






本次赛题聚焦智能文本纠错,针对智媒与文化领域文本的语法、拼写等错误检测与纠正。介绍了数据集情况,初赛、决赛训练集含id、语句及修改后语句,测试集字段有差异。还阐述了基于百度ACL 2021相关策略的模型,包括文件结构、训练、预测、部署步骤及参考文献,模型在SIGHAN测试集有一定效果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、赛题背景
日常生活中,我们经常会在微信、微博等社交工具、公众号文章、甚至新闻稿件中发现许多拼写、语法、标点等错误;经过初步统计:在微博等新媒体领域中,文本敏感和出错概率在2%左右;在语音识别领域中,出错率最高可达8-10%;而在某保险问答领域中,用户提问出错率在去重后仍高达9%,故本次人工智能应用赛的赛题为智能文本纠错。文本纠错作为自然语言处理最基础的模块,是实现中文语句自动检查、自动纠错的一项重要技术,其目的是提高语言正确性的同时减少人工校验成本,其重要程度不言而喻。

二、任务描述
- 赛题任务 本次赛题聚焦智媒与文化领域文本数据,主要应用于媒体内容生产等场景,从中检测错误并纠正,提示修改建议。 错误类型:语法错误,包括多字、少字、乱序、标点等;拼写错误,包括同音字、近音字、形近字等。
- 数据使用规则 本赛题允许使用外部数据。可参考公开数据集: NLPCC2018语法纠错数据集:http://tcci.ccf.org.cn/conference/2018/taskdata.php
三、数据集描述
- 初赛: 数据集包含训练集和测试集,训练集用于选手的模型训练,测试集用于最终结果的评测提交。格式如下:
- 训练集包含三个字段:id,语句,修改后的语句
- 测试集包含三个字段:id,语句,分词后的语句
- 决赛: 数据集包含训练集和测试集,训练集用于选手的模型训练,测试集存在在服务器后台,用于最终结果的评测提交,不提供给选手。
- 训练集包含三个字段:id,语句,修改后的语句
- 测试集包含两个字段:id, 语句
四、评分指标
比赛使用MaxMatch (M2)记分器进行评估。M2算法是一种广泛应用的语法纠错评价方法。总的思路是计算源语句和系统输出之间的短语级编辑。具体来说,它将选择与注释器中的黄金编辑重叠最多的系统假设。扩展了M2的记分器,以处理多组可选的金标准注释,在这种情况下,对于当前的句子有多个合理的更正。 假设黄金编辑集是{g1, g2,…, gn},系统编辑集为{e1, e2,…,}。精度、查全率和F0.5定义如下:
五、模型介绍及其文件结构
1. 模型介绍
中文文本纠错任务是一项NLP基础任务,其输入是一个可能含有语法错误的中文句子,输出是一个正确的中文句子。语法错误类型很多,有多字、少字、错别字等,目前最常见的错误类型是`错别字`。大部分研究工作围绕错别字这一类型进行研究。本文实现了百度在ACL 2021上提出结合拼音特征的Softmask策略的中文错别字纠错的下游任务网络,并提供预训练模型,模型结构如下:
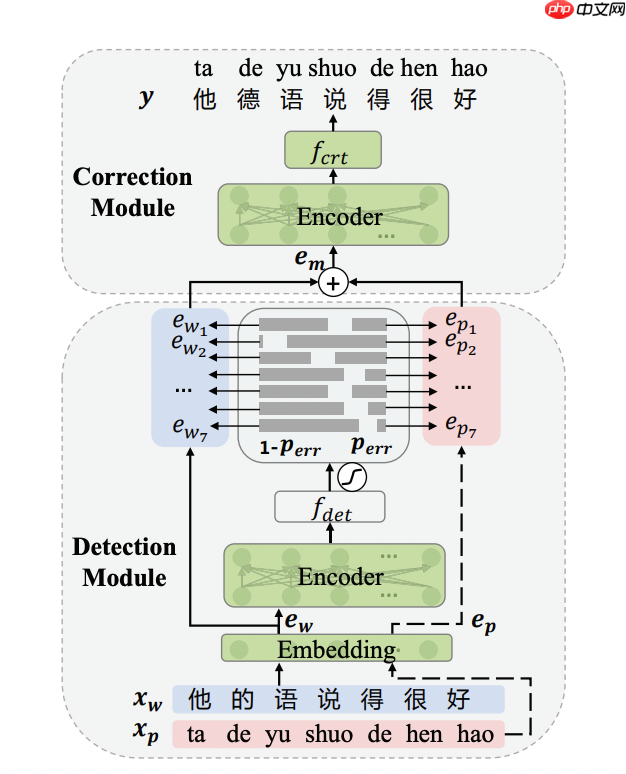
2. 文件目录结构
├── README.md # 文档 ├── download.py # 下载SIGHAN测试集 ├── pinyin_vocab.txt # 拼音字表 ├── predict.py # 预测标准输入的句子 ├── predict_sighan.py # 生成SIGHAN测试集的预测结果 ├── model.py # 纠错模型实现 ├── requirements.txt # 本项目的Python依赖项 ├── run_sighan_predict.sh # 生成训练后模型在SIGHAN测试集的预测结果并输 出预测效果 ├── sighan_evaluate.py # 评估模型在SIGHAN测试集上预测效果 ├── train.py # 训练脚本 └── utils.py # 通用函数工具
六、模型训练
1. 安装依赖项
pip install -r requirements.txt
# 1. 安装依赖项%cd ~/work/text_correction ! pip install -r requirements.txt
2. 模型训练
(1) 参数
- model_name_or_path 目前支持的预训练模型有:"ernie-1.0"。
- max_seq_length 表示最大句子长度,超过该长度的部分将被切分成下一个样本。
- batch_size 表示每次迭代每张卡上的样本数目。
- learning_rate 表示基础学习率大小,将于learning rate scheduler产生的值相乘作为当前学习率。
- epochs 表示训练轮数。
- logging_steps 表示日志打印间隔步数。
- save_steps 表示模型保存及评估间隔步数。
- output_dir 表示模型保存路径。
- device 表示训练使用的设备, 'gpu'表示使用GPU, 'xpu'表示使用百度昆仑卡, 'cpu'表示使用CPU。
- seed 表示随机数种子。
- weight_decay 表示AdamW的权重衰减系数。
