






人类自然语言具有高度的复杂性,相同的对话在不同的情景,不同的情感,不同的人演绎,表达的效果往往也会迥然不同。简单的说,我们可以将情感分析(sentiment classification)任务定义为一个分类问题,即指定一个文本输入,机器通过对文本进行分析、处理、归纳和推理后自动输出结论。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、自然语言情感分析的介绍

- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
二、长短时记忆网络LSTM
2.1 LSTM网络结构
当阅读很长的序列时,网络内部的信息会变得越来越复杂,甚至会超过网络的记忆能力,使得最终的输出信息变得混乱无用。长短时记忆网络(Long Short-Term Memory,LSTM)内部的复杂结构正是为处理这类问题而设计的。
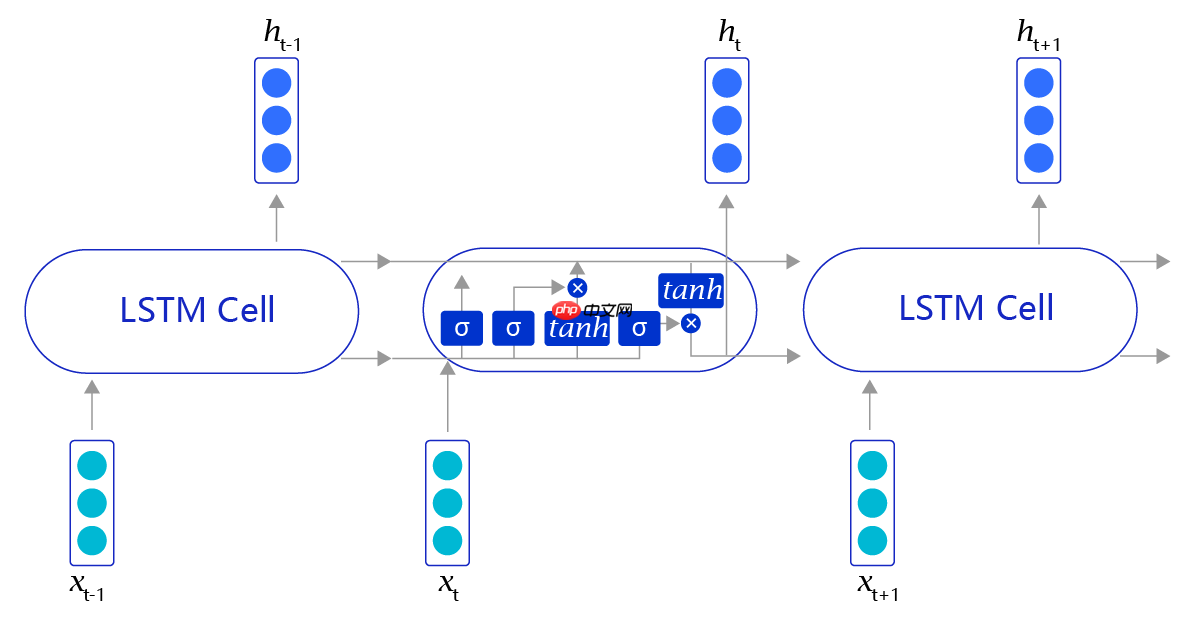
长短时记忆网络通过不断调用同一个cell来逐次处理时序信息,每阅读一个新单词$x_t$,就会输出一个新的输出信号$h_t$,用来表示当前阅读到所有内容的整体向量表示。
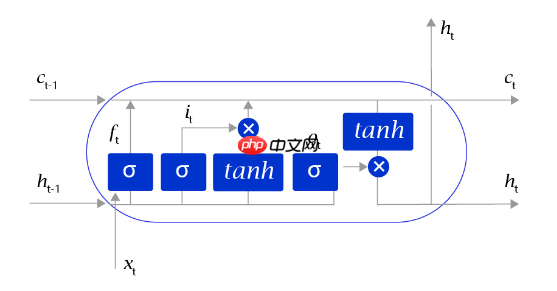
长短时记忆网络最大的特点是在更新内部记忆时,引入了遗忘机制。即容许网络忘记过去阅读过程中看到的一些无关紧要的信息,只保留有用的历史信息。通过这种方式延长了记忆长度。
举个例子:
我觉得这家餐馆的菜品很不错,烤鸭非常正宗,包子也不错,酱牛肉很有嚼劲。但是服务员态度太恶劣了,我们在门口等了50分钟都没有能成功进去,好不容易进去了,桌子也半天没人打扫。整个环境非常吵闹,我的孩子都被吓哭了,我下次不会带朋友来。
当我们阅读上面这段话的时候,可能会记住一些关键词,如烤鸭好吃、牛肉有嚼劲、环境吵等,但也会忽略一些不重要的内容,如“我觉得”、“好不容易”等,长短时记忆网络正是受这个启发而设计的。
长短时记忆网络的Cell有三个输入:
- 这个网络新看到的输入信号,如下一个单词,记为xt, 其中xt是一个向量,t代表了当前时刻。
- 这个网络在上一步的输出信号,记为ht−1,这是一个向量,维度同xt相同。
- 这个网络在上一步的记忆信号,记为ct−1,这是一个向量,维度同xt相同。
得到这两个信号之后,长短时记忆网络没有立即去融合这两个向量,而是计算了权重。
- 输入门:it=σ(WiXt+ViHt−1+bi),控制有多少输入信号会被融合。
- 遗忘门:ft=σ(WfXt+VfHt−1+bf),控制有多少过去的记忆会被遗忘。
- 输出门:ot=σ(WoXt+VoHt−1+bo),控制最终输出多少融合了记忆的信息。
- 单元状态:gt=tanh(WgXt+VgHt−1+bg),输入信号和过去的输入信号做一个信息融合。
其中σ表示的是sigmoid激活函数,tanh表示的是双曲正切激活函数。
通过学习这些门的权重设置,长短时记忆网络可以根据当前的输入信号和记忆信息,有选择性地忽略或者强化当前的记忆或是输入信号,帮助网络更好地学习长句子的语义信息:
记忆信号:ct=ft⋅ct−1+it⋅gt
输出信号:ht=ot⋅tanh(ct)
说明:
事实上,长短时记忆网络之所以能更好地对长文本进行建模,还存在另外一套更加严谨的计算和证明,有兴趣的开发者们可以翻阅一下引文中的参考资料进行详细研究。
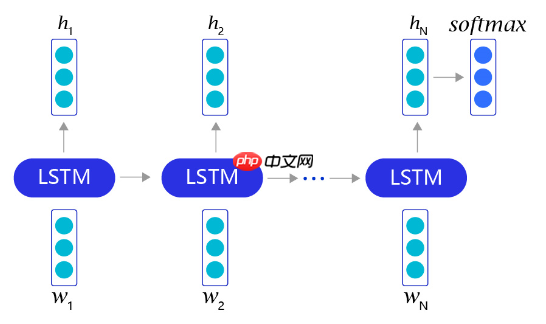
2.2 使用LSTM完成情感分析任务
借助长短时记忆网络,我们可以非常轻松地完成情感分析任务。对于每个句子,我们首先通过截断和填充的方式,把这些句子变成固定长度的向量。然后,利用长短时记忆网络,从左到右开始阅读每个句子。在完成阅读之后,我们使用长短时记忆网络的最后一个输出记忆,作为整个句子的语义信息,并直接把这个向量作为输入,送入一个分类层进行分类,从而完成对情感分析问题的神经网络建模。
