






本文围绕世界人工智能创新大赛AIWIN手写字体OCR识别竞赛任务一,提出优化方案。在原baseline基础上更换更优模型并微调,得分提升1.955%至0.99171,排名39/137。介绍数据处理流程,包括格式转换、划分训练验证集等,还涉及模型构建与预测,最后总结尝试及优化建议。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

世界人工智能创新大赛AIWIN手写字体OCR识别竞赛任务一优化方案
一、竞赛介绍
2021世界人工智能创新大赛(AIWIN),由世界人工智能大会组委会主办,AI SPACE承办,是全球范围内初具影响力的人工智能赛事,是2021世界人工智能大会的重要组成部分。
秋季赛将继续围绕“人工智能助力城市数字化转型”的主题,以“开展算法创新、选拔数字人才”为目标,继续秉持“高端化、专业化、国际化、市场化“的原则开展赛事。
今年提供手写字体OCR识别竞赛和心电智能诊断算法竞赛两个赛题。
我们选取【手写字体OCR识别竞赛】任务一进行实验,接下来对赛题背景及任务进行简单介绍。
1.1 赛题背景
银行日常业务中涉及到各类凭证的识别录入,例如身份证录入、支票录入、对账单录入等。以往的录入方式主要是以人工录入为主,效率较低,人力成本较高。近几年来,OCR相关技术以其自动执行、人为干预较少等特点正逐步替代传统的人工录入方式。但OCR技术在实际应用中也存在一些问题,在各类凭证字段的识别中,手写体由于其字体差异性大、字数不固定、语义关联性较低、凭证背景干扰等原因,导致OCR识别率准确率不高,需要大量人工校正,对日常的银行录入业务造成了一定的影响。
1.2 赛题任务
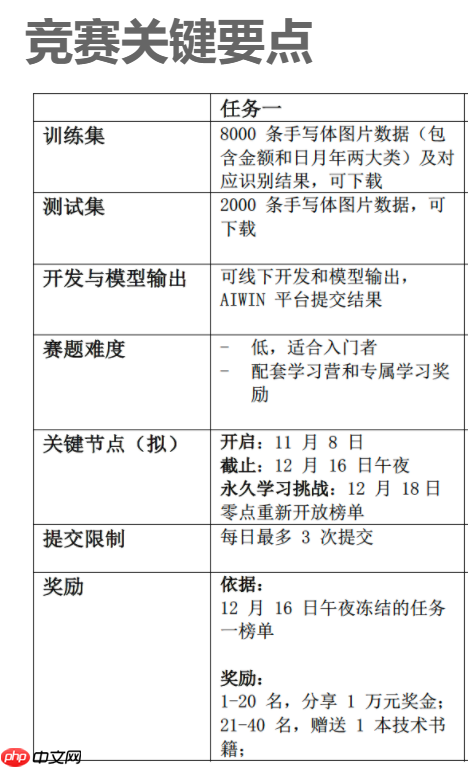
1.3 赛题奖励
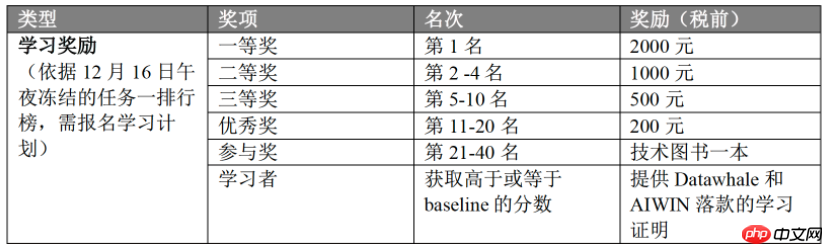
