






本文尝试基于飞桨框架,用SiameseNetwork和余弦距离构建人脸比对模型。使用face_224数据集,划分训练集和测试集,建立卷积神经网络输出1x128向量编码,通过余弦相似度判断人脸是否同一人。定义对比损失函数,经训练后批量验证准确率75.24%,还提及部署方式及后续改进方向。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

前言
偶然间发现飞桨官方文档里面有一篇关于图像相似度的示例【Paddle官方文档】基于图片相似度的图片搜索,就想着试试看能不能整一个通过相似度来进行人脸比对,然后发现了SiameseNetwork这个东西,打算照着试试自己能不能用余弦距离整一个人脸比对模型出来。
大致思路如下:
- 首先数据集用的是face_224这个数据集,划分好训练集和测试集后生成对应的列表文件
- 然后建立一个卷积神经网络,输入一张图片时,输出的是该图片的编码(一个1x128的向量)
- 通过比较两张图片编码的余弦相似度来判断两张图片是否来自同一个人
简单介绍一下余弦相似度(第一次接触这个,如果有错误欢迎各位大佬指正 ):
):
- 先上个公式:
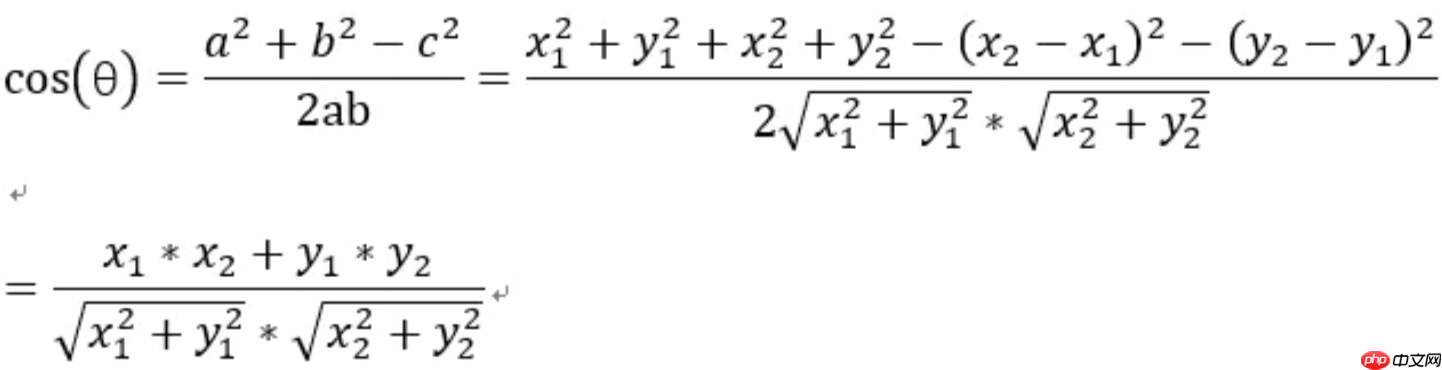
- 再上个代码:
point1 = point1 / paddle.norm(point1, axis=1, keepdim=True)#求范数,说人话就是对应元素的平方和再开方(来自某知乎暴躁老哥)
point2 = point1 / paddle.norm(point2, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(img_emb1, img_emb2),axis=-1)

- 大概讲一下原理:
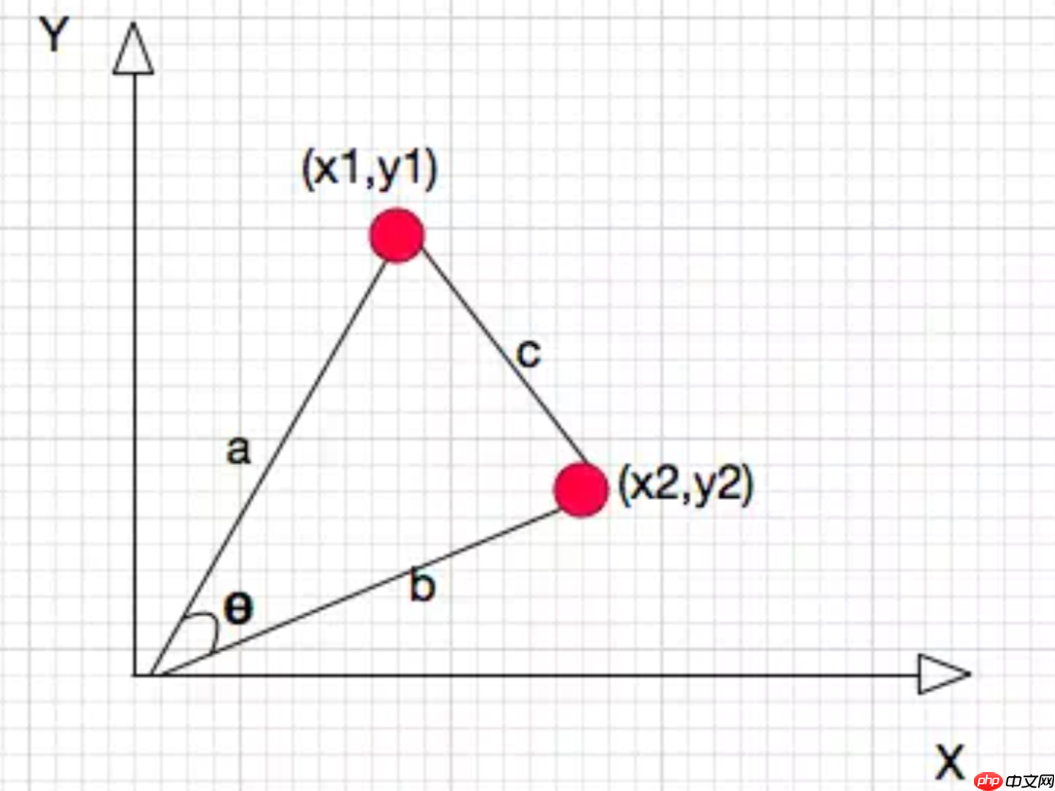
实际上就是把两个点point1(X1,Y1)和point2(X2,Y2)到原点的连线之间的夹角的余弦值算出来,用来衡量point1(X1,Y1)和point2(X2,Y2)之间的距离(也就是相似度),其范围是[-1,1],也就是夹角越小,两个点越近,两个点的余弦相似度也就越接近1,反之就是-1
关于上面的代码,实际上就是把那个公式实现一下,然后那俩point实际上就是换成了多维矩阵,只要动笔写一下就能理解(实际上是我懒得码字了 )
)
还有就是为了配合对比损失函数ContrastiveLoss,需要用1减去余弦相似度获取余弦距离来进行损失函数的计算
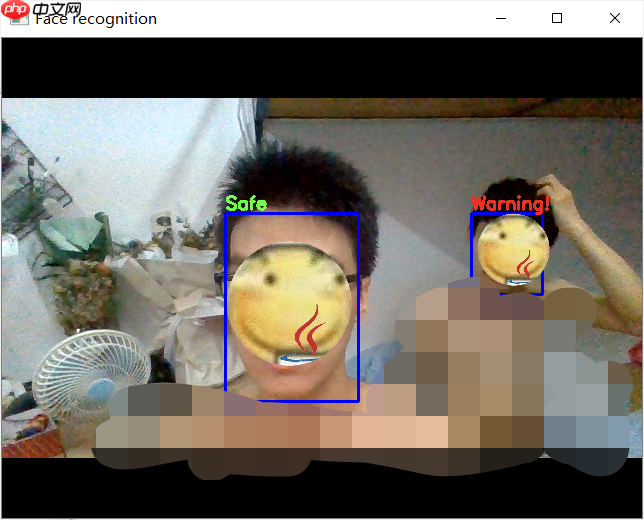
下面是部署效果(临时抓的室友,不要在意细节,天太热了。。。。。。)
一、准备工作
1. 导入所需的库
#导入所需库import osimport cv2import mathimport randomimport paddleimport numpy as npimport paddle.nn as nnimport paddlehub as hubimport paddle.nn.functional as Fimport matplotlib.pyplot as pltfrom PIL import Imagefrom tqdm import tqdmfrom paddle import ParamAttrfrom paddle.static import InputSpecfrom paddle.regularizer import L2Decayfrom paddle.nn.initializer import Uniform, KaimingNormalfrom paddle.nn import Conv2D, Linear, Dropout, BatchNorm, MaxPool2D, AvgPool2D, AdaptiveAvgPool2D