- warmup_proportion 表示学习率warmup系数。
- pinyin_vocab_file_path 拼音字表路径。默认为当前目录下的pinyin_vocab.txt文件。
- extra_train_ds_dir 额外纠错训练集目录。用户可在该目录下提供文件名以txt为后缀的纠错数据集文件,以增大训练样本。默认为None。
(2) 训练数据
该模型在SIGHAN简体版数据集以及Automatic Corpus Generation生成的中文纠错数据集上进行Finetune训练。PaddleNLP已经集成SIGHAN简体版数据集,以下将介绍如何使用Automatic Corpus Generation生成的中文纠错数据集。
3. 下载数据集
Automatic Corpus Generation生成的中文纠错数据集比较大,下载时间比较长,请耐心等候。运行以下命令完成数据集下载:
python download.py --data_dir ./extra_train_ds/ --url https://github.com/wdimmy/Automatic-Corpus-Generation/raw/master/corpus/train.sgml
4. 预处理数据集
训练脚本要求训练集文件内容以句子对形式呈现,这里提供一个转换脚本,将Automatic Corpus Generation提供的XML文件转换成句子对形式的文件,运行以下命令:
python change_sgml_to_txt.py -i extra_train_ds/train.sgml -o extra_train_ds/train.txt
# 3. 下载数据集# Automatic Corpus Generation生成的中文纠错数据集比较大,下载时间比较长,请耐心等候。运行以下命令完成数据集下载:! python download.py --data_dir ./extra_train_ds/ --url https://github.com/wdimmy/Automatic-Corpus-Generation/raw/master/corpus/train.sgml
cd ~/work/text_correction/dataset/
/home/aistudio/work/text_correction/dataset
# 4. 预处理数据集# 训练脚本要求训练集文件内容以句子对形式呈现,这里提供一个转换脚本,将Automatic Corpus Generation提供的XML文件转换成句子对形式的文件,运行以下命令:! python change_sgml_to_txt.py -i extra_train_ds/train.sgml -o extra_train_ds/train1.txt
5. 模型训练
(1) 单卡训练
python train.py --batch_size 32 --logging_steps 100 --epochs 10 --learning_rate 5e-5 --model_name_or_path ernie-1.0 --output_dir ./checkpoints/ --extra_train_ds_dir ./extra_train_ds/ --max_seq_length 192
(2) 多卡训练
python -m paddle.distributed.launch --gpus "0,1" train.py --batch_size 32 --logging_steps 100 --epochs 10 --learning_rate 5e-5 --model_name_or_path ernie-1.0 --output_dir ./checkpoints/ --extra_train_ds_dir ./extra_train_ds/ --max_seq_length 192
# (1) 单卡训练%cd ~/work/text_correction ! python train.py --batch_size 32 --logging_steps 100 --epochs 10 --learning_rate 5e-5 --model_name_or_path ernie-1.0 \ --output_dir ./checkpoints/ --extra_train_ds_dir ./extra_train_ds/ --max_seq_length 192# (2) 多卡训练# ! python -m paddle.distributed.launch --gpus "0,1" train.py --batch_size 32 --logging_steps 100 --epochs 10 --learning_rate 5e-5 \# --model_name_or_path ernie-1.0 --output_dir ./checkpoints/ --extra_train_ds_dir ./extra_train_ds/ --max_seq_length 192
七、模型预测
