






本文分析了Softmax与线性注意力的性能差距,指出核心在于单射性质和局部建模能力。线性注意力因非单射导致语义混淆,且局部建模不足;Softmax注意力则具备单射性和强局部建模能力。据此提出InLine注意力,通过改进归一化赋予单射性,实验证明其在保持线性复杂度的同时,性能可优于Softmax注意力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

弥合鸿沟:重新考虑Softmax和线性注意力
摘要
Softmax注意力被广泛应用于现代视觉Transformer设计中,可以有效地捕获远程视觉信息;然而,在处理高分辨率输入时,它会产生过高的计算成本。相比之下,线性注意力自然具有线性复杂性,并且具有扩展到更高分辨率图像的巨大潜力。然而,线性注意力的不理想性能极大地限制了它在各种场景中的实际应用。在本文中,我们向前迈进了一步,用新颖的理论分析来缩小线性和Softmax注意力之间的差距,揭示了性能偏差背后的核心因素。具体来说,我们提出了两个关键的观点来理解和减轻线性注意力的局限性:单射性质和局部建模能力。首先,我们证明了线性注意力不是单射的,这很容易给不同的查询向量分配相同的注意力权重,从而增加了严重的语义混淆,因为不同的查询对应相同的输出。其次,我们证实了有效的局部建模对于Softmax注意力的成功至关重要,而线性注意力的不足。上述两个基本差异显著地促成了这两种注意范式之间的差异,这在本文中得到了大量的实证验证。此外,更多的实验结果表明,只要赋予线性注意力这两个属性,在保持较低的计算复杂度的同时,可以在各种任务中优于Softmax注意力。
1. InLine Attn
由于线性计算复杂度较低,线性注意力被视为解决高分辨率场景中softmax注意力计算挑战的有前途的解决方案。然而,先前的研究表明,线性注意力的表示能力远低于softmax注意力,使其在实际应用中不可行。在本节中,作者从两个视角深入分析了线性注意力与softmax注意力之间的差距:单射和局部建模能力
1.1 单射
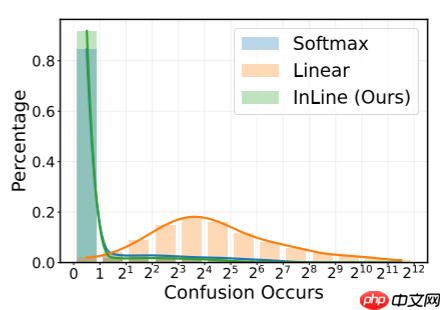
在本文中,作者发现注意力函数的单射性质对模型性能有显著影响,这可能很大程度上解释了线性注意力和 Softmax 注意力之间的差距。具体来说,在温和的假设下,作者证明 Softmax 注意力函数 SK 是单射的,而线性注意力函数 LK不是。因此,对于两个不同的 Query p 和 q (p=q) ,Softmax 注意力应该产生不同的注意力分布 SK(p)=SK(q) ,而线性注意力可能会产生相同值 LK(p)=LK(q) 。由于典型的不同 Query p=q 代表不同的语义,线性注意力的非单射性质实际上会导致语义混淆,即 LK(p)=LK(q) 且 OpL=LK(p)⊤V=LK(q)⊤V=OqL ,使模型无法区分某些语义。
如下图所示,如图(a)所示,有四个共线且长度不同的向量。借助单射性质,Softmax注意力确保每个 Query 获得不同的注意力分数,从而生成更聚焦的注意力分布,特别是对于较长的 Query 。然而,当使用核函数 ϕ(⋅)=ReLU(⋅),时,线性注意力无法区分强度不同但语义相同的 Query ,即具有不同长度的不同强度的共线 Query ,导致这四个 Query 得到完全相同的关注度分数。因此,线性注意力无法为更强的语义生成更聚焦的关注度得分。当使用具有更强非线性的核函数 ϕ(⋅)=ReLU(A⋅+b) 时,线性注意力会遇到更为显著的混淆问题。例如,在图(b)中,使用核函数 ϕ(⋅)=ReLU(A⋅+b) 时,线性注意力会给方向和长度不同的四个 Query 分配完全相同的关注度分数。这种严重的语义混淆可以直接损害模型的性能。
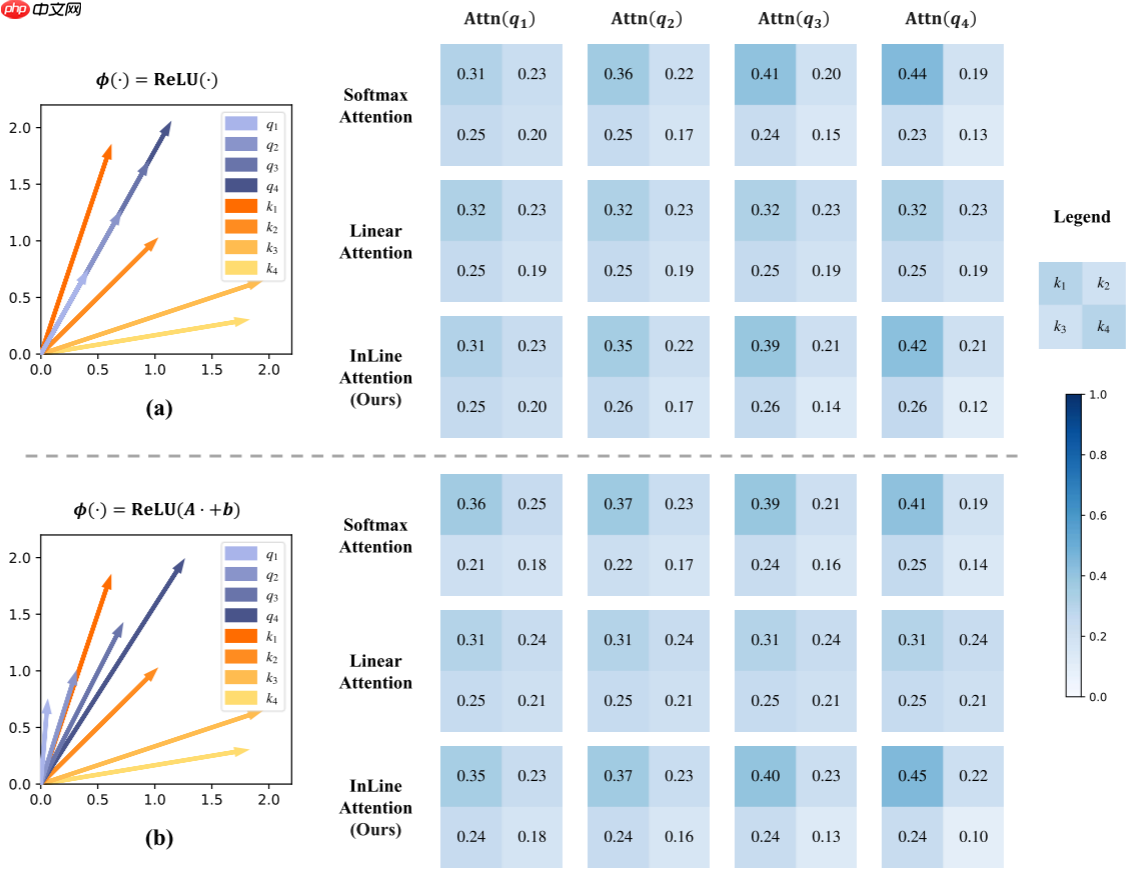