2. 准备数据集
#解压数据集!unzip -q data/data27604/face_224.zip -d data/ !mv data/face_224/train.txt work/textpack/train.txt !mv data/face_224/test.txt work/textpack/test.txt
#数据列表读取#训练集train_list = []with open("work/textpack/train.txt", "r") as f: for line in f.readlines():
data = line.split('\n\t') for datastr in data:
sub_str = datastr.split(' ') if sub_str:
train_list.append(sub_str)
random.shuffle(train_list)#测试集test_list = []with open("work/textpack/test.txt", "r") as f: for line in f.readlines():
data = line.split('\n\t') for datastr in data:
sub_str = datastr.split(' ') if sub_str:
test_list.append(sub_str)
random.shuffle(test_list)
#数据生成器#训练集def reader_creator_train():
data_root = 'data/face_224/'
imgnums = np.arange(2) def reader(BATCHSIZE):
iter_step = 0
img1s = np.empty((BATCHSIZE, 3, 224, 224), dtype=np.float32)
img2s = np.empty((BATCHSIZE, 3, 224, 224), dtype=np.float32)
labels = np.empty(BATCHSIZE, dtype=np.float32) while True:
if iter_step % 2 == 0: #相似
while True: for i, imgnum in enumerate(random.sample(range(len(train_list)),2)):
imgnums[i] = imgnum if train_list[imgnums[0]][1] == train_list[imgnums[1]][1]: break
label = 1.
else: #不相似
while True: for i, imgnum in enumerate(random.sample(range(len(train_list)),2)):
imgnums[i] = imgnum if train_list[imgnums[0]][1] != train_list[imgnums[1]][1]: break
label = 0.
#读取图片
