






本文提出动态混合视觉变压器(DHVT),以解决小数据集上视觉Transformer因缺乏归纳偏置导致的性能差距。DHVT通过串联重叠Patch嵌入增强空间相关性,动态聚合前馈网络和相互作用多头自注意优化通道表示。在CIFAR-100和ImageNet-1K上,以轻量参数实现先进性能,且代码复现验证了其有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

摘要
在小数据集上从头开始训练时,视觉Transformer和卷积神经网络之间仍然存在着巨大的性能差距,这是由于缺乏归纳偏置造成的。 在本文中,我们进一步考虑了这一问题,并指出了ViTs在归纳偏置下的两个弱点,即空间相关性和不同的通道表示。 首先,在空间方面,对象具有局部紧凑性和相关性,因此需要从令牌及其邻域中提取细粒度特征。 而数据的缺乏则阻碍了VITS参与空间相关性的研究。 第二,在通道方面,不同通道的表征呈现出多样性。 但是由于数据的稀少,使得VITS无法学习到足够强的表示来进行准确的识别。 为此,我们提出了动态混合视觉变压器(DHVT)作为增强两种归纳偏置的解决方案。 在空间方面,我们采用了一种混合结构,将卷积融合到Patch嵌入和多层感知器模块中,强制模型捕获令牌及其邻近特征。 在通道方面,我们在MLP中引入了动态特征聚合模块,在多头自关注模块中引入了全新的“头令牌”设计,以帮助重新校准通道表示,并使不同的通道组表示相互影响。 弱通道表示的融合形成了足够强的分类表示。 通过这种设计,我们成功地消除了CNNS和VITS之间的性能差距,我们的DHVT在轻量级模型上实现了一系列最先进的性能,CIFAR-100在22.8M参数上实现了85.68%的性能,ImageNet-1K在24.0M参数上实现了82.3%的性能。
1. DHVT
本文针对ViT缺乏空间相关性和多样的通道表示这两个弱点,提出了一种新的Transformer架构——DHVT,DHVT的总体框架如图1所示,采用的与ViT架构相同,没有使用分层架构。

1.1 串联重叠的Patch嵌入(Sequential Overlapping Patch Embedding,SOPE)
改进后的补丁嵌入称为Sequential overlap patch embedding(SOPE),它包含了3×3步长s=2的卷积、BN和GELU激活的几个连续卷积层。卷积层数与patch大小的关系为P=2^k。SOPE能够消除以前嵌入模块带来的不连续性,保留重要的底层特征。它能在一定程度上提供位置信息。在一系列卷积层前后分别采用两次仿射变换。该操作对输入特征进行了缩放和移位,其作用类似于归一化,使训练性能在小数据集上更加稳定。SOPE的整个流程可以表述如下:
Aff(x)=Diag(α)x+βGi(x)=GELU(BN(Conv(x))),i=1,…,kSOPE(x)=Reshape(Aff(Gk(…(G2(G1(Aff(x)))))))
这里的α和β为可学习参数,分别初始化为1和0。
1.2 动态聚合前馈 (Dynamic Aggregation Feed Forward,DAFF)
ViT 中的普通前馈网络 (FFN) 由两个全连接层和 GELU 组成。DAFF 在 FFN 中集成了来自 MobileNetV1 的深度卷积 (DWConv)。由于深度卷积带来的归纳偏置,模型被迫捕获相邻特征,解决了空间视图上的问题。它极大地减少了在小型数据集上从头开始训练时的性能差距,并且比标准 CNN 收敛得更快。还使用了与来自 SENet 的 SE 模块类似的机制。Xc、Xp 分别表示类标记和补丁标记。类标记在投影层之前从序列中分离为 Xc。剩余的令牌 Xp 则通过一个内部有残差连接的深度集成多层感知器。然后将输出的补丁标记平均为权重向量 W。在squeeze-excitation操作之后,输出权重向量将与类标记通道相乘。然后重新校准的类令牌将与输出补丁令牌以恢复令牌序列,DAFF的SE操作可以表述如下:
W=Linear(GELU( Linear (( Average (Xp))))Xc=Xc⊙W