本次方案简介:
在参考原作者的baseline:【Paddle打比赛】手写字体OCR识别竞赛baseline的基础上,更换精度更好的模型,并在这基础进行fine-tune
原作者Baseline得分:0.97216
本次方案得分:0.99171(+1.955%),最终排名:39/137。证明此方案可行

二、数据处理
2.1 数据下载
大赛使用数据要求如下"参赛人员不得对外以任何形式转载、发布赛题的训练集、验证集的全部或任意部分",因此需要大家自行去官网下载数据集。
注:数据量8000,且均是文字区域,下载速度很快。
#新建文件夹【dataset】!mkdir dataset
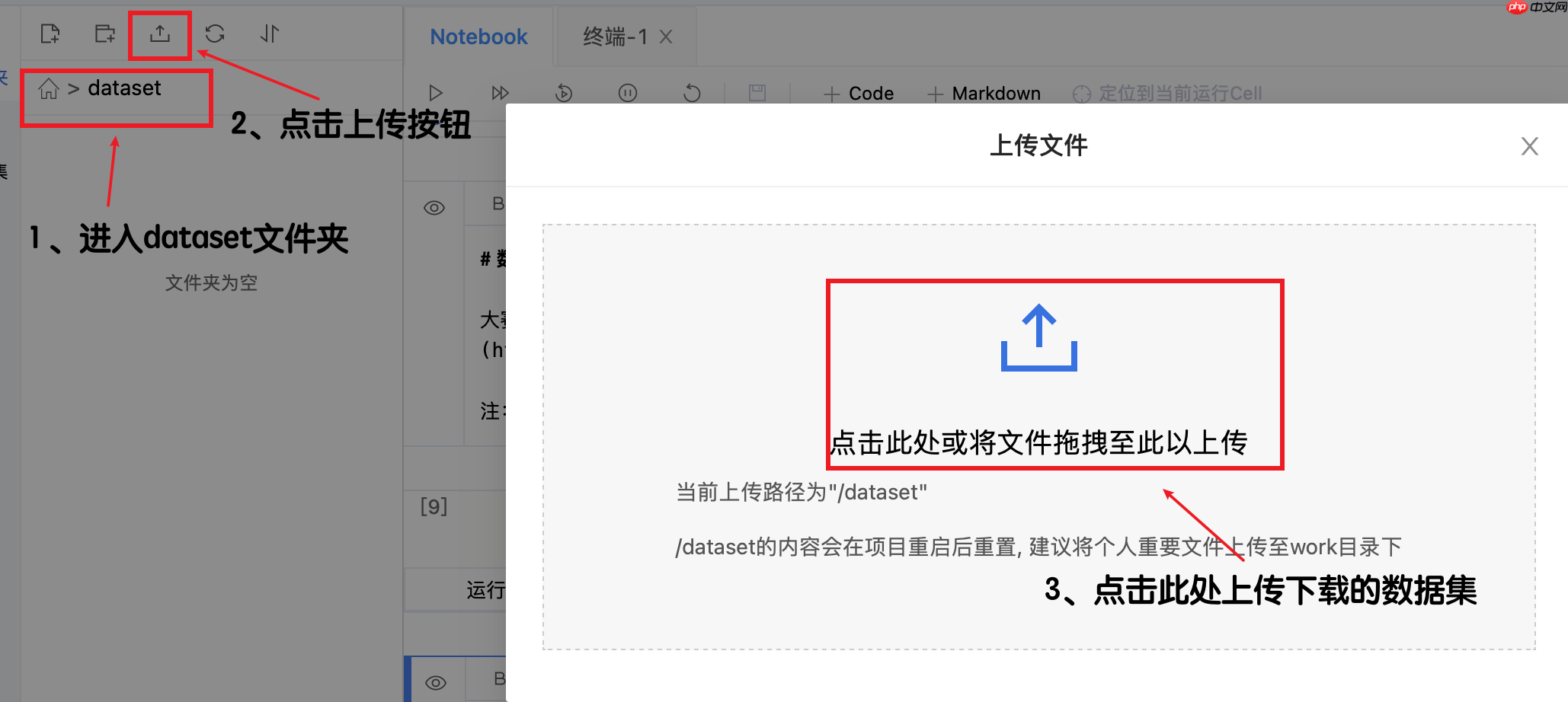
将下载的数据集上传到【dataset】文件夹内,操作流程如下图所示:
然后解压数据集:
!unzip -q data/2021A_T1_Task1_Sample_V1106.zip -d ./dataset/ !unzip -q data/2021A_T1_Task1_数据集.zip -d ./dataset/
2.2 数据格式
下载的数据标注为json格式且图片在两个文件夹内,我们需要处理为PaddleOCR训练所需要的格式:建议将训练图片放入同一个文件夹,并用一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
注意: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
" 图像文件名 图像标注信息 "train_data/rec/train/word_001.jpg 简单可依赖 train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单 ...
