






该项目利用VoxNet实现点云分类任务,使用ModelNet40数据集,抽取1024个点训练。先将点云转成32×32×32体素数据,生成训练和测试样本列表,构建数据加载器。VoxNet含3D卷积等层,通过Adam优化器训练100轮,保存模型,评估后可预测点云类别,如示例中成功识别出飞机。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


点云处理:VoxNet分类任务
项目效果
如图所示,能预测出该点云所对应的类别。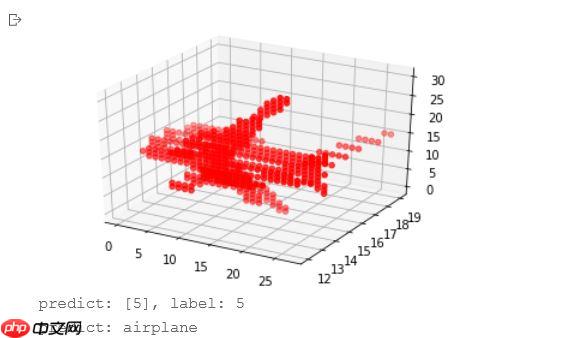
项目说明
①数据集
ModelNet总共有662中目标分类,127915个CAD,以及十类标记过方向朝向的数据。其中包含了三个子集:
1、ModelNet10:十个标记朝向的子集数据;
2、ModelNet40:40个类别的三维模型;
3、Aligned40:40类标记的三维模型。
这里使用了ModelNet40,并且归一化了,文件中的数据的意义:
1、横轴有六个数字,分别代表:x, y, z, r, g, b;
2、纵轴为点,每份数据一共有10000个点,项目中每份数据抽取其中1024个点进行训练。
In [ ]
!unzip data/data50045/modelnet40_normal_resampled.zip!mkdir dataset
②VoxNet简介
VoxNet:Volumetric Convolutional Neural Networks,将3D卷积应用到处理点云上,是一个比较早且比较好玩的网络。其发表在15年的文章,在IEEE/RSJ,机器人方面顶会IROS。
一、提出背景:
当时的很多方法要么不在机器人领域使用3D数据,要么就是处理不了这么大量的点云数据。于是提出的VoxNet利用3D CNN来对被占用的网格的体素进行处理。
二、网络结构: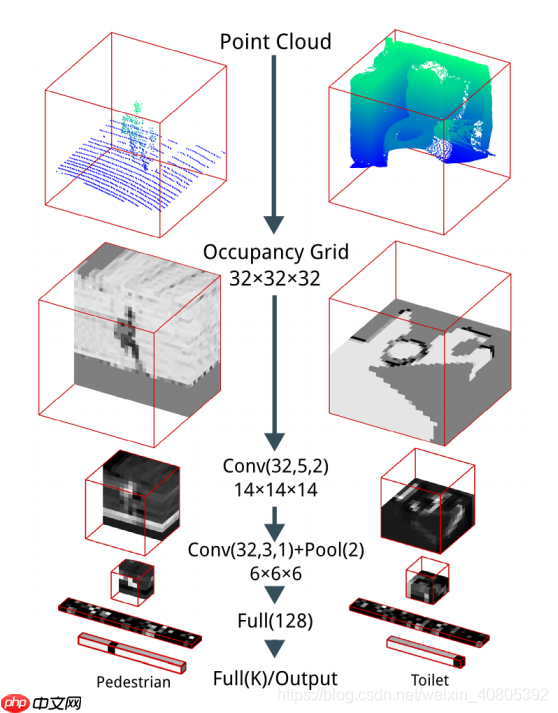
三、搭建过程的几个要点:
①、将点云数据转成体素数据,这里选择分辨率使得数据占据32×32×32体素的子体积(后面还有论文提出了更好玩的点云转成体素的方法,后面有时间俺可以再写下这方面的)。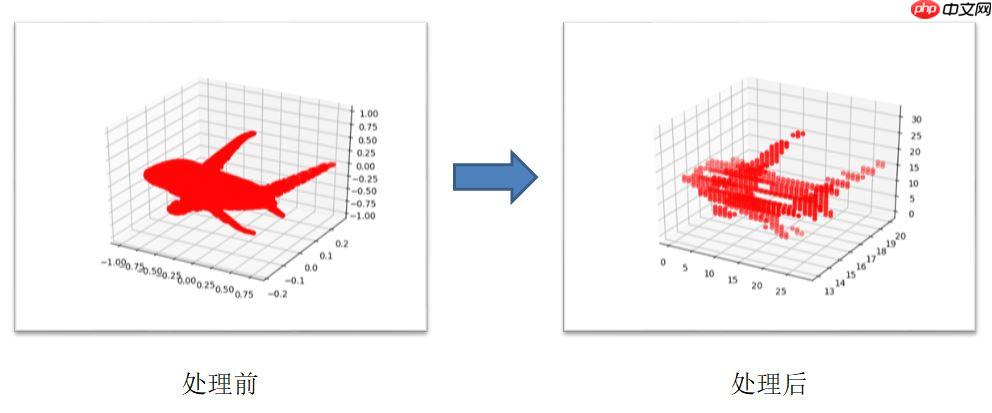
②、3D卷积处理体素数据(VoxNet)。
项目主体
①导入需要的库
In [1]
import osimport numpy as npimport randomimport paddleimport paddle.nn.functional as Ffrom paddle.nn import Conv3D, MaxPool3D, Linear, BatchNorm, Dropout, LeakyReLU, Softmax, Sequential
*②数据处理
1、类别
In [32]
category = { 'bathtub': 0, 'bed': 1, 'chair': 2, 'door': 3, 'dresser': 4, 'airplane': 5, 'piano': 6, 'sofa': 7, 'person': 8, 'cup': 9}
_category = { 0: 'bathtub', 1: 'bed', 2: 'chair', 3: 'door', 4: 'dresser', 5: 'airplane', 6: 'piano', 7: 'sofa', 8: 'person', 9: 'cup'}
categoryList = [ 'bathtub', 'bed', 'chair', 'door', 'dresser', 'airplane', 'piano', 'sofa', 'person', 'cup']
*2、将点云数据转成体素数据
In [ ]
def transform():
for i in range(len(categoryList)):
dirpath = os.path.join('./modelnet40_normal_resampled', categoryList[i])
dirlist = os.listdir(dirpath) if not os.path.exists(os.path.join('./dataset', categoryList[i])):
os.mkdir(os.path.join('./dataset', categoryList[i])) for datalist in dirlist:
datapath = os.path.join(dirpath, datalist)
zdata = []
xdata = []
ydata = []
f = open(datapath, 'r') for point in f:
xdata.append(float(point.split(',')[0]))
ydata.append(float(point.split(',')[1]))
zdata.append(float(point.split(',')[2]))
f.close()
arr = np.zeros((32,) * 3).astype('float32') for j in range(len(xdata)):
arr[int(xdata[j] * 15.5 + 15.5)][int(ydata[j] * 15.5 + 15.5)][int(zdata[j] * 15.5 + 15.5)] = 1
savepath = os.path.join('./dataset', categoryList[i], datalist.split('.')[0]+'.npy')
np.save(savepath, arr)if __name__ == '__main__':
transform()
3、生成训练和测试样本的list
In [ ]
def getDatalist():
f_train = open('./dataset/train.txt', 'w')
f_test = open('./dataset/test.txt', 'w') for i in range(len(categoryList)):
dict_path = os.path.join('./dataset/', categoryList[i])
data_dict = os.listdir(dict_path)
count = 0