三、使用飞桨实现基于LSTM的情感分析模型

import osimport randomimport numpy as npimport pandas as pd# 导入Paddle的APIimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.nn import LSTM, Embedding, Dropout, Linearfrom paddlenlp.datasets import load_datasetfrom paddlenlp.utils.downloader import get_path_from_url
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/cpp_extension/extension_utils.py:686: UserWarning: No ccache found. Please be aware that recompiling all source files may be required. You can download and install ccache from: https://github.com/ccache/ccache/blob/master/doc/INSTALL.md
warnings.warn(warning_message)
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/_distutils_hack/__init__.py:26: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
3.1 数据处理
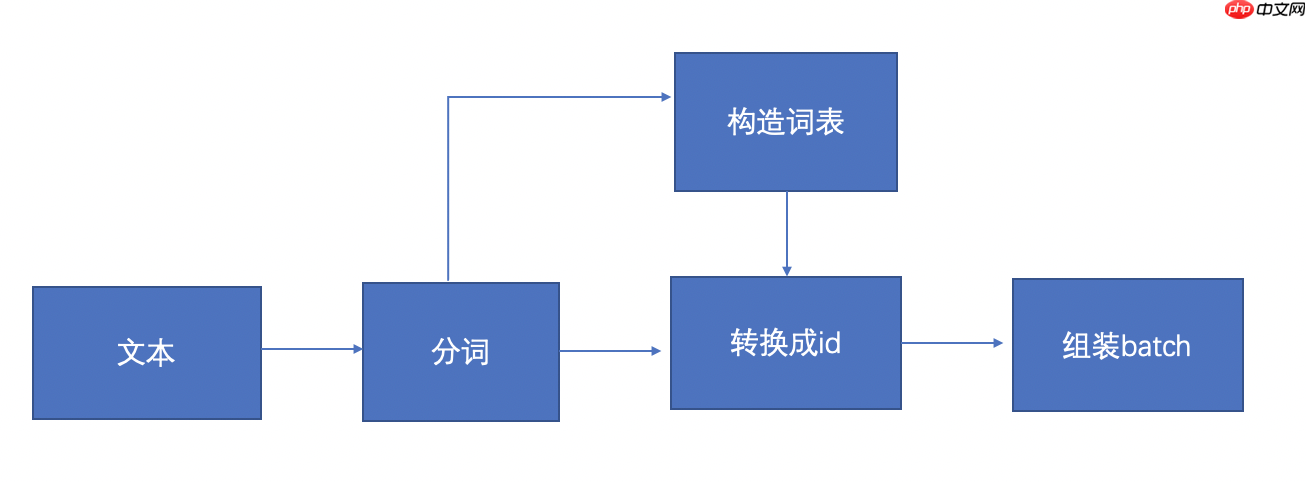
上图显示的是数据处理的流程,首先是输入文本,根据输入的文本数据进行分词,分词完以后构造词表,然后根据词表把分词后的文本映射成id的形式,然后再组装成batch形式的数据。
1.分词:使用结巴分词工具,把句子切分成单词的形式。
2.构造词表:将单词形式的句子,统计频率,按照频率取topK个单词,作为词表,剩下的低频单词舍弃,并给每个单词编一个号。
3.转换成id:主要是利用构造的词汇表,对分好词的数据映射成相应的id的形式。
4.组装batch:组装成一个batch数据(多条数据堆叠在一起),但是每个句子有长有短,对于较短的句子,我们需要补0对齐。
3.1.1 加载数据集
首先,需要下载语料用于模型训练和评估效果。我们使用的是ChnSentiCorp的酒店评论数据,这个数据集是一个开源的中文数据集,由训练数据,验证集和测试数据组成。训练集的数量是9601条,验证集的数量是1201条,测试集的数量是1201条。每个数据表示的是用户对酒店的真实评价,以及用户对酒店的情感倾向(是正向还是负向),数据集下载的代码如下:
!unzip /home/aistudio/data/data310810/ChnSentiCorp.zip -d /home/aistudio
Archive: /home/aistudio/data/data310810/ChnSentiCorp.zip creating: /home/aistudio/ChnSentiCorp/ inflating: /home/aistudio/ChnSentiCorp/train.tsv creating: /home/aistudio/__MACOSX/ creating: /home/aistudio/__MACOSX/ChnSentiCorp/ inflating: /home/aistudio/__MACOSX/ChnSentiCorp/._train.tsv inflating: /home/aistudio/ChnSentiCorp/dev.tsv inflating: /home/aistudio/__MACOSX/ChnSentiCorp/._dev.tsv inflating: /home/aistudio/ChnSentiCorp/License.pdf inflating: /home/aistudio/__MACOSX/ChnSentiCorp/._License.pdf inflating: /home/aistudio/ChnSentiCorp/test.tsv inflating: /home/aistudio/__MACOSX/ChnSentiCorp/._test.tsv inflating: /home/aistudio/__MACOSX/._ChnSentiCorp
def read(split='train'):
data_dict={'train':'ChnSentiCorp/train.tsv', "dev":'ChnSentiCorp/dev.tsv', 'test':'ChnSentiCorp/test.tsv'} with open(data_dict[split],'r') as f:
head = None
# 一行一行的读取数据
for line in f.readlines():
data = line.strip().split("\t") # 跳过第一行,因为第一行是列名
if not head:
head = data else: # 从第二行还是一行一行的返回数据
if split == 'train':
label, text = data yield {"text": text, "label": label, "qid": ''} elif split == 'dev':
qid, label, text = data yield {"text": text, "label": label, "qid": qid} elif split == 'test':
qid, text = data yield {"text": text, "label": '', "qid": qid}
train_ds= load_dataset(read, split="train",lazy=False)
dev_ds= load_dataset(read, split="dev",lazy=False)
test_ds= load_dataset(read, split="test",lazy=False)
len(train_ds)
9600
接下来,将数据集加载到程序中,并打印一小部分数据观察一下数据集的特点,代码如下:
for data in train_ds.data[:5]: print(data)
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': '1', 'qid': ''}
{'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': '1', 'qid': ''}
{'text': '房间太小。其他的都一般。。。。。。。。。', 'label': '0', 'qid': ''}
{'text': '1.接电源没有几分钟,电源适配器热的不行. 2.摄像头用不起来. 3.机盖的钢琴漆,手不能摸,一摸一个印. 4.硬盘分区不好办.', 'label': '0', 'qid': ''}
{'text': '今天才知道这书还有第6卷,真有点郁闷:为什么同一套书有两种版本呢?当当网是不是该跟出版社商量商量,单独出个第6卷,让我们的孩子不会有所遗憾。', 'label': '1', 'qid': ''}
text表示的是评论文本,label表示的是标签,1表示文本的情感倾向是正向的,0表示文本的情感倾向是负向的。qid表示数据的编号,qid出现在测试集中,在训练集合里面数据的编号没有,所以qid为空。




