img1 = Image.open(data_root+train_list[imgnums[0]][0])
img2 = Image.open(data_root+train_list[imgnums[1]][0])
img1 = np.array(img1)
img2 = np.array(img2) #维度变换
img1 = np.swapaxes(img1, 1, 2)
img1 = np.swapaxes(img1, 1, 0)
img2 = np.swapaxes(img2, 1, 2)
img2 = np.swapaxes(img2, 1, 0) #归一化
img1 = img1/255.
img2 = img2/255.
#图片整合
img1s[iter_step] = img1
img2s[iter_step] = img2
labels[iter_step] = label #弹出判断
iter_step += 1
if iter_step >= BATCHSIZE: break
yield img1s, img2s, labels return reader
train_reader = reader_creator_train()#测试集def reader_creator_test(BATCHSIZE):
data_root = 'data/face_224/'
imgnums = np.arange(2)
img1s = np.empty((BATCHSIZE, 3, 224, 224), dtype=np.float32)
img2s = np.empty((BATCHSIZE, 3, 224, 224), dtype=np.float32)
labels = np.empty(BATCHSIZE, dtype=np.float32) for iter_step in tqdm(range(BATCHSIZE)):
if iter_step % 2 == 0: #相似
while True: for i, imgnum in enumerate(random.sample(range(len(test_list)),2)):
imgnums[i] = imgnum if test_list[imgnums[0]][1] == test_list[imgnums[1]][1]: break
label = 1.
else: #不相似
while True: for i, imgnum in enumerate(random.sample(range(len(test_list)),2)):
imgnums[i] = imgnum if test_list[imgnums[0]][1] != test_list[imgnums[1]][1]: break
label = 0.
#读取图片
img1 = Image.open(data_root+test_list[imgnums[0]][0])
img2 = Image.open(data_root+test_list[imgnums[1]][0])
img1 = np.array(img1)
img2 = np.array(img2) #维度变换
img1 = np.swapaxes(img1, 1, 2)
img1 = np.swapaxes(img1, 1, 0)
img2 = np.swapaxes(img2, 1, 2)
img2 = np.swapaxes(img2, 1, 0) #归一化
img1 = img1/255.
img2 = img2/255.