for data_path in data_dict: if count % 60 != 0:
f_train.write(os.path.join(dict_path, data_path) + ' ' + categoryList[i]+ '\n') else:
f_test.write(os.path.join(dict_path, data_path) + ' ' + categoryList[i]+ '\n')
count += 1
f_train.close()
f_test.close()if __name__ == '__main__':
getDatalist()
4、数据读取
In [3]
def pointDataLoader(file_path='./dataset/train.txt', mode='train'):
BATCHSIZE = 64
MAX_POINT = 1024
datas = []
labels = []
f = open(file_path) for data_list in f:
point_data = np.load(data_list.split(' ')[0])
datas.append(point_data)
labels.append(category[data_list.split(' ')[1].split('\n')[0]])
f.close()
datas = np.array(datas)
labels = np.array(labels)
index_list = list(range(len(datas))) def pointDataGenerator():
if mode == 'train':
random.shuffle(index_list)
datas_list = []
labels_list = [] for i in index_list:
data = np.reshape(datas[i], [1, 32, 32, 32]).astype('float32')
label = np.reshape(labels[i], [1]).astype('int64')
datas_list.append(data)
labels_list.append(label) if len(datas_list) == BATCHSIZE: yield np.array(datas_list), np.array(labels_list)
datas_list = []
labels_list = [] if len(datas_list) > 0: yield np.array(datas_list), np.array(labels_list) return pointDataGenerator
*③定义网络
In [4]
class VoxNet(paddle.nn.Layer):
def __init__(self, name_scope='VoxNet_', num_classes=10):
super(VoxNet, self).__init__()
self.backbone = Sequential(
Conv3D(1, 32, 5, 2),
BatchNorm(32),
LeakyReLU(),
Conv3D(32, 32, 3, 1),
MaxPool3D(2, 2, 0)
)
self.head = Sequential(
Linear(32*6*6*6, 128),
LeakyReLU(),
Dropout(0.2),
Linear(128, num_classes),
Softmax()
) def forward(self, inputs):
x = self.backbone(inputs)
x = paddle.reshape(x, (-1, 32*6*6*6))
x = self.head(x) return x
voxnet = VoxNet()
paddle.summary(voxnet, (64, 1, 32, 32, 32))
----------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # ============================================================================= Conv3D-1 [[64, 1, 32, 32, 32]] [64, 32, 14, 14, 14] 4,032 BatchNorm-1 [[64, 32, 14, 14, 14]] [64, 32, 14, 14, 14] 128 LeakyReLU-1 [[64, 32, 14, 14, 14]] [64, 32, 14, 14, 14] 0 Conv3D-2 [[64, 32, 14, 14, 14]] [64, 32, 12, 12, 12] 27,680 MaxPool3D-1 [[64, 32, 12, 12, 12]] [64, 32, 6, 6, 6] 0 Linear-1 [[64, 6912]] [64, 128] 884,864 LeakyReLU-2 [[64, 128]] [64, 128] 0 Dropout-1 [[64, 128]] [64, 128] 0 Linear-2 [[64, 128]] [64, 10] 1,290 Softmax-1 [[64, 10]] [64, 10] 0 ============================================================================= Total params: 917,994 Trainable params: 917,866 Non-trainable params: 128 ----------------------------------------------------------------------------- Input size (MB): 8.00 Forward/backward pass size (MB): 159.20 Params size (MB): 3.50 Estimated Total Size (MB): 170.70 -----------------------------------------------------------------------------
