






本文围绕基于PaddlePaddle框架复现Tokens-to-Token ViT展开,先简介论文,指出ViT在中型数据集训练的不足,介绍T2T-ViT的T2T模块及实验。接着说明复现的T2T-ViT-7在ImageNet2012上的精度,还涉及数据集、环境依赖、快速开始步骤、复现过程及代码结构。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Tokens-to-Token ViT
- 一论文简介
- 二、复现精度
- 三、数据集
- 四、环境依赖
- 五、快速开始
- 六、复现过程
- 七、代码结构
本项目基于paddlepaddle框架复现Tokens-to-Token ViT
一、论文简介
1.1 背景
最近,人们探索了在语言建模中很流行的transformer,以解决视觉任务,例如,用于图像分类的视觉Transformer(ViT)。ViT模型将每个图像分成固定长度的tokens序列,然后应用多个Transformer层对它们的全局关系进行建模以进行分类。作者发现在中型数据集(例如 ImageNet)上从头开始训练时,ViT 与CNN相比性能较差。
- (1)输入图像的简单标记化无法对相邻像素之间的重要局部结构(例如,边缘,线条)建模,从而导致其训练样本效率低;
- (2)ViT的冗余注意力骨干网设计导致固定计算预算中有限的功能丰富性和有限的训练样本

绿色的框中表示了模型学到的一些诸如边缘和线条的low-level structure feature,红色框则表示模型学到了不合理的feature map,这些feature或者接近于0,或者是很大的值。从这个实验可以进一步证实,CNN会从图像的低级特征学起,这个在生物上是说得通的,但是通过可视化来看,ViT的问题确实不小,且不看ViT有没有学到低级的特征,后面的网络层的feature map甚至出现了异常值,这个是有可能导致错误的预测的,同时反映了ViT的学习效率差。
1.2 方法
为了克服这些限制,作者提出了一种新的 Tokens 到 Token 视觉 Transformer(T2T-ViT),逐层 Tokens 到 Token(T2T)转换,以通过递归聚集相邻对象逐步将图像结构化为 Tokens 变成一个 Token ,这样就可以对周围 Token 表示的局部结构进行建模,并可以减少 Token 长度。
- Tokens-to-Token(T2T)模块旨在克服ViT中简单Token化机制的局限性,它采用渐进式方式将图像结构化为 Token 并建模局部结构信息;
- 而 Tokens 的长度可以通过渐进式迭代降低,每个 T2T 过程包含两个步骤:Restructurization 与 SoftSplit,见下图。
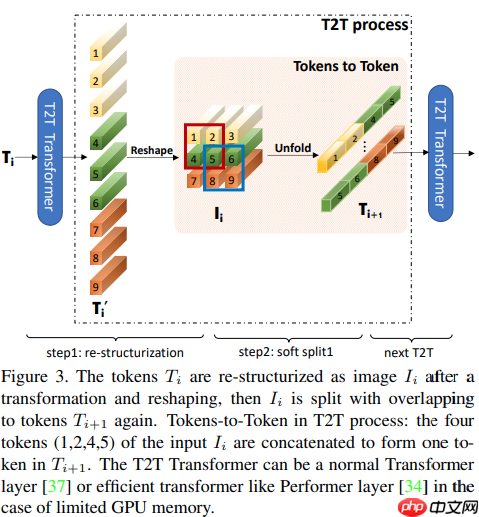
(1) Re-structurization
假设上一个网络层的输出为T,T经过Transformer层得到T',Transformer是包括mutil-head self-attention和MLP的,因此从T到T'可以表示为T' = MLP(MSA(T)),这里MSA表示mutil-head self-attention,MLP表示多层感知机,上述两个操作后面都省略了LN。经过Transformer层后输出也是token的序列,为了重构局部的信息,首先把它还原为原来的空间结构,即从一维reshape为二维,记作I。I = Reshape(T'),reshape操作就完成了从一维的向量到二维的重排列。整个操作可以参见上图的step1。
(2)Soft Split
与ViT那种hard split不同,T2T-ViT采用了soft split,说直白点就是不同的分割部分会有overlapping。I会被split为多个patch,然后每个patch里面的tokens会拼接成一个token,也就是这篇论文的题目tokens to token,这个步骤也是最关键的一个步骤,因为这个步骤从图像中相邻位置的语义信息聚合到一个向量里面。同时这个步骤会使tokens序列变短,单个token的长度会变长,符合CNN-based模型设计的经验deep-narrow。
T2T module
在T2T模块中,依次通过Re-structurization和Soft Split操作,会逐渐使tokens的序列变短。整个T2T模块的操作可以表示如下: 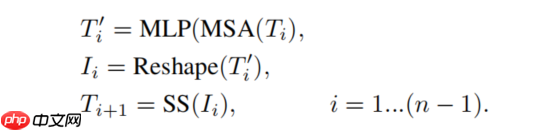
由于是soft split所以tokens的序列长度会比ViT大很多,MACs和内存占用都很大,因此对于T2T模块来说,只能减小通道数,这里的通道数可以理解为embedding的维度,还使用了Performer[2]来进一步减少内存的占用。
1.3 实验
论文:
- [1] Yuan L, Chen Y, Wang T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[J]. arXiv preprint arXiv:2101.11986, 2021.
- 链接:https://arxiv.org/abs/2101.11986
参考项目
- https://github.com/yitu-opensource/T2T-ViT
二、复现精度
复现的模型是论文中的T2T-ViT-7。在ImageNet2012上的精度为71.7%。
目标精度:71.7% 实现:71.56%。
模型在项目中可以下载,也可以前往github:https://github.com/zhl98/T2T_paddle 中下载代码和模型。
| 网络 | steps | opt | image_size | batch_size | dataset | epoch | params_size |
|---|---|---|---|---|---|---|---|
| t2t-vit | 1252 | AdamW | 224x224 | 1024 | ImageNet | 320 | 16.45MB |
三、数据集
数据集使用ImageNet 2012的训练数据集,有1000类,大小为144GB
- 训练集: 1281167张
- 测试集: 50000张
因为硬盘只有100g因此这里无法进行训练,如想体验训练过程必须在脚本任务中:https://aistudio.baidu.com/aistudio/datasetdetail/79807
四、环境依赖
- 硬件:GPU\CPU
- 框架:
- PaddlePaddle >=2.0.0
五、快速开始
step1:克隆本项目
git clone https://github.com/zhl98/T2T_paddle.git cd T2T_paddle
step2:修改代码参数
修改/config/t2t_vit_7.yaml中的数据集路径
项目中默认使用lit_data中的路径进行测试
修改/config/t2t_vit_7.yaml中的参数信息,比如学习率,epoch大小等。 
step3:训练模型
运行sh文件,在文件中可以选择单卡或是多卡训练
bash ./scripts/train.sh
部分训练日志如下所示。