#图片整合
img1s[iter_step] = img1
img2s[iter_step] = img2
labels[iter_step] = label return img1s, img2s, labels
3. 模型组网
#自定义网络class MyNet(paddle.nn.Layer):
def __init__(self):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3,3), stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=128, kernel_size=(3,3), stride=2)
self.conv4 = paddle.nn.Conv2D(in_channels=128, out_channels=256, kernel_size=(3,3), stride=2)
self.gloabl_pool = paddle.nn.AdaptiveAvgPool2D((1,1))
self.fc1 = paddle.nn.Linear(in_features=256, out_features=128) @paddle.jit.to_static #这句导出的时候用的
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.gloabl_pool(x)
x = paddle.squeeze(x, axis=[2, 3])
x = self.fc1(x) return x
#余弦距离对比损失函数def ContrastiveLoss(output1, output2, label):
# 余弦距离
output1 = output1 / paddle.norm(output1, axis=1, keepdim=True)
output2 = output2 / paddle.norm(output2, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(output1, output2),axis=-1)
ones = paddle.ones(shape=CosineSimilarities.shape, dtype='float32')
CosineDistance = paddle.subtract(ones, CosineSimilarities)
margin = ones*1.25
# 对比损失ContrastiveLoss
loss = paddle.add(
paddle.multiply(label, paddle.pow(CosineDistance, 2)),
paddle.multiply(paddle.subtract(ones, label), paddle.pow(F.relu(paddle.subtract(margin, CosineDistance)), 2))
)
avg_loss = paddle.mean(loss) return avg_loss
二、训练网络
1. 从零开始
#MyNet开始训练def train(model):
print('start training ... ')
model.train()
EPOCH_NUM = 100000
BATCHSIZE = 512
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()) for epoch in range(EPOCH_NUM): #训练模型
for data in train_reader(BATCHSIZE):
img1_data, img2_data, label = data
img1_tensor = paddle.to_tensor(img1_data)
img2_tensor = paddle.to_tensor(img2_data)
label_tensor = paddle.to_tensor(label)
img1_embedding = model(img1_tensor)
img2_embedding = model(img2_tensor)
loss = ContrastiveLoss(img1_embedding, img2_embedding, label_tensor)
print("epoch: {}, loss is: {}".format(epoch, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
#保存模型
if epoch % 10 == 0:
paddle.jit.save(layer=model,
path='work/modelsaveMyNet/' + str(epoch) + '/' + 'model',
input_spec=[InputSpec(shape=[None, 40000], dtype='float32')])
#不严谨的验证(用来进行调试)
model_val = paddle.jit.load('work/modelsaveMyNet/' + str(epoch) + '/' + 'model')
model_val.eval() #相似
img1_temp = model_val(paddle.unsqueeze(img1_tensor[0], axis=0))
img2_temp = model_val(paddle.unsqueeze(img2_tensor[0], axis=0))
img1_temp = img1_temp / paddle.norm(img1_temp, axis=1, keepdim=True)
img2_temp = img2_temp / paddle.norm(img2_temp, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(img1_temp, img2_temp),axis=-1)
ones = paddle.ones(shape=CosineSimilarities.shape, dtype='float32')
CosineDistance = paddle.subtract(ones, CosineSimilarities)
print('CosineDistance: {}, Label: {}'.format(CosineDistance.numpy()[0], label[0])) #不相似
img1_temp = model_val(paddle.unsqueeze(img1_tensor[1], axis=0))
img2_temp = model_val(paddle.unsqueeze(img2_tensor[1], axis=0))
img1_temp = img1_temp / paddle.norm(img1_temp, axis=1, keepdim=True)
img2_temp = img2_temp / paddle.norm(img2_temp, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(img1_temp, img2_temp),axis=-1)
ones = paddle.ones(shape=CosineSimilarities.shape, dtype='float32')
CosineDistance = paddle.subtract(ones, CosineSimilarities)
print('CosineDistance: {}, Label: {}'.format(CosineDistance.numpy()[0], label[1]))
