我们该如何优化 Meta 的「分割一切」模型,PyTorch 团队撰写的这篇博客由浅入深的帮你解答。
从年初到现在,生成式 AI 发展迅猛。但很多时候,我们又不得不面临一个难题:如何加快生成式 AI 的训练、推理等,尤其是在使用 PyTorch 的情况下。本文 PyTorch 团队的研究者为我们提供了一个解决方案。文章重点介绍了如何使用纯原生 PyTorch 加速生成式 AI 模型,此外,文章还介绍了 PyTorch 新功能,以及如何组合这些功能的实际示例。结果如何呢?PyTorch 团队表示,他们重写了 Meta 的「分割一切」 (SAM) 模型,从而使代码比原始实现快 8 倍,并且没有损失准确率,所有这些都是使用原生 PyTorch 进行优化的。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

博客地址:https://pytorch.org/blog/accelerating-generative-ai/
- Torch.compile:PyTorch 模型编译器, PyTorch 2.0 加入了一个新的函数,叫做 torch.compile (),能够通过一行代码对已有的模型进行加速;
- SDPA(Scaled Dot Product Attention ):内存高效的注意力实现方式;
- 半结构化 (2:4) 稀疏性:一种针对 GPU 优化的稀疏内存格式;
- Nested Tensor:Nested Tensor 把 {tensor, mask} 打包在一起,将非均匀大小的数据批处理到单个张量中,例如不同大小的图像;
- Triton 自定义操作:使用 Triton Python DSL 编写 GPU 操作,并通过自定义操作符注册轻松将其集成到 PyTorch 的各种组件中。
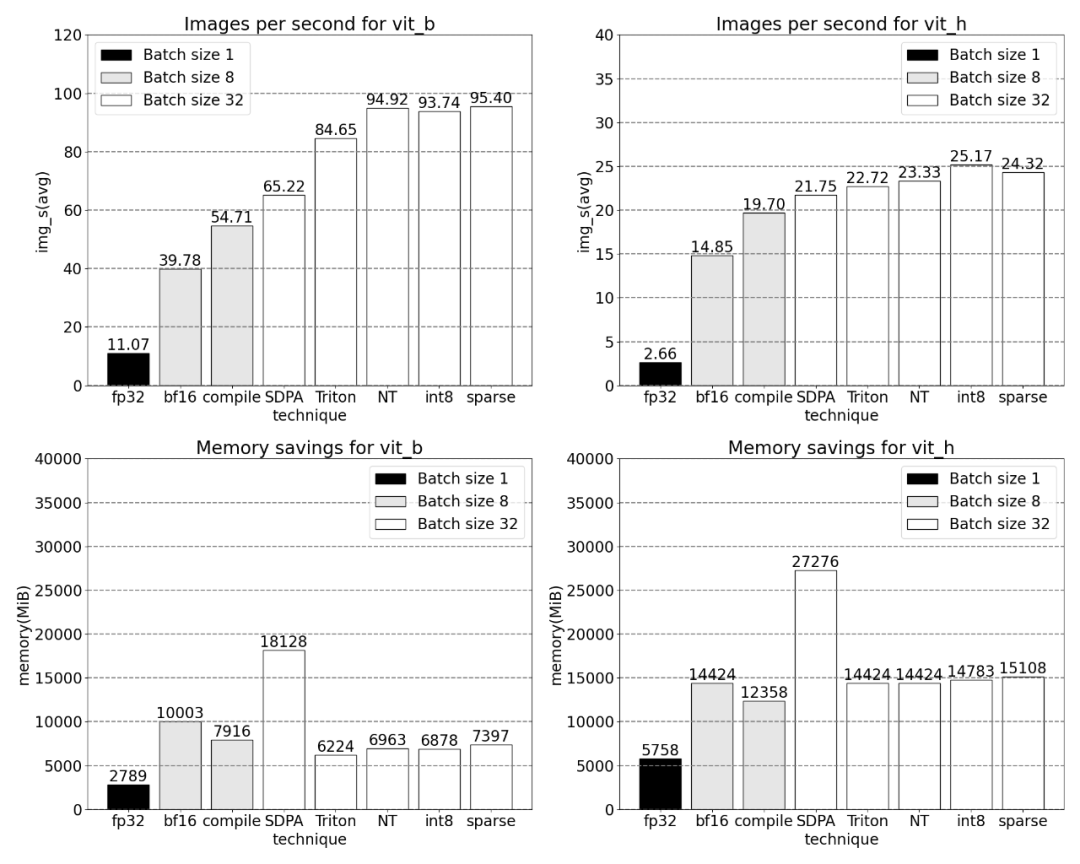
PyTorch 原生特性所带来的吞吐量增加以及减少的内存开销。

接下来,文章介绍了 SAM 优化过程,包括性能分析、瓶颈识别,以及如何将这些新功能整合进 PyTorch 以解决 SAM 面临的这些问题。除此以外,本文还介绍了 PyTorch 的一些新特性:torch.compile、SDPA、Triton kernels、Nested Tensor 以及 semi-structured sparsity(半结构化稀疏)。本文内容逐层深入,文章的最后会介绍快速版 SAM,感兴趣的小伙伴可以去 GitHub 上下载,此外,本文还通过 Perfetto UI 对这些数据进行了可视化,以此来阐释 PyTorch 每项特性的应用价值。