Epoch [98/200], Step [300/1252], Loss: 1.4250,acc: 0.6624, read_time: 0.0069, train_time: 0.4234, lr: 0.0009Epoch [98/200], Step [400/1252], Loss: 1.4264,acc: 0.6627, read_time: 0.0037, train_time: 0.3946, lr: 0.0009
step4:验证模型
bash ./scripts/val.sh
部分验证日志如下所示。
Step [180/196], acc: 0.7163, read_time: 1.4773Step [190/196], acc: 0.7157, read_time: 1.1667ImageNet final val acc is:0.7156
step5:验证预测
python ./tools/predict.py

输出结果为
class_id is: 923
对照lit_data中的标签,可知预测正确
六、复现过程
步骤一:将torch模型转化成paddle模型
由于PyTorch的API和PaddlePaddle的API非常相似,可以参考PyTorch-PaddlePaddle API映射表
步骤二:用paddle编写训练代码
比如dataloader需要使用paddle.io.Dataloader.
学习率中torch和paddle有如下区别:

- 在Paddle中,先设置学习率,然后将学习率传入优化器中;
- 而在Pytorch中,先设置优化器,然后再把优化器传给学习率
损失函数使用了 paddle.nn.CrossEntropyLoss()
由于是简单的图片分类问题,评估指标是分类准确度。
步骤三:模型训练
我的训练过程可以看github上的log文件夹下的信息,github上也给出了每个log代表的意义。
由于aistudio上的脚本任务最多只能运行72个小时,把训练过程分成多个步骤进行训练。
- train-0-(1).log是在aistudio上4块Tesla V100,batch_size为256*4 lr:采用先上升,在下降。从0.0002-线性上升到0.0010,再依次下降0.0005
- train-0-(2).log环境是2块2080ti , batch_size为128*2
- train-0-(3).log环境是2块TITAN24G,batch_size为2562 log中包含了多次训练过程, lr最后一次采用 0.000075
- trainer-0-(4).log是最后在一块2080ti上训练的过程,最后导出了最好的模型,batch_size为128,避免了多块卡上验证精度不同的问题。 lr也是逐步下降,最后为0.000005
- trainer-0-信息不全.log 是在一开始跑的,跑了250个epoch已经很接近结果了,但是因为aistudio只能运行72小时,然后模型也没保存,学习率等参数也没打印出来,lr为一直不变的0.00002,batch_size为256*4
- val-workerlog.0 是最后在一块卡上的验证结果,可以用来参考验收
参数的设置
- batchsize:原作者使用的1024的batchszie做训练,而我在本地跑的时候并不能达到这个,只有在aistudio上能实现1024,具体不同环境下的batchsize上面都有提及。
- 多卡训练:在多卡训练的时除了要加上,还要在dataloader上修改:
train_sampler = DistributedBatchSampler(dataset_train, batch_size = config.TRAIN_BATCH_SIZE, drop_last=False,shuffle=True )
- 迭代次数:作者给的epoch是310次,实际根据训练的过程来看
- 学习率:作者原本采用的是warmup,先从0开始线性增加,在5个epoch增到一个0.001后,线性降低到0.0005。因为学习率还和batchsize等参数相关,在调整batchsize的过程中要记得响应的调整学习率的大小。一般来说,让学习率和batch成正比。
遇到的问题
原本由于对paddle的api使用不熟练,发现在多卡训练的验证模型时,不同卡上的验证精度不一致,导致无法有效判断模型的好坏,还得在单卡上进行最后的验证。
paddle.distributed.all_gather(all_Y, Y)
这样可以把不同卡上的输出结果都收集起来,这个和torch有些区别,记得注意。
七、代码结构
|-- T2T_ViT_Paddle |-- log #日志 | |-- trainer-0-信息不全.log
| |-- val-workerlog.0 #验证实验结果 | |-- trainer-0-(1).log #有时间信息 第一步 | |-- trainer-0-(2).log # 第二步训练 | |-- trainer-0-(3).log # 第三步训练 | |-- trainer-0-(4).log # 在单卡上训练模型 |-- config #参数 | |-- t2t_vit_7.yaml
|-- lit_data #数据目录 |-- output #模型目录 |-- scripts #运行脚本 | |-- eval.sh | |-- train.sh |-- tools #源码文件 |-- common.py #基础类的封装 |-- dataset.py #数据集的加载 |-- scheduler.py #学习率的跟新 |-- t2t.py #网络模型定义
|-- train.py #训练代码 |-- val.py #验证代码 |-- predict.py #预测代码 |-- config.py #参数代码 |-- README.md
|-- requirements.txt |-- LICENSE 



