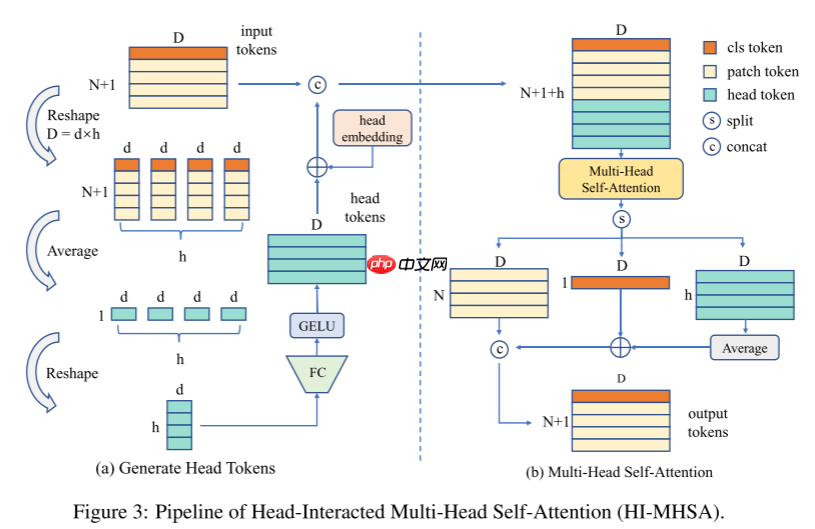
1.3 相互作用多头自注意(HI-MHSA)
在最初的MHSA模块中,每个注意头都没有与其他头交互。在缺乏训练数据的情况下,每个通道组的表征都太弱而无法识别。在HI-MHSA中,每个d维令牌,包括类令牌,将被重塑为h部分。每个部分包含d个通道,其中d =d×h。所有分离的标记在它们各自的部分中取平均值。因此总共得到h个令牌,每个令牌都是d维的。所有这样的中间令牌将再次投影到d维,总共产生h个头部令牌,头令牌的生成过程如下所示:
然后将头令牌与类令牌和Patch令牌合并,并使用原始的多头注意力进行交互,最后对头令牌进行平均池化操作,并将其与类令牌相加,以增强类令牌的判别能力,整体架构如图3所示。
2. 代码复现
2.1 下载并导入所需的库
!pip install einops-0.3.0-py3-none-any.whl
%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport itertoolsfrom einops.layers.paddle import Rearrangeimport mathfrom functools import partial
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)2.4.3 DAFF
class DAFF(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,
kernel_size=3, with_bn=True):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features # pointwise
self.conv1 = nn.Conv2D(in_features, hidden_features, kernel_size=1, stride=1, padding=0) # depthwise
self.conv2 = nn.Conv2D(
hidden_features, hidden_features, kernel_size=kernel_size, stride=1,
padding=(kernel_size - 1) // 2, groups=hidden_features)
# pointwise
self.conv3 = nn.Conv2D(hidden_features, out_features, kernel_size=1, stride=1, padding=0)
self.act = act_layer()
self.bn1 = nn.BatchNorm2D(hidden_features)
self.bn2 = nn.BatchNorm2D(hidden_features)
self.bn3 = nn.BatchNorm2D(out_features)
# The reduction ratio is always set to 4
self.squeeze = nn.AdaptiveAvgPool2D((1, 1))
self.compress = nn.Linear(in_features, in_features//4)
self.excitation = nn.Linear(in_features//4, in_features)
def forward(self, x):
B, N, C = x.shape
cls_token, tokens = paddle.split(x, [1, N - 1], axis=1)
x = tokens.reshape((B, int(math.sqrt(N - 1)), int(math.sqrt(N - 1)), C)).transpose([0, 3, 1, 2])
x = self.conv1(x)
x = self.bn1(x)
x = self.act(x)
shortcut = x
x = self.conv2(x)
x = self.bn2(x)
x = self.act(x)
x = shortcut + x
x = self.conv3(x)
x = self.bn3(x)
weight = self.squeeze(x).flatten(1).reshape((B, 1, C))
weight = self.excitation(self.act(self.compress(weight)))
cls_token = cls_token * weight
tokens = x.flatten(2).transpose([0, 2, 1])
out = paddle.concat((cls_token, tokens), axis=1)
return out2.4.4 HI-MHSA
class HI_Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.act = nn.GELU()
self.ht_proj = nn.Linear(dim//self.num_heads, dim, bias_attr=True)
self.ht_norm = nn.LayerNorm(dim//self.num_heads)
self.pos_embed = self.create_parameter(shape=(1, self.num_heads, dim), default_initializer=nn.initializer.TruncatedNormal(std=.02))
def forward(self, x):
B, N, C = x.shape
H = W =int(math.sqrt(N-1)) # head token
head_pos = paddle.expand(self.pos_embed, shape=(x.shape[0], -1, -1))
x_ = x.reshape((B, -1, self.num_heads, C // self.num_heads)).transpose([0, 2, 1, 3])
x_ = paddle.mean(x_, axis=2, keepdim=True) # now the shape is [B, h, 1, d//h]
x_ = self.ht_proj(x_).reshape((B, -1, self.num_heads, C // self.num_heads))
x_ = self.act(self.ht_norm(x_)).flatten(2)
x_ = x_ + head_pos
x = paddle.concat([x, x_], axis=1)
# normal mhsa
qkv = self.qkv(x).reshape((B, N+self.num_heads, 3, self.num_heads, C // self.num_heads)).transpose([2, 0, 3, 1, 4])
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape((B, N+self.num_heads, C))
x = self.proj(x)
# merge head tokens into cls token
cls, patch, ht = paddle.split(x, [1, N-1, self.num_heads], axis=1)
cls = cls + paddle.mean(ht, axis=1, keepdim=True)
x = paddle.concat([cls, patch], axis=1)
x = self.proj_drop(x) return xclass DHVT_Block(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., qk_scale=None,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = HI_Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias,attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = DAFF(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop, kernel_size=3)
self.mlp_hidden_dim = mlp_hidden_dim def forward(self, x):
B, N, C = x.shape
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass Affine(nn.Layer):
def __init__(self, dim):
super().__init__()
self.alpha = self.create_parameter(shape=[1, dim, 1, 1], default_initializer=nn.initializer.Constant(1.0))
self.beta = self.create_parameter(shape=[1, dim, 1, 1], default_initializer=nn.initializer.Constant(0.0)) def forward(self, x):
x = x * self.alpha + self.beta return xdef to_2tuple(x):
return (x, x)def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Sequential(