GitHub 地址:https://github.com/pytorch-labs/segment-anything-fast该研究表示,本文利用的 SAM 基线数据类型为 float32 dtype、batch 大小为 1,使用 PyTorch Profiler 查看内核跟踪的结果如下: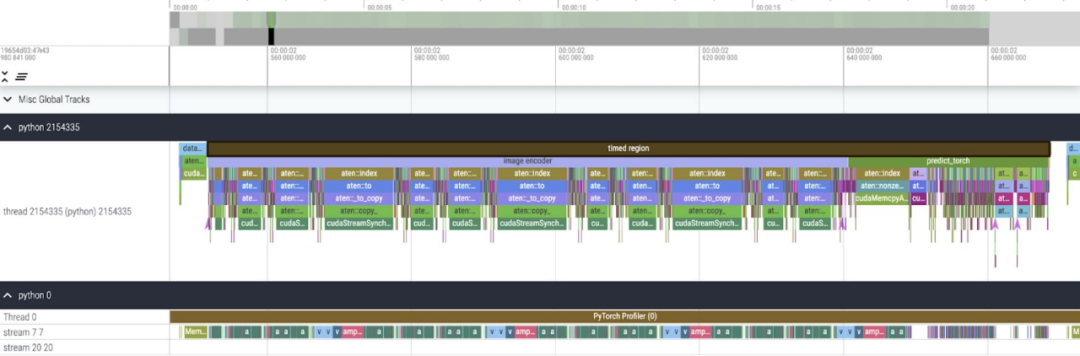
第一个是对 aten::index 的长调用,这是由张量索引操作(例如 [])产生的底层调用导致的。然而实际上 GPU 花费在 aten::index 上的时间相对较低,原因在于 aten::index 在启动两个内核的过程中,两者之间发生了阻塞 cudaStreamSynchronize。这意味着 CPU 会等待 GPU 完成处理,直到启动第二个内核。因而为了优化 SAM,本文认为应该致力于消除导致空闲时间的阻塞 GPU 同步。第二个是 SAM 在矩阵乘法中花费了大量的 GPU 时间(上图中的深绿色),这在 Transformers 中很常见。如果能够减少 SAM 模型在矩阵乘法上花费的 GPU 时间,我们就可以显着加快 SAM 的速度。接下来本文用 SAM 的吞吐量 (img/s) 和内存开销 (GiB) 来建立基线。之后就是优化过程了。