{'total_params': 917994, 'trainable_params': 917866}
⑤训练
In [5]
def train():
train_loader = pointDataLoader(file_path='./dataset/train.txt', mode='train')
model = VoxNet()
optim = paddle.optimizer.Adam(parameters=model.parameters(), weight_decay=0.001)
loss_fn = paddle.nn.CrossEntropyLoss()
epoch_num = 100
for epoch in range(epoch_num): for batch_id, data in enumerate(train_loader()):
inputs = paddle.to_tensor(data[0])
labels = paddle.to_tensor(data[1])
predicts = model(inputs)
loss = F.cross_entropy(predicts, labels)
acc = paddle.metric.accuracy(predicts, labels)
loss.backward()
optim.step()
optim.clear_grad() if batch_id % 8 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy())) if epoch % 20 == 0:
paddle.save(model.state_dict(), './model/VoxNet.pdparams')
paddle.save(optim.state_dict(), './model/VoxNet.pdopt')if __name__ == '__main__':
train()
⑥评估
In [7]
def evaluation():
test_loader = pointDataLoader(file_path='./dataset/test.txt', mode='test')
model = VoxNet()
model_state_dict = paddle.load('./model/VoxNet.pdparams')
model.load_dict(model_state_dict) for batch_id, data in enumerate(test_loader()):
inputs = paddle.to_tensor(data[0])
labels = paddle.to_tensor(data[1])
predicts = model(inputs)
loss = F.cross_entropy(predicts, labels)
acc = paddle.metric.accuracy(predicts, labels) # 打印信息
if batch_id % 100 == 0: print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id, loss.numpy(), acc.numpy()))if __name__ == '__main__':
evaluation()
batch_id: 0, loss is: [1.4866376], acc is: [0.96875]
⑦预测
In [28]
def visual(file_path='./dataset/predict.txt'):
f = open(file_path)
arr = np.load(f.readline().split(' ')[0])
f.close()
zdata = []
xdata = []
ydata = [] for i in range(arr.shape[0]): for j in range(arr.shape[1]): for k in range(arr.shape[2]): if arr[i][j][k] == 1:
xdata.append(float(i))
ydata.append(float(j))
zdata.append(float(k))
xdata = np.array(xdata)
ydata = np.array(ydata)
zdata = np.array(zdata) from mpl_toolkits import mplot3d
%matplotlib inline import matplotlib.pyplot as plt
ax = plt.axes(projection='3d')
ax.scatter3D(xdata, ydata, zdata, c='r')
plt.show()
In [38]
def test():
test_loader = pointDataLoader(file_path='./dataset/predict.txt', mode='test')
model = VoxNet()
model_state_dict = paddle.load('./model/VoxNet.pdparams')
model.load_dict(model_state_dict) for batch_id, data in enumerate(test_loader()):
predictdata = paddle.to_tensor(data[0])
label = paddle.to_tensor(data[1])
predict = model(predictdata) print("predict: {}, label: {}".format(np.argmax(predict.numpy(), 1), np.squeeze(label.numpy()))) print("predict: {}".format(_category[int(np.argmax(predict.numpy(), 1))]))if __name__ == '__main__':
visual()
test()
<Figure size 432x288 with 1 Axes>
predict: [5], label: 5 predict: airplane




