预测SIGHAN测试集
SIGHAN 13,SIGHAN 14,SIGHAN 15是目前中文错别字纠错任务常用的benchmark数据。由于SIGHAN官方提供的是繁体字数据集,PaddleNLP将提供简体版本的SIGHAN测试数据。以下运行SIGHAN预测脚本:
sh run_sighan_predict.sh
该脚本会下载SIGHAN数据集,加载checkpoint的模型参数运行模型,输出SIGHAN测试集的预测结果到predict_sighan文件,并输出预测效果。
预测效果

| Metric | SIGHAN 13 | SIGHAN 14 | SIGHAN 15 |
|---|---|---|---|
| Detection F1 | 0.8348 | 0.6534 | 0.7464 |
| Correction F1 | 0.8217 | 0.6302 | 0.7296 |
八、 模型部署
1. 预测部署
(1) 模型导出
使用动态图训练结束之后,预测部署需要导出静态图参数,具体做法需要运行模型导出脚本export_model.py。以下是脚本参数介绍以及运行方式:
①参数
- params_path 是指动态图训练保存的参数路径。
- output_path 是指静态图参数导出路径。
- pinyin_vocab_file_path 指拼音表路径。
- model_name_or_path 目前支持的预训练模型有:"ernie-1.0"。
②运行方式
python export_model.py --params_path checkpoints/best_model.pdparams --output_path ./infer_model/static_graph_params
其中checkpoints/best_model.pdparams是训练过程中保存的参数文件,请更换为实际得到的训练保存路径。
2. 预测
导出模型之后,可以用于预测部署,predict.py文件提供了python预测部署示例。运行方式:
python predict.py --model_file infer_model/static_graph_params.pdmodel --params_file infer_model/static_graph_params.pdiparams
输出如下:
Source: 遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。Target: 遇到逆境时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。Source: 人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。Target: 人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。
③Taskflow一键预测
可以使用PaddleNLP提供的Taskflow工具来对输入的文本进行一键纠错,具体使用方法如下:
from paddlenlp import Taskflow
text_correction = Taskflow("text_correction")
text_correction('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。')'''
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。',
'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。',
'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
'''text_correction('人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。')'''
[{'source': '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。',
'target': '人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。',
'errors': [{'position': 18, 'correction': {'拙': '茁'}}]}]
'''
九、参考文献
- Ruiqing Zhang, Chao Pang et al. "Correcting Chinese Spelling Errors with Phonetic Pre-training", ACL, 2021
- DingminWang et al. "A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check", EMNLP, 2018




