Bfloat16 半精度(加上 GPU 同步和批处理)为了解决上述问题,即让矩阵乘法花费的时间更少,本文转向 bfloat16。Bfloat16 是常用的半精度类型,通过降低每个参数和激活的精度,能够节省大量的计算时间和内存。
此外,为了移除 GPU 同步,本文发现有两个位置可以优化。

具体来说(参考上图更容易理解,出现的变量名都在代码中),该研究发现在 SAM 的图像编码器中,有充当坐标缩放器(coordinate scalers)的变量 q_coords 和 k_coords,这些变量都是在 CPU 上分配和处理的。然而,一旦这些变量被用来在 rel_pos_resized 中建立索引,这些索引操作就会自动的将这些变量移动到 GPU 上,这种复制会导致 GPU 同步。为了解决上述问题,该研究注意到可以使用 torch.where 重写这部分内容来解决问题,如上所示。在应用了这些更改之后,本文注意到单个内核调用之间有着显著的时间间隔,尤其在小批量(这里为 1)时更为突出。为了更深入的了解这一现象,本文开始对批大小为 8 的 SAM 推理进行性能分析: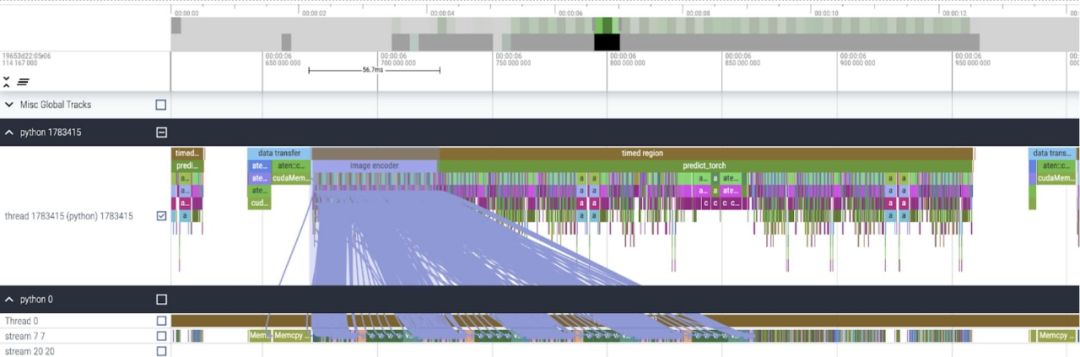
在查看每个内核所花费的时间时,本文观察到 SAM 的大部分 GPU 时间都花费在逐元素内核(elementwise kernels)和 softmax 操作上。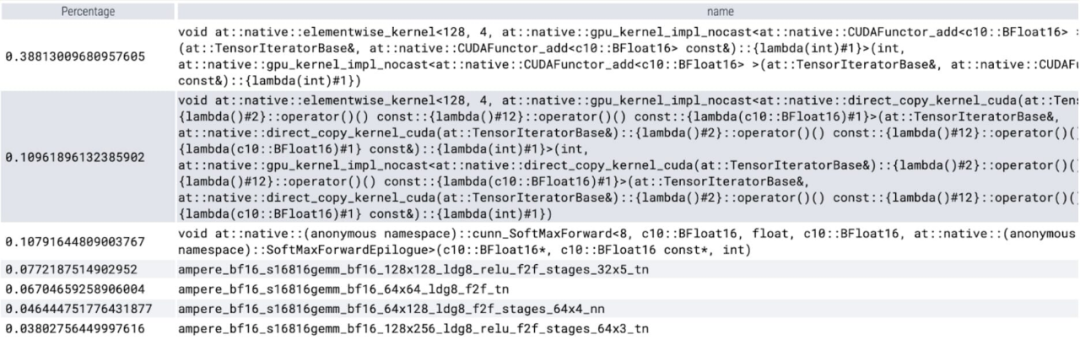
