若为'BAIDU10W',则自动下载百度自研10万类预训练。默认为'BAIDU10W'。
optimizer (paddle.fluid.optimizer): 优化器。当该参数为None时,使用默认优化器:
fluid.layers.piecewise_decay衰减策略,fluid.optimizer.Momentum优化方法。
learning_rate (float): 默认优化器的初始学习率。默认为0.025。
warmup_steps(int): 学习率从warmup_start_lr上升至设定的learning_rate,所需的步数,默认为0
warmup_start_lr(float): 学习率在warmup阶段时的起始值,默认为0.0
lr_decay_epochs (list): 默认优化器的学习率衰减轮数。默认为[30, 60, 90]。
lr_decay_gamma (float): 默认优化器的学习率衰减率。默认为0.1。
use_vdl (bool): 是否使用VisualDL进行可视化。默认值为False。
sensitivities_file (str): 若指定为路径时,则加载路径下敏感度信息进行裁剪;若为字符串'DEFAULT',
则自动下载在ImageNet图片数据上获得的敏感度信息进行裁剪;若为None,则不进行裁剪。默认为None。
eval_metric_loss (float): 可容忍的精度损失。默认为0.05。
early_stop (bool): 是否使用提前终止训练策略。默认值为False。
early_stop_patience (int): 当使用提前终止训练策略时,如果验证集精度在`early_stop_patience`个epoch内
连续下降或持平,则终止训练。默认值为5。
resume_checkpoint (str): 恢复训练时指定上次训练保存的模型路径。若为None,则不会恢复训练。默认值为None。
Raises:
ValueError: 模型从inference model进行加载。
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'import paddlex as pdximport paddlex as pdxfrom paddlex import transforms as T
train_transforms = T.Compose(
[T.RandomCrop(crop_size=224), T.RandomHorizontalFlip(), T.Normalize()])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])# 定义训练和验证所用的数据集# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.mdtrain_dataset = pdx.datasets.ImageNet(
data_dir='grid',
file_list='grid/train_list.txt',
label_list='grid/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='grid',
file_list='grid/val_list.txt',
label_list='grid/labels.txt',
transforms=eval_transforms)# 初始化模型,并进行训练# 可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/visualdl.mdnum_classes = len(train_dataset.labels)
model = pdx.cls.ResNet50_vd(num_classes=num_classes)
model.train(
num_epochs=80,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
learning_rate=0.01,
save_dir='output/grid',
use_vdl=True)
3.3 模型预测
import paddlex as pdx
model = pdx.load_model('output/ResNet50_vd/best_model')
image_name = 'mydata/notgood/000.png'result = model.predict(image_name)str=result[0]print("Predict Result:", result)if str['category_id'] : print("有缺陷")else: print("无缺陷")
2022-05-27 16:56:52 [INFO] Model[ResNet50_vd] loaded.
Predict Result: [{'category_id': 1, 'category': 'notgood', 'score': 0.737099}]
有缺陷
3.4 输出结果
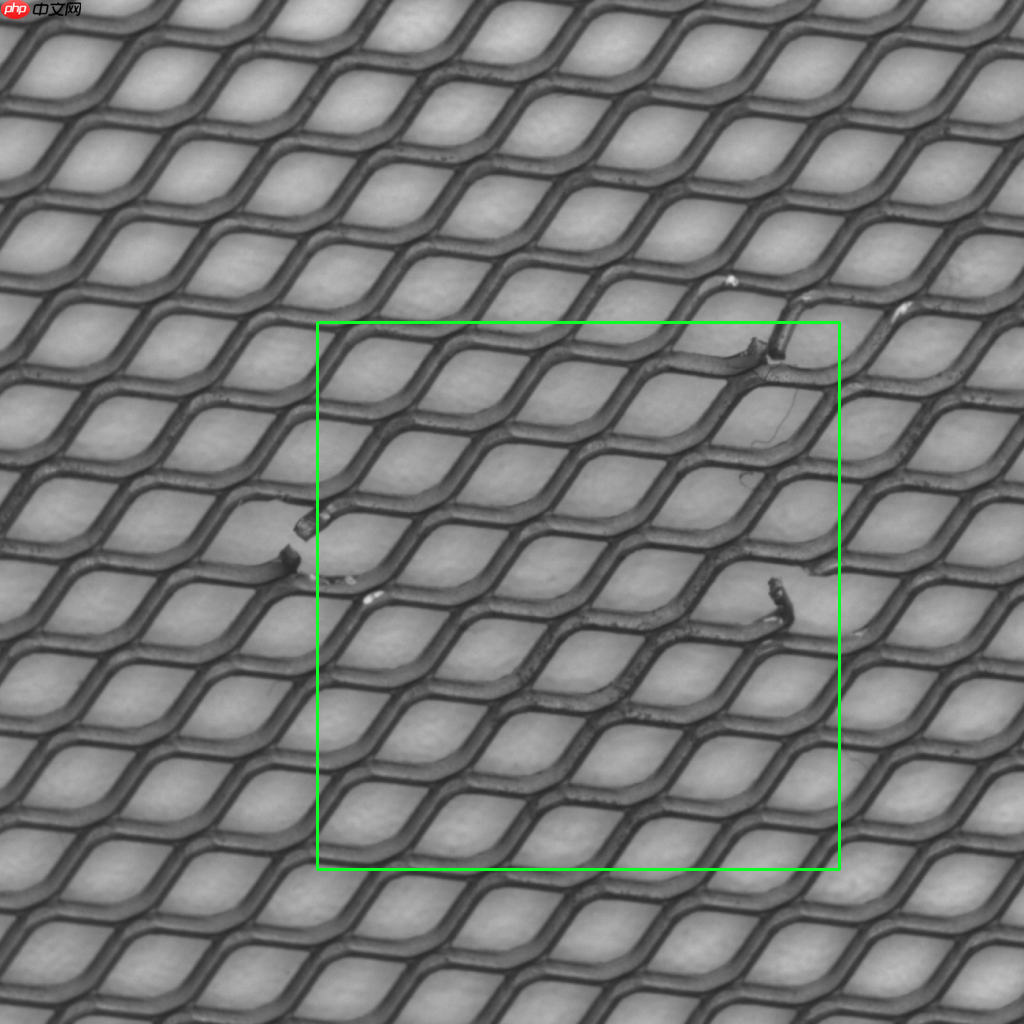
进行模型预测,并输出神经网络热力图,完成缺陷定位。
输出结果保存在Heatmap/result.png
%matplotlib inlineimport osfrom PIL import Imageimport paddleimport numpy as npimport cv2import matplotlib.pyplot as pltfrom draw_features import Res2Net_vdimport draw_featuresimport paddle.nn.functional as Fimport paddleimport warnings
warnings.filterwarnings('ignore')def draw_CAM(model, img_path, save_path, transform=None, visual_heatmap=False):
'''
绘制 Class Activation Map
:param model: 加载好权重的Pytorch model
:param img_path: 测试图片路径
:param save_path: CAM结果保存路径
:param transform: 输入图像预处理方法
:param visual_heatmap: 是否可视化原始heatmap(调用matplotlib)
:return:
'''
# 图像加载&预处理
img = Image.open(img_path).convert('RGB')
img = img.resize((224, 224), Image.BILINEAR) #Image.BILINEAR双线性插值
if transform:
img = transform(img) # img = img.unsqueeze(0)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = paddle.to_tensor(img)