为此,本文提出了一种简单且有效的解决方案,使得线性注意力成为单射函数。在线性注意力中由于忽略了除法中的 α ,对于 ∀α=0 ,αϕ(p) 会获得相同的分数,从而导致非一一对应性。因此,作者简单地将线性注意力的归一化从除法改为减法,提出了单射线性注意力InLine,如下所示:
InLK(Qi)=[ϕ(Qi)⊤ϕ(K1),⋯,ϕ(Qi)⊤ϕ(KN)]⊤−N1s=1∑Nϕ(Qi)⊤ϕ(Ks)+N1
1.2 局部建模能力
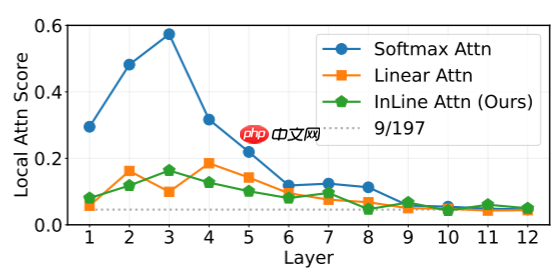
注意力机制以其大的感受野和出色的长程建模能力而著称。然而,本文发现有效的局部建模对于注意力的有效性至关重要。如下图所示,使用DeiT-T计算每个Query分配给局部3×3邻域的注意力值之和。每个DeiT-T注意力层包含总共14×14+1=197个Token,如果注意力分数随机分配,则每个 Query 的3×3邻域的期望注意力值为9/197。结果显示,所有三种注意力机制都倾向于更多关注每个Query的邻域,揭示了局部偏见,尤其是在浅层。值得注意的是,Softmax注意力分配了大量的注意力给局部窗口,表明其局部建模能力比两种其他注意力机制更强。图4提供了相应的可视化结果以进一步确认这一发现。作者认为,Softmax注意力表现更优的原因可能是它具有稳健的局部先验和强大的局部建模能力。为了验证这一假设,作者采用注意力 Mask 去除不同位置的Token,并评估它们对模型性能的影响。结果如下表所示。两个关键观察结果是:
- 去除局部Token显著降低了模型性能,而随机去除相同数量的Token则影响较小
- 当去除局部Token时,Softmax注意力的表现比InLine注意力受损更严重。这些发现证明了局部建模对于两种注意力类型的重要性,并证实了Softmax注意力相对于InLine注意力的优势主要来源于其更强的局部建模能力