将 GPU 同步和 bfloat16 优化结合在一起,SAM 性能提高了 3 倍。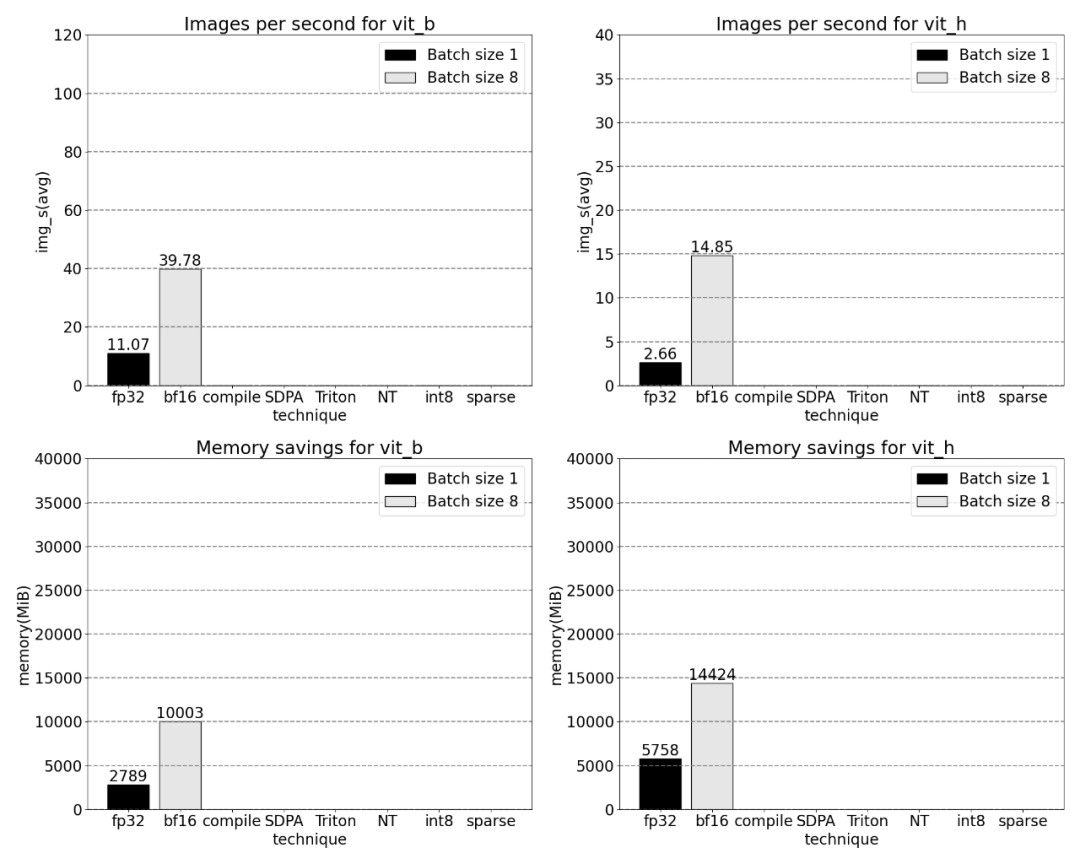
Torch.compile(+graph breaks 和 CUDA graphs)本文发现在深入研究 SAM 的过程中有很多小的操作,他们认为使用编译器来融合操作有很大的好处,因而 PyTorch 对 torch.compile 做了以下优化:
- 将 nn.LayerNorm 或 nn.GELU 等操作序列融合成一个单一的 GPU 内核;
- 融合紧跟在矩阵乘法内核之后的操作,以减少 GPU 内核调用的数量。
通过这些优化,该研究减少了 GPU 全局内存往返次数(roundtrips),从而加快了推理速度。我们现在可以在 SAM 的图像编码器上尝试 torch.compile。为了最大限度地提高性能,本文使用了一些高级编译技术:
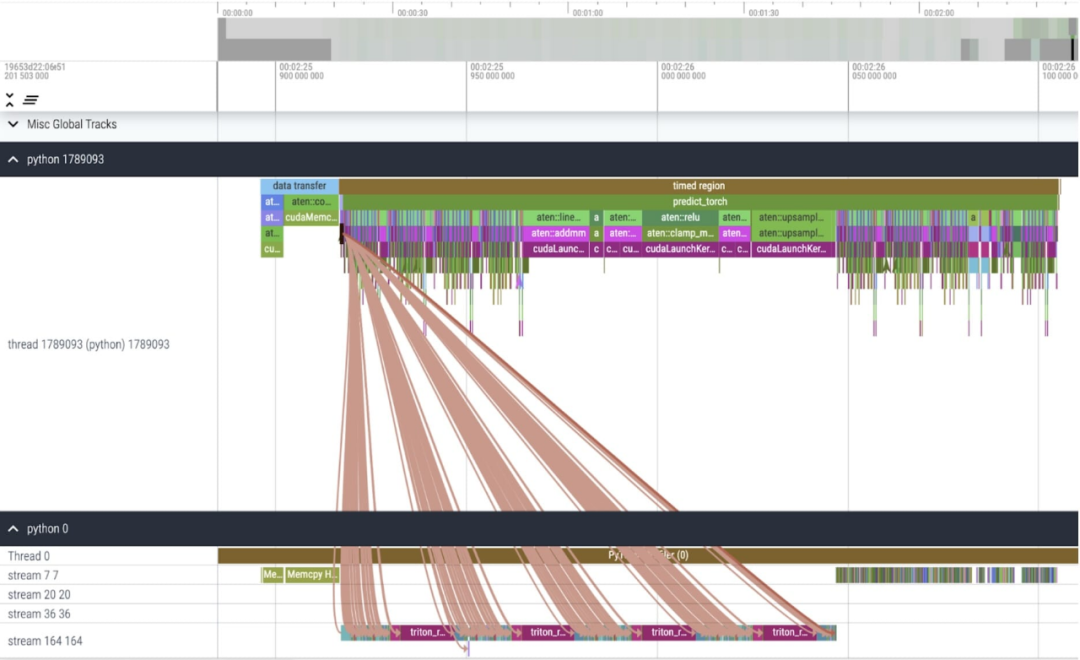
结果显示,torch.compile 工作得很好。 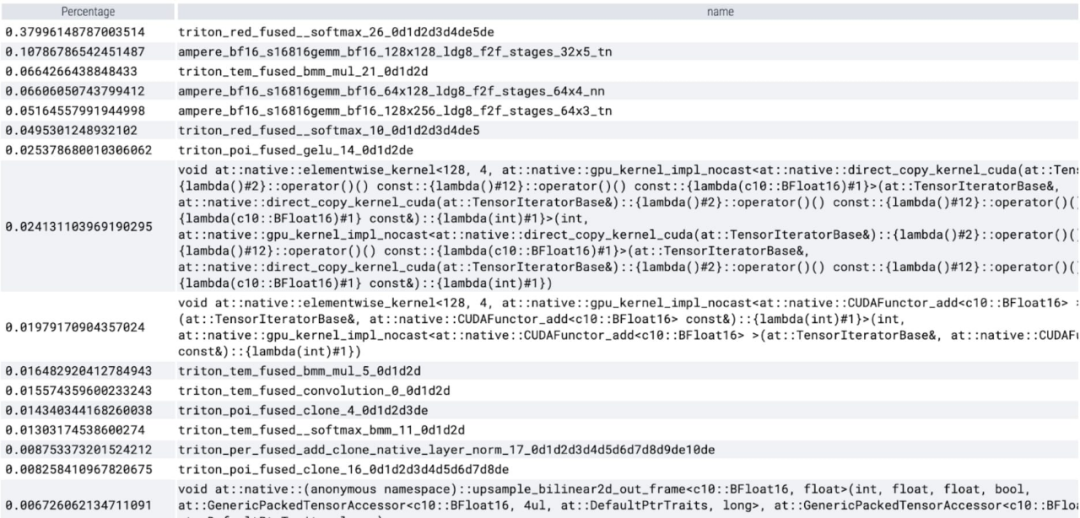