img = paddle.unsqueeze(img, axis=0) # print(img.shape)
# 获取模型输出的feature/score
output,features = model(img) print('outputshape:',output.shape) print('featureshape:',features.shape) # lab = np.argmax(out.numpy())
# 为了能读取到中间梯度定义的辅助函数
def extract(g):
global features_grad
features_grad = g # 预测得分最高的那一类对应的输出score
pred = np.argmax(output.numpy()) # print('***********pred:',pred)
pred_class = output[:, pred] # print(pred_class)
features.register_hook(extract)
pred_class.backward() # 计算梯度
grads = features_grad # 获取梯度
# print(grads.shape)
# pooled_grads = paddle.nn.functional.adaptive_avg_pool2d( x = grads, output_size=[1, 1])
pooled_grads = grads # 此处batch size默认为1,所以去掉了第0维(batch size维)
pooled_grads = pooled_grads[0] # print('pooled_grads:', pooled_grads.shape)
# print(pooled_grads.shape)
features = features[0] # print(features.shape)
# 最后一层feature的通道数
for i in range(2048):
features[i, ...] *= pooled_grads[i, ...]
heatmap = features.detach().numpy()
heatmap = np.mean(heatmap, axis=0) # print(heatmap)
heatmap = np.maximum(heatmap, 0) # print('+++++++++',heatmap)
heatmap /= np.max(heatmap) # print('+++++++++',heatmap)
# 可视化原始热力图
if visual_heatmap:
plt.matshow(heatmap)
plt.show()
img = cv2.imread(img_path) # 用cv2加载原始图像
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0])) # 将热力图的大小调整为与原始图像相同
heatmap = np.uint8(255 * heatmap) # 将热力图转换为RGB格式
cv2.imwrite('Heatmap/heatmap.png',heatmap);#将热力图保存到硬盘
heatmap1 =heatmap # print(heatmap.shape)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) # 将热力图应用于原始图像
superimposed_img = heatmap * 0.4 + img # 这里的0.4是热力图强度因子
cv2.imwrite(save_path, superimposed_img) # 将图像保存到硬盘
the =220 # 设置阈值
maxval = 255
dst, heatmap1 = cv2.threshold(heatmap1, the, maxval, cv2.THRESH_BINARY)
cnts = cv2.findContours(heatmap1, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1] #画出轮廓
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
cv2.rectangle(img, (x, y), (x + w, y + h), (36,255,12), 2)
cv2.imwrite('Heatmap/result.png',img);# 将图像保存到硬盘model_re2 = Res2Net_vd(layers=50, scales=4, width=26, class_dim=4)# model_re2 = Res2Net50_vd_26w_4s(class_dim=4)modelre2_state_dict = paddle.load("output/ResNet50_vd/best_model/model.pdparams")
model_re2.set_state_dict(modelre2_state_dict, use_structured_name=True)
use_gpu = Truepaddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
model_re2.eval()import paddlex as pdx
model = pdx.load_model('output/ResNet50_vd/best_model')#模型路径image_name = 'mydata/notgood/000.png'#输入图片路径result = model.predict(image_name)print("Predict Result:", result)str=result[0]if str['category_id'] : print("有缺陷")
draw_CAM(model_re2, image_name, 'Heatmap/Heatmap.png', transform=None, visual_heatmap=True)else: print("无缺陷")
W0602 00:36:36.333329 20180 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0602 00:36:36.338220 20180 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[06-02 00:36:39 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported
2022-06-02 00:36:40 [INFO] Model[ResNet50_vd] loaded.
Predict Result: [{'category_id': 1, 'category': 'notgood', 'score': 0.737099}]
有缺陷
outputshape: [1, 4]
featureshape: [1, 2048, 7, 7]
<Figure size 288x288 with 1 Axes>
3.5 效果展示

grid效果!