nn.Conv2D(
in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias_attr=False
),
nn.BatchNorm2D(out_planes)
)class ConvPatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, init_values=1e-2):
super().__init__()
ori_img_size = img_size
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
if patch_size[0] == 16:
self.proj = nn.Sequential(
conv3x3(3, embed_dim // 8, 2),
nn.GELU(),
conv3x3(embed_dim // 8, embed_dim // 4, 2),
nn.GELU(),
conv3x3(embed_dim // 4, embed_dim // 2, 2),
nn.GELU(),
conv3x3(embed_dim // 2, embed_dim, 2),
) elif patch_size[0] == 4:
self.proj = nn.Sequential(
conv3x3(3, embed_dim // 2, 2),
nn.GELU(),
conv3x3(embed_dim // 2, embed_dim, 2),
) elif patch_size[0] == 2:
self.proj = nn.Sequential(
conv3x3(3, embed_dim, 2),
nn.GELU(),
) else: raise("For convolutional projection, patch size has to be in [2, 4, 16]")
self.pre_affine = Affine(3)
self.post_affine = Affine(embed_dim) def forward(self, x):
B, C, H, W = x.shape
x = self.pre_affine(x)
x = self.proj(x)
x = self.post_affine(x)
Hp, Wp = x.shape[2], x.shape[3]
x = x.flatten(2).transpose([0, 2, 1]) return xclass DHVT(nn.Layer):
def __init__(self, img_size=32, patch_size=16, in_chans=3, num_classes=100, embed_dim=768, depth=12, num_heads=12,
mlp_ratio=4., qkv_bias=True, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=None, act_layer=None):
super().__init__()
self.img_size = img_size
self.depth = depth
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.num_tokens = 1
norm_layer = norm_layer or partial(nn.LayerNorm, epsilon=1e-6)
act_layer = act_layer or nn.GELU
# Patch Embedding
self.patch_embed = ConvPatchEmbed(img_size=img_size, embed_dim=embed_dim, patch_size=patch_size)
self.cls_token = self.create_parameter(shape=(1, 1, embed_dim), default_initializer=nn.initializer.TruncatedNormal(std=.02))
self.pos_drop = nn.Dropout(drop_rate)
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.LayerList([
DHVT_Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer) for i in range(depth)])
self.norm = norm_layer(embed_dim) # Classifier head(s)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self.init_weights) def init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=0.02)
zero = nn.initializer.Constant(0.0)
one = nn.initializer.Constant(1.0)
km = nn.initializer.KaimingNormal() if isinstance(m, nn.Linear):
tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zero(m.bias) elif isinstance(m, nn.LayerNorm):
zero(m.bias)
one(m.weight) elif isinstance(m, nn.Conv2D):
km(m.weight) if m.bias is not None:
zero(m.bias)
def forward_features(self, x):
B, _, h, w = x.shape
x = self.patch_embed(x)
cls_token = self.cls_token.expand([x.shape[0], -1, -1]) # stole cls_tokens impl from Phil Wang, thanks
x = paddle.concat((cls_token, x), axis=1)
for i, blk in enumerate(self.blocks):
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x) return xnum_classes = 10def dhvt_tiny_cifar_patch4():
model = DHVT(img_size=32, patch_size=4, embed_dim=192, depth=12, num_heads=4, mlp_ratio=4, num_classes=num_classes) return modeldef dhvt_small_cifar_patch4():
model = DHVT(img_size=32, patch_size=4, embed_dim=384, depth=12, num_heads=8, mlp_ratio=4, num_classes=num_classes) return modeldef dhvt_tiny_cifar_patch2():
model = DHVT(img_size=32, patch_size=2, embed_dim=192, depth=12, num_heads=4, mlp_ratio=4, num_classes=num_classes) return modeldef dhvt_small_cifar_patch2():
model = DHVT(img_size=32, patch_size=2, embed_dim=384, depth=12, num_heads=8, mlp_ratio=4, num_classes=num_classes) return model2.3.5 模型的参数
model = dhvt_tiny_cifar_patch2() paddle.summary(model, (1, 3, 32, 32))

2.4 训练
learning_rate = 0.001n_epochs = 50paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# DHVT-T-2model = dhvt_tiny_cifar_patch2()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>
import time
work_path = 'work/model'model = dhvt_tiny_cifar_patch2()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))Throughout:976
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axeswork_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = dhvt_tiny_cifar_patch2() model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 32, 32, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<Figure size 2700x150 with 18 Axes>





