可以观察到 softmax 占了很大一部分时间,然后是各种 GEMM 变体。以下测量的是批大小为 8 及以上的变化。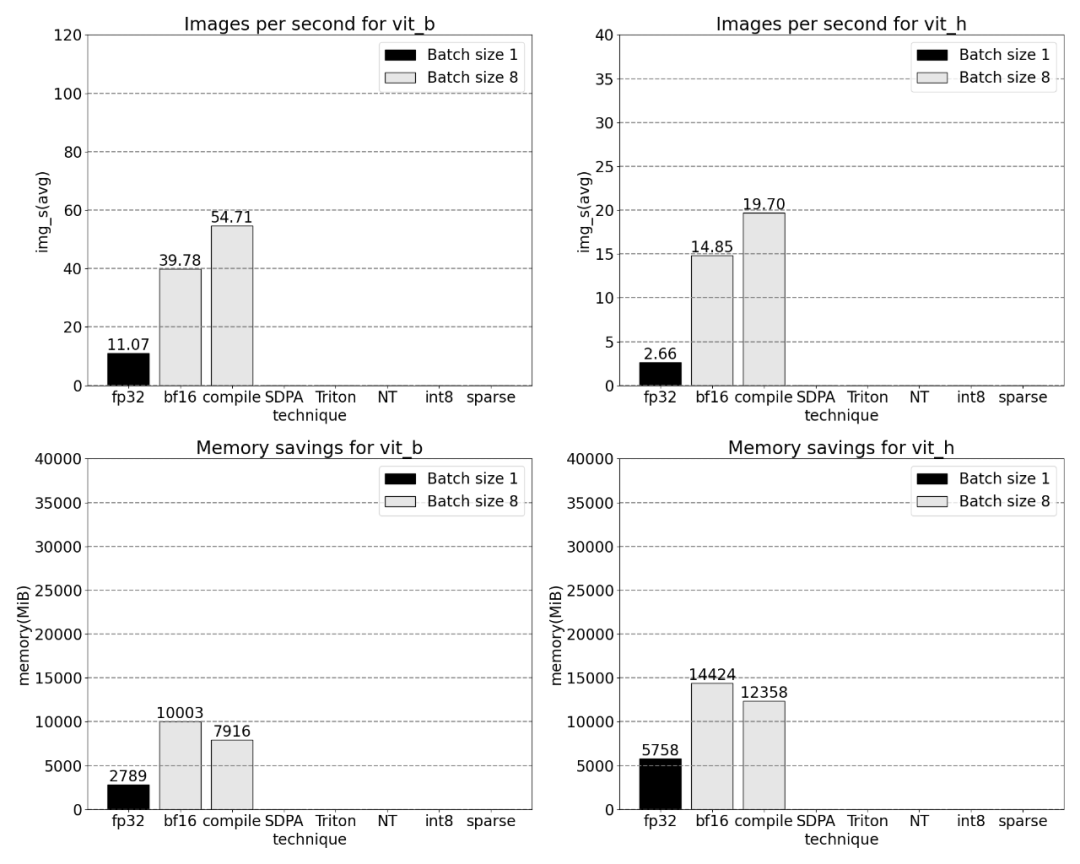
SDPA: scaled_dot_product_attention接下来,本文又对 SDPA(scaled_dot_product_attention)进行了实验,研究的重点是注意力机制。一般来讲,原生注意力机制在时间和内存上随序列长度呈二次方扩展。PyTorch 的 SDPA 操作基于 Flash Attention、FlashAttentionV2 和 xFormer 的内存高效注意力原理构建,可以显着加快 GPU 注意力。与 torch.compile 相结合,这个操作允许在 MultiheadAttention 的变体中表达和融合一个共同的模式。经过一小部分更改后,现在模型可以使用 scaled_dot_product_attention。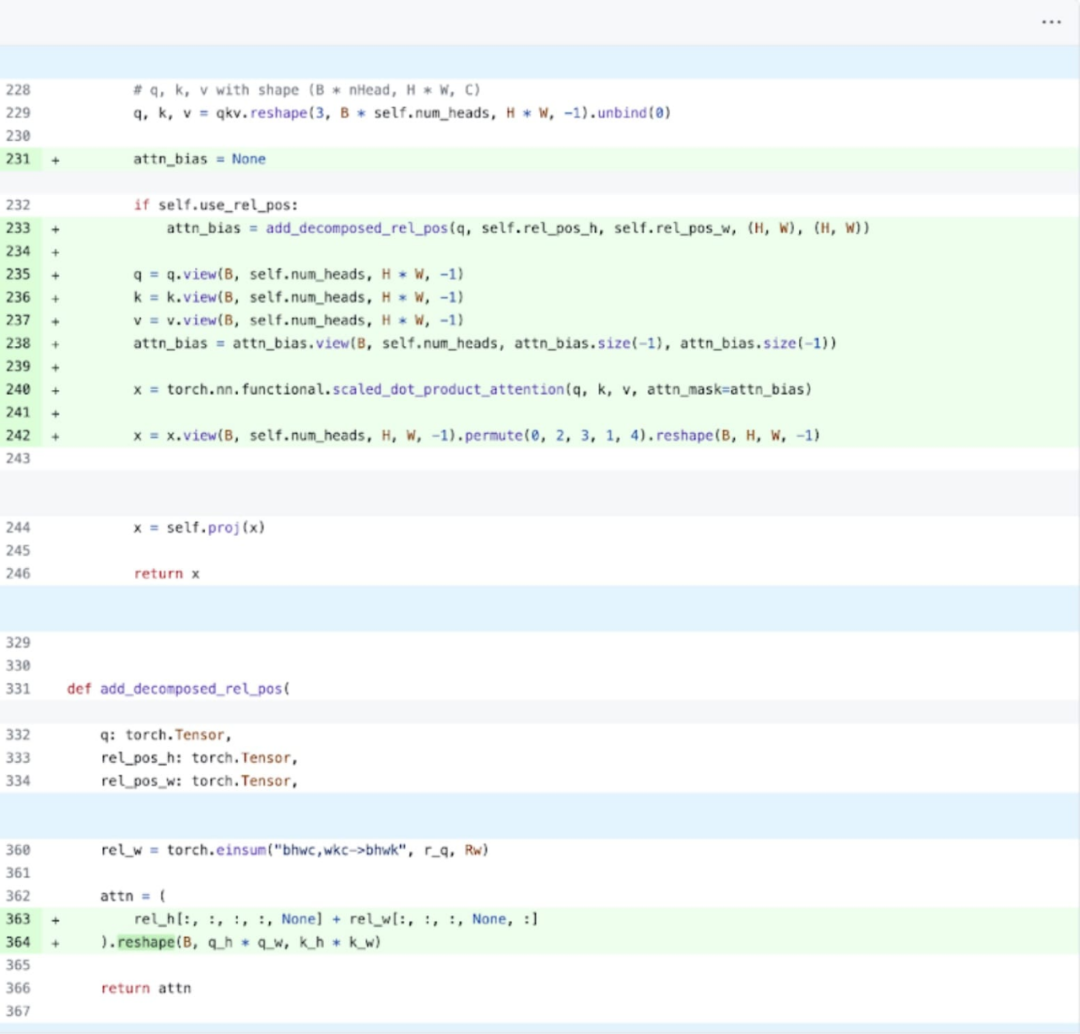
现在可以看到内存高效的注意力内核占用了 GPU 上大量的计算时间: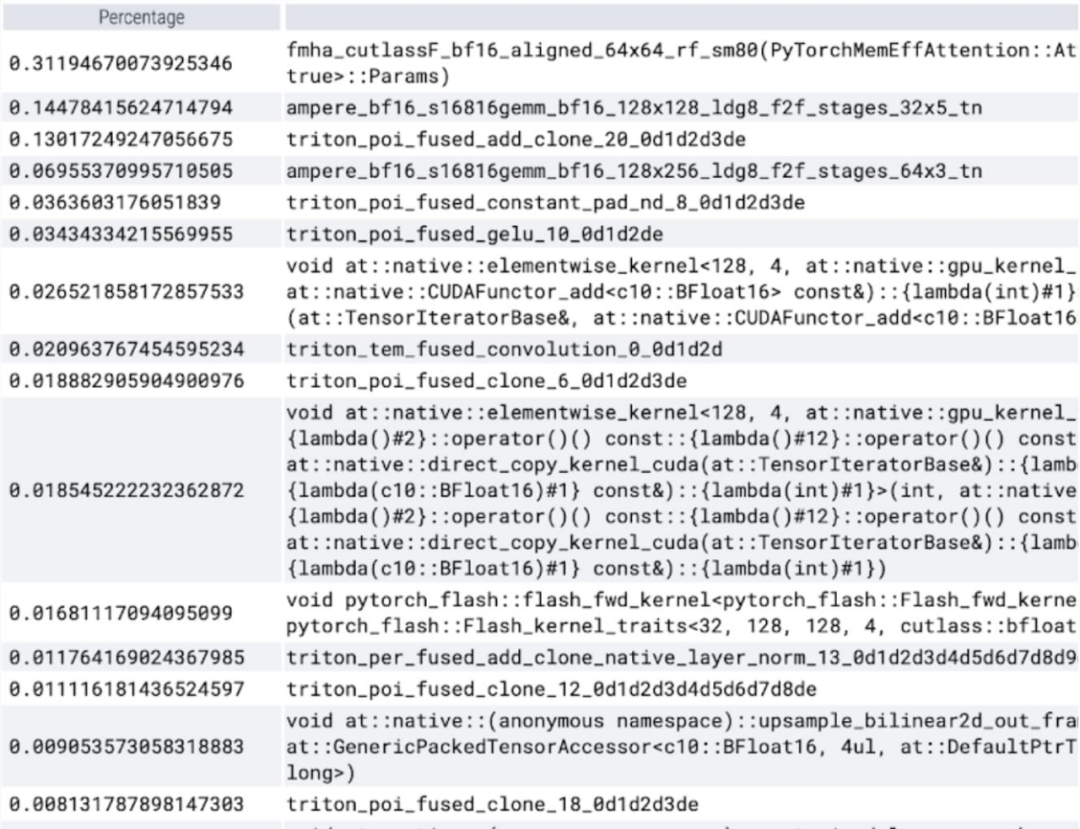
使用 PyTorch 的原生 scaled_dot_product_attention,可以显著增加批处理大小。下图为批大小为 32 及以上的变化。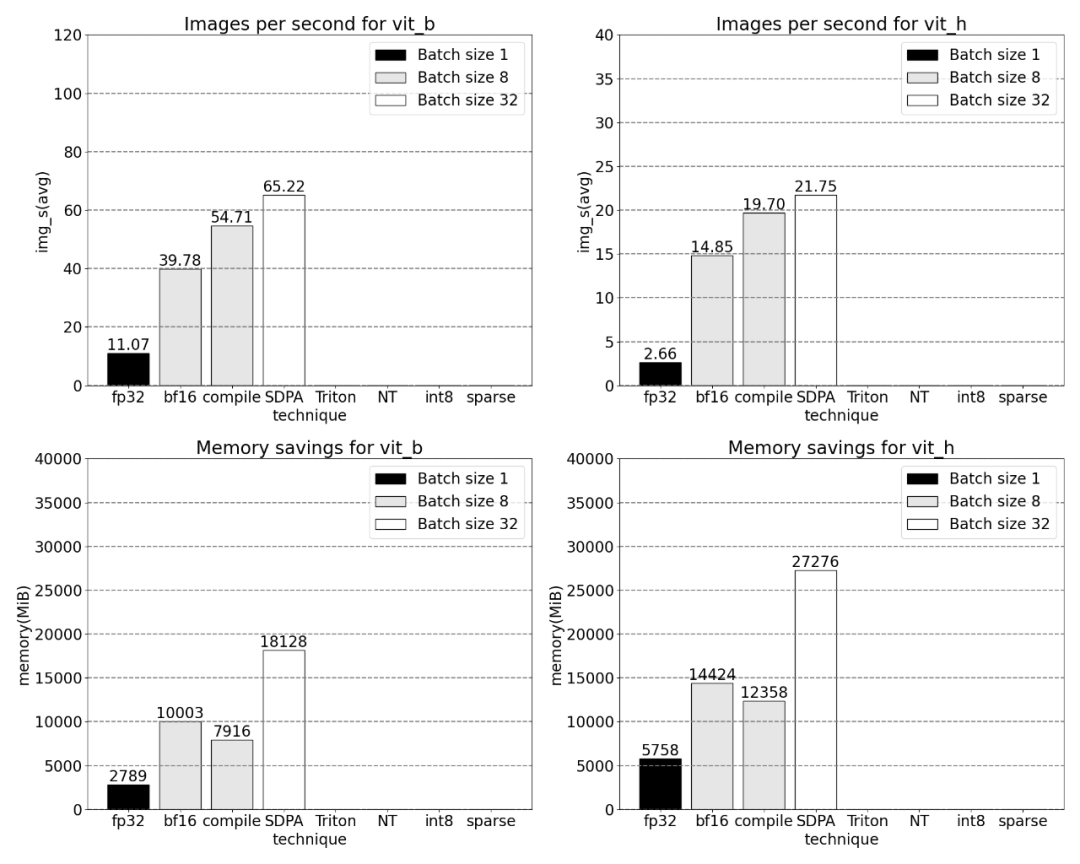