最终训练集应有如下文件结构:
|-train_data
|- rec_gt_train.txt
|- train
|- 8bb1941c760a2c1d017626c361da6c4d.jpg
|- 8bb1941c760a2c1d01762b943a624421.jpg
|- 8bb1941c760a2c1d0176415a9ec807fe.jpg
| ...
接下来,我们一起看怎么用代码具体实现吧~
import osimport os.path as ospimport jsonimport shutilimport yaml
定义write_file函数,处理训练集中date和amount中的数据:
def write_file(file, json_file, save_pic):
# 读取json文件
data = yaml.load(open(json_file))
# all_str为了后面统计训练集的字典
all_str = ''
for pic_name, label_info in data.items(): # 修改成OCR需要的格式
line = os.path.join(save_pic, pic_name)+'\t'+label_info+'\n'
file.write(line)
all_str+=label_info # 将图片移动到save_pic目录下
ori_path = osp.join(osp.dirname(json_file), 'images', pic_name)
save_path = osp.join(save_pic, pic_name)
shutil.copy(ori_path, save_path) return set(all_str)
2.3划分数据集
原作者是把所有数据进行训练,这样对进行fine-tune不太友好,因此我把原数据集进行8:2进行划分为训练集、验证集,这样可以更直观看到自己改进的参数是否对模型有帮助,可手动删除rec_gt_val.txt多的部分。
import randomimport os# 处理数据之后的保存路径# !mkdir 'train_data'# 记录图片和标签的txtsave_txt = '/home/aistudio/train_data/rec_gt_train.txt'save_val_txt='/home/aistudio/train_data/rec_gt_val.txt'# 所有图片放在一个文件夹内save_pic = '/home/aistudio/train_data/train'if not os.path.exists(save_pic):
os.mkdir(save_pic)# 读取date和amount的json文件date_json = '/home/aistudio/dataset/训练集/date/gt.json'amount_json = '/home/aistudio/dataset/训练集/amount/gt.json'file = open(save_txt, 'w')
date_set = write_file(file, date_json, save_pic)
amount_set = write_file(file, amount_json, save_pic)
file.close()
file = open(save_val_txt, 'w')
date_set = write_file(file, date_json, save_pic)
amount_set = write_file(file, amount_json, save_pic)
file.close()
处理测试集,将所有图片放在一个文件夹内:
!mkdir /home/aistudio/test_data/ !cp -r /home/aistudio/dataset/测试集/amount/images/* /home/aistudio/test_data/ !cp -r /home/aistudio/dataset/测试集/date/images/* /home/aistudio/test_data/

character_dict_path = 'train_data/rec_gt_label.txt'with open(character_dict_path, 'w', encoding='utf-8') as out_file:
merge_set = date_set|amount_set
num_class = len(merge_set) print('num_class:',num_class) for label in merge_set:
line = label+'\n'
out_file.write(line)
三、模型构建
3.1 识别算法
PaddleOCR中提供了如下文本识别算法列表,以及每个算法在英文公开数据集上的模型和指标,主要用于算法简介和算法性能对比。
文本识别算法:
| 模型 | 骨干网络 | Avg Accuracy | 模型存储命名 | 下载链接 |
|---|---|---|---|---|
| Rosetta | Resnet34_vd | 80.24% | rec_r34_vd_none_none_ctc | 下载链接 |
| Rosetta | MobileNetV3 | 78.16% | rec_mv3_none_none_ctc | 下载链接 |
| CRNN | Resnet34_vd | 82.20% | rec_r34_vd_none_bilstm_ctc | 下载链接 |
| CRNN | MobileNetV3 | 79.37% | rec_mv3_none_bilstm_ctc | 下载链接 |
| STAR-Net | Resnet34_vd | 83.93% | rec_r34_vd_tps_bilstm_ctc | 下载链接 |
| STAR-Net | MobileNetV3 | 81.56% | rec_mv3_tps_bilstm_ctc | 下载链接 |
| RARE | Resnet34_vd | 84.90% | rec_r34_vd_tps_bilstm_attn | 下载链接 |
| RARE | MobileNetV3 | 83.32% | rec_mv3_tps_bilstm_attn | 下载链接 |
| SRN | Resnet50_vd_fpn | 88.33% | rec_r50fpn_vd_none_srn | 下载链接 |
3.2 安装PaddleOCR
本项目中已经帮大家安装好了最新版的PaddleOCR,且修改好配置文件、后处理代码,无需安装~
如仍需安装or安装更新,可以执行以下步骤(目前支持Clone GitHub【推荐】和Gitee两种方式):
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
# 安装依赖,每次启动项目都需要执行%cd PaddleOCR !pip install --upgrade pip !pip install -r requirements.txt
3.3 模型训练
原作者是选择CRNN模型进行训练、MobileNetv3作为backbone,具体参数可以在configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml文件里修改训练配置:比如是否使用GPU、模型保存路径、数据集路径、学习率、优化等。
本次方案是选择STAR-Net模型进行训练、Resnet34_vd作为backbone,具体参数可以在configs/rec/ch_ppocr_v2.0/rec_train.yml查看。
注意: 训练的过程中会有 前面27个左右epochs,acc=0的情况,具体原因我也不清楚,期待有懂得同学可以解答一下。
执行命令,启动训练:
!python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_train.yml
四、模型预测
训练好模型之后,即可启动测试,Global.pretrained_model表示预测使用的模型,Global.infer_img表示测试的图片路径或着测试图片文件夹路径:
# 预测中文结果!python3 tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_train.yml -o Global.pretrained_model=output/rec_train/best_accuracy Global.load_static_weights=false Global.infer_img=/home/aistudio/test_data
4.1生成提交比赛所需格式
%cd output/rec
/home/aistudio/PaddleOCR/output/rec
!zip -r answer.zip answer.json
adding: answer.json (deflated 81%)
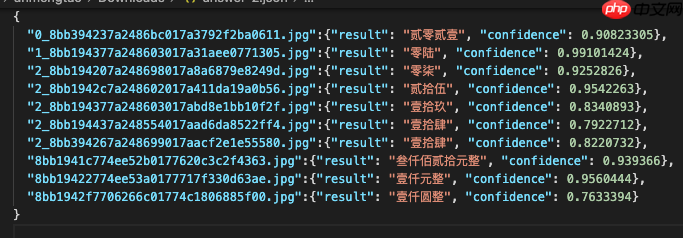
同时修改infer_rec.py将结果保存为比赛要求的格式,保存结果的路径由configs/rec/ch_ppocr_v2.0/rec_train.yml中save_res_path参数控制,结果answer.json效果如下图:
总结
做了许多的尝试,调整学习率,使用更多的数据增强方式,更改batch_size,使用预训练模型等等
结果如下:(+表示有效,-表示效果更差,0表示变动不大)
调整学习率(+)
使用更多的数据增强方式(-)
更改batch_size(0)
使用预训练模型(-)
优化建议:
可以使用精度更高的模型,并进行微调,可以尝试以上我觉得不行的方案,可能是我打开的方式不对,微调过后可以选择多种模型进行融合。




