2. 代码复现
2.1 下载并导入所需的库
%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figurefrom models import *
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
2.3.2 Inline-DeiT模型的创建
model = inline_deit_tiny(num_classes=10) paddle.summary(model, (1, 3, 224, 224))

2.4 训练
learning_rate = 0.0003n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# InLine Attnmodel = inline_deit_tiny(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter) print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'model = inline_deit_tiny(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:1137
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axes
work_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = inline_deit_tiny(num_classes=10) model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
[2024-12-11 17:32:01,453] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.8952821..2.5877128]. [2024-12-11 17:32:01,457] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.500567]. [2024-12-11 17:32:01,461] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.0494049..2.5877128]. [2024-12-11 17:32:01,465] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.4842881..2.2739873]. [2024-12-11 17:32:01,469] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9980307..1.8158265]. [2024-12-11 17:32:01,473] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9656862..1.4954194]. [2024-12-11 17:32:01,476] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.1007793..2.64]. [2024-12-11 17:32:01,480] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.7582842..2.605142]. [2024-12-11 17:32:01,484] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.7925336..2.3585434]. [2024-12-11 17:32:01,487] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.7411594..2.5702837]. [2024-12-11 17:32:01,491] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.6897851..1.9079742]. [2024-12-11 17:32:01,496] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9306722..2.5702837]. [2024-12-11 17:32:01,500] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9466565..1.4896734]. [2024-12-11 17:32:01,504] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.605142]. [2024-12-11 17:32:01,507] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.64]. [2024-12-11 17:32:01,511] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.500567]. [2024-12-11 17:32:01,515] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.622571]. [2024-12-11 17:32:01,519] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.5280111..2.326275].
总结
本文探讨了导致线性注意力和Softmax注意力性能差距的核心因素,识别并验证了这两种注意力机制之间存在的两大基本差异:单射性质和局部建模能力。




