之后,该研究又实验了 Triton,NestedTensor 、批处理 Predict_torch, int8 量化,半结构化 (2:4) 稀疏性等操作。例如本文使用自定义 positional Triton 内核,观察到批大小为 32 的测量结果。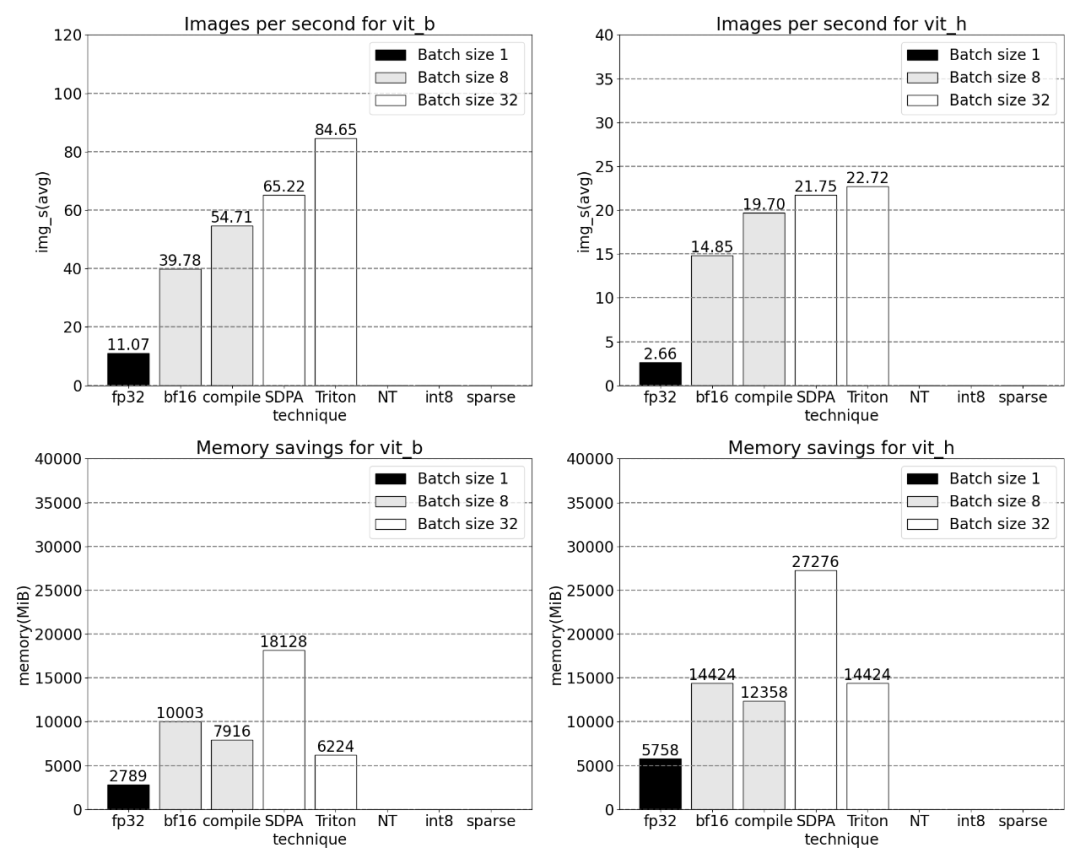
使用 Nested Tensor,批大小为 32 及以上的变化。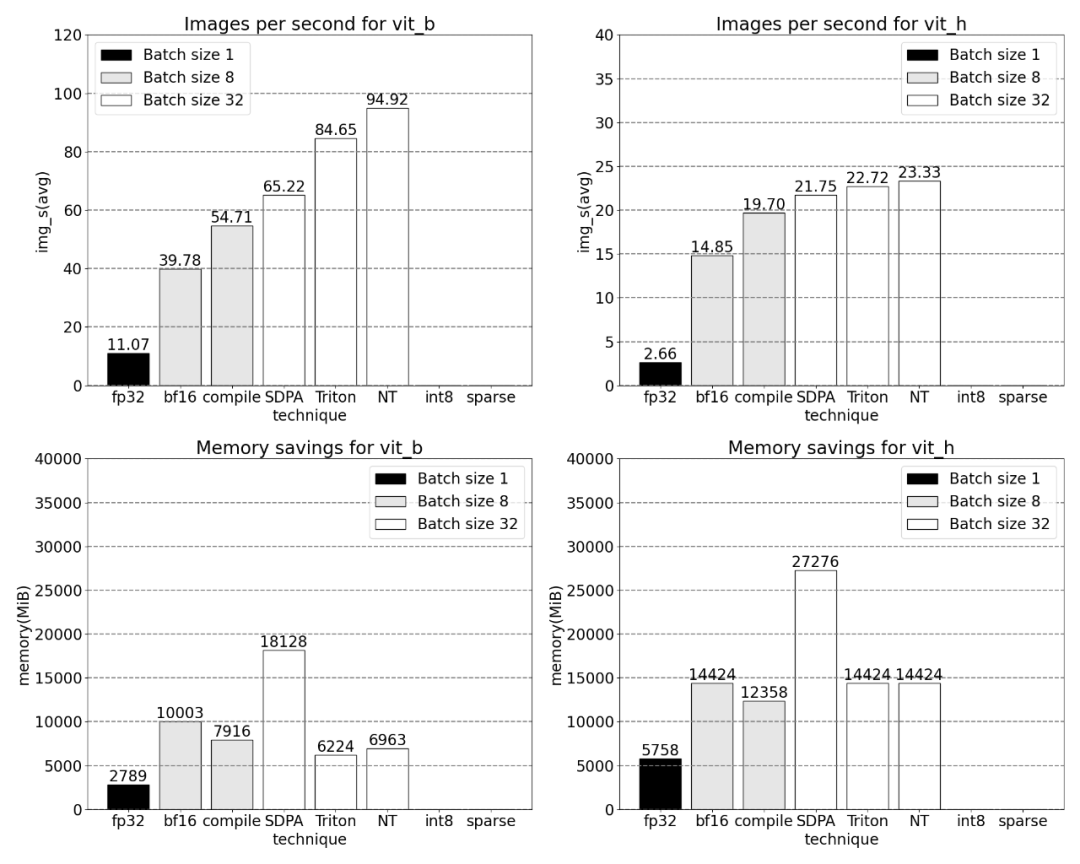
添加量化后,批大小为 32 及以上变化的测量结果。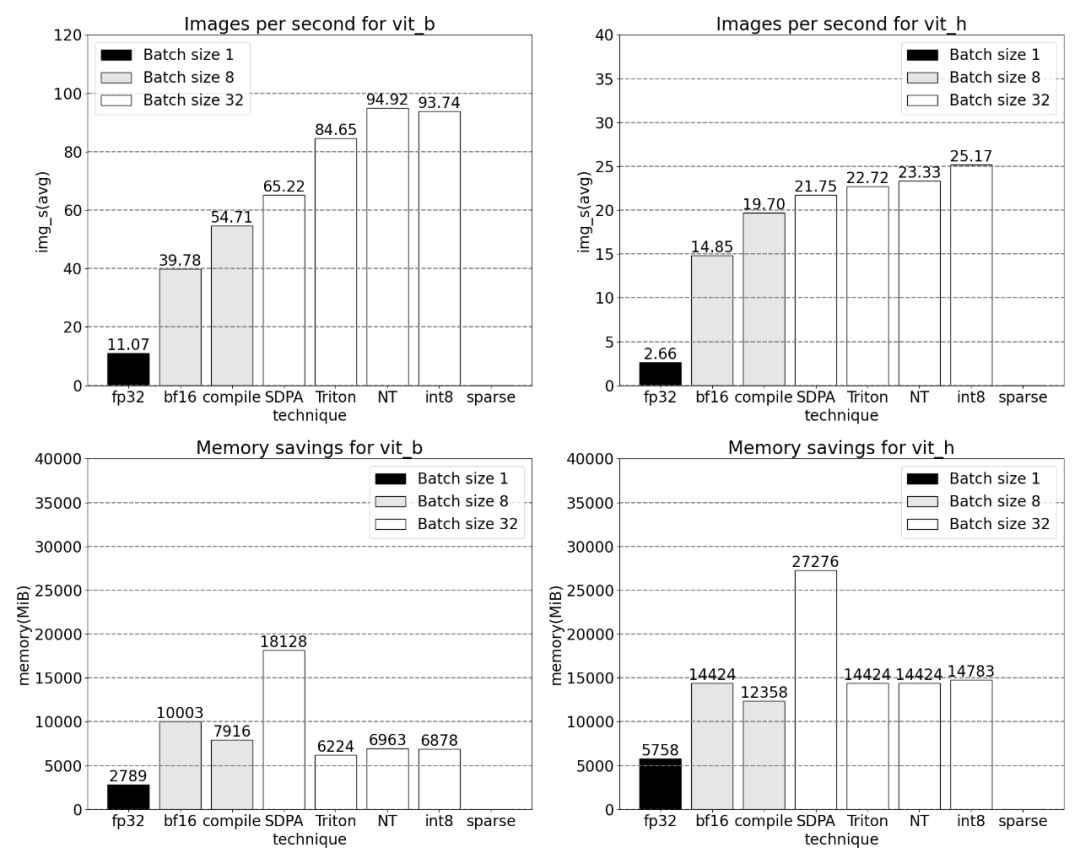
文章的最后是半结构化稀疏性。该研究表示,矩阵乘法仍然是需要面对的一个瓶颈。解决的办法是使用稀疏化来近似矩阵乘法。通过稀疏矩阵(即将值归零)可以使用更少的位来存储权重和激活张量。该研究将张量中哪些权重设置为零的过程称为剪枝。剪枝掉较小的权重可以潜在地减小模型大小,而不会显着损失准确率。剪枝的方法多种多样,从完全非结构化到高度结构化。虽然非结构化剪枝理论上对精度的影响最小,但 GPU 在进行大型密集矩阵乘法方面尽管非常高效,然而在稀疏情况下可能还会遭受显着的性能下降。PyTorch 最近支持的一种剪枝方法旨在寻求平衡,称为半结构化(或 2:4)稀疏性。这种稀疏存储将原始张量减少了 50%,同时产生密集张量输出。参见下图的说明。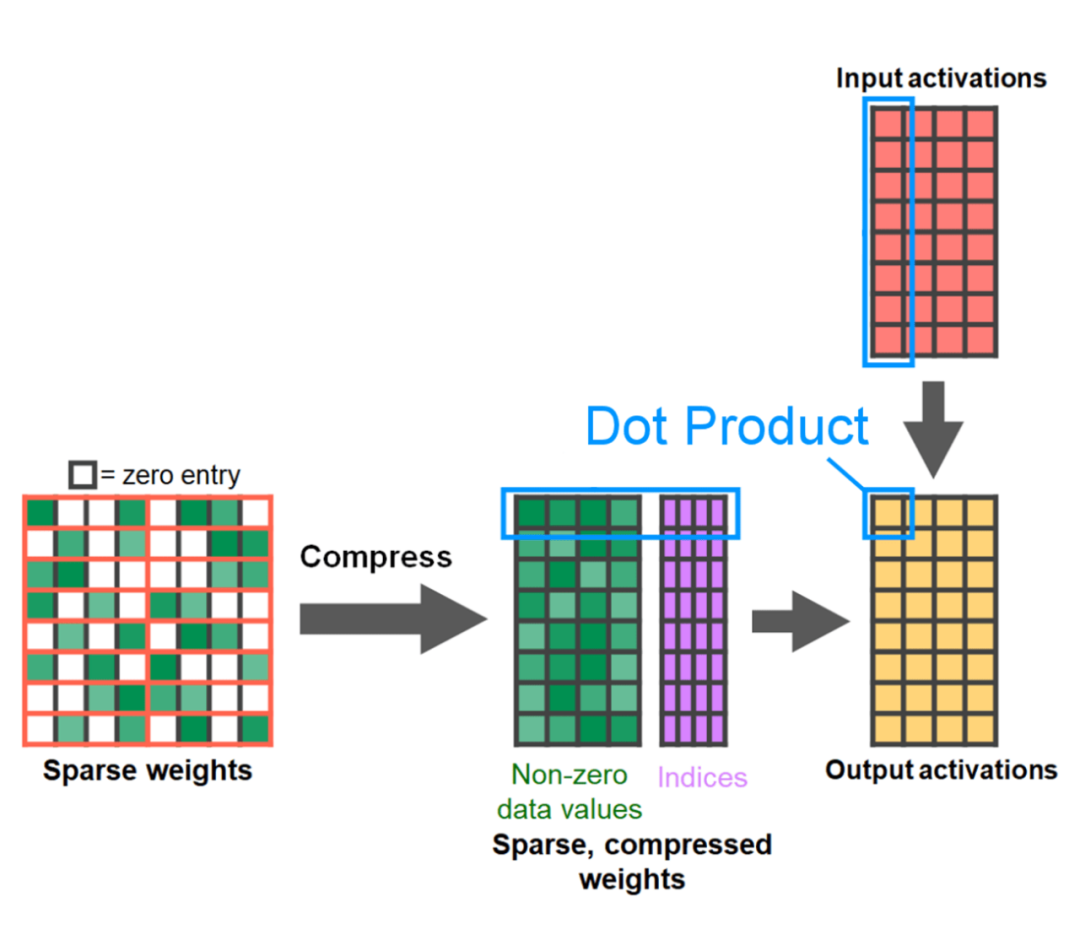
为了使用这种稀疏存储格式和相关的快速内核,接下来要做的是剪枝权重。本文在 2:4 的稀疏度下选择最小的两个权重进行剪枝,将权重从默认的 PyTorch(“strided”)布局更改为这种新的半结构化稀疏布局很容易。要实现 apply_sparse (model),只需要 32 行 Python 代码: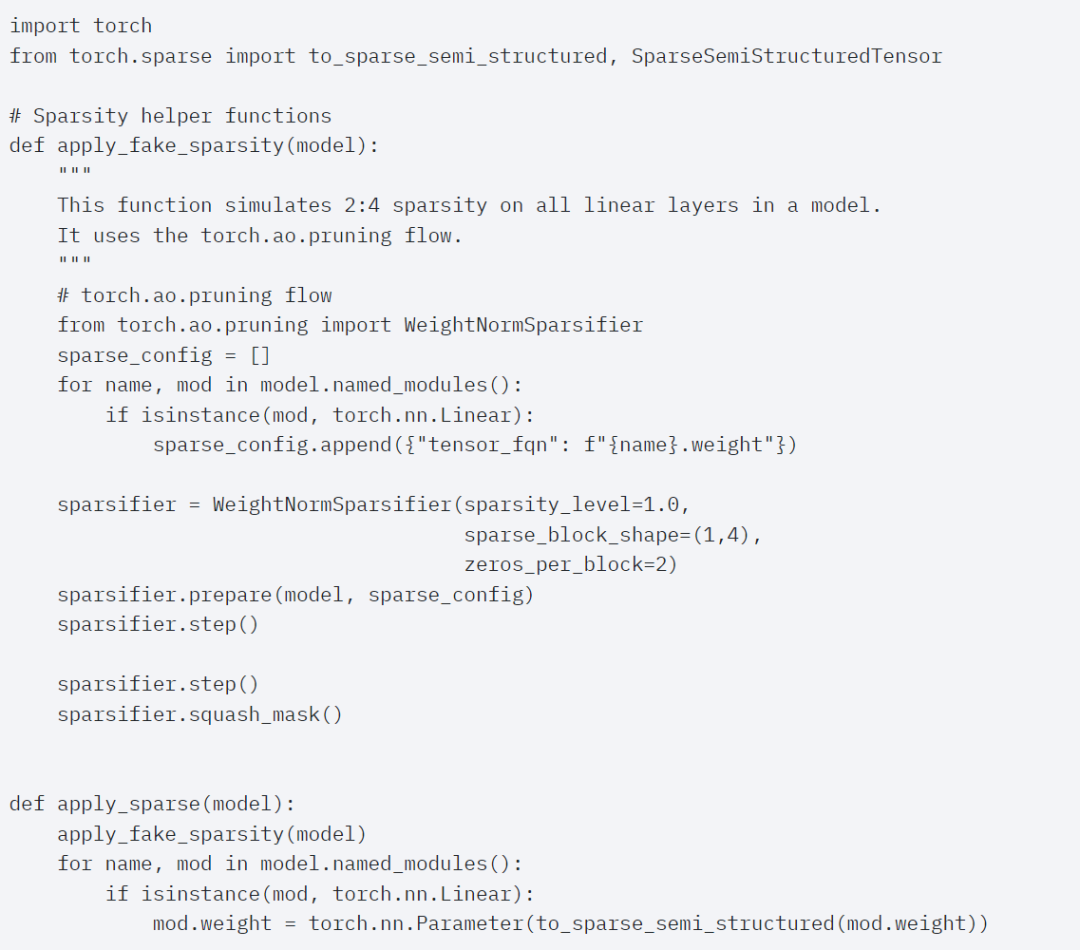
在 2:4 的稀疏度下,本文观察到 vit_b 和批大小为 32 时的 SAM 峰值性能:
最后,一句话总结这篇文章:本文介绍了迄今为止在 PyTorch 上最快的 Segment Anything 实现方式,借助官方发布的一系列新功能,本文在纯 PyTorch 中重写了原始 SAM,并且没有损失准确率。参考链接:https://pytorch.org/blog/accelerating-generative-ai/




