model = MyNet()
train(model)
2. 继续训练
#MyNet继续训练def continue_train(epochnumbercontinue,model):
print('start training ... ')
model.train()
EPOCH_NUM = 100000
BATCHSIZE = 512
opt = paddle.optimizer.Adam(learning_rate=0.00001, parameters=model.parameters()) for epoch in range(epochnumbercontinue,EPOCH_NUM): #训练模型
for data in train_reader(BATCHSIZE):
img1_data, img2_data, label = data
img1_tensor = paddle.to_tensor(img1_data)
img2_tensor = paddle.to_tensor(img2_data)
label_tensor = paddle.to_tensor(label)
img1_embedding = model(img1_tensor)
img2_embedding = model(img2_tensor)
loss = ContrastiveLoss(img1_embedding, img2_embedding, label_tensor)
print("epoch: {}, loss is: {}".format(epoch, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
#保存模型
if epoch % 10 == 0:
paddle.jit.save(layer=model,
path='work/modelsaveMyNet/' + str(epoch) + '/' + 'model',
input_spec=[InputSpec(shape=[None, 40000], dtype='float32')])
#不严谨的验证(用来进行调试)
model_val = paddle.jit.load('work/modelsaveMyNet/' + str(epoch) + '/' + 'model')
model_val.eval() #相似
img1_temp = model_val(paddle.unsqueeze(img1_tensor[0], axis=0))
img2_temp = model_val(paddle.unsqueeze(img2_tensor[0], axis=0))
img1_temp = img1_temp / paddle.norm(img1_temp, axis=1, keepdim=True)
img2_temp = img2_temp / paddle.norm(img2_temp, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(img1_temp, img2_temp),axis=-1)
ones = paddle.ones(shape=CosineSimilarities.shape, dtype='float32')
CosineDistance = paddle.subtract(ones, CosineSimilarities)
print('CosineDistance: {}, Label: {}'.format(CosineDistance.numpy()[0], label[0])) #不相似
img1_temp = model_val(paddle.unsqueeze(img1_tensor[1], axis=0))
img2_temp = model_val(paddle.unsqueeze(img2_tensor[1], axis=0))
img1_temp = img1_temp / paddle.norm(img1_temp, axis=1, keepdim=True)
img2_temp = img2_temp / paddle.norm(img2_temp, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(img1_temp, img2_temp),axis=-1)
ones = paddle.ones(shape=CosineSimilarities.shape, dtype='float32')
CosineDistance = paddle.subtract(ones, CosineSimilarities)
print('CosineDistance: {}, Label: {}'.format(CosineDistance.numpy()[0], label[1]))
model_dir = 'work/modelsaveMyNet'model_list = os.listdir(model_dir)
epochnumbers = [ int(epochnumber) for epochnumber in model_list ]
epochnumbermax = max(epochnumbers)
path = 'work/modelsaveMyNet/' + str(epochnumbermax) + '/' + 'model'model_continue = paddle.jit.load(path)
continue_train(int(epochnumbermax), model_continue)
三、效果检验
1. 加载模型
# 加载模型model_dir = 'work/modelsaveMyNet'model_list = os.listdir(model_dir) epochnumbers = [ int(epochnumber) for epochnumber in model_list ] epochnumbermax = max(epochnumbers) path = 'work/modelsaveMyNet/' + str(epochnumbermax) + '/' + 'model'model_val = paddle.jit.load(path) model_val.eval()
2. 单张验证
#读取图片img1 = Image.open("data/face_224/0/0_0000.jpg")
img2 = Image.open("data/face_224/1/1_0000.jpg")
img1 = np.array(img1)
img2 = np.array(img2)#维度变换img1 = np.swapaxes(img1, 1, 2)
img1 = np.swapaxes(img1, 1, 0)
img2 = np.swapaxes(img2, 1, 2)
img2 = np.swapaxes(img2, 1, 0)#归一化img1 = img1/255.img2 = img2/255.#维度增加img1 = np.expand_dims(img1, axis=0).astype('float32')
img2 = np.expand_dims(img2, axis=0).astype('float32')#To Tensorimg_t1 = paddle.to_tensor(img1)
img_t2 = paddle.to_tensor(img2)#调用模型img_emb1 = model_val(img_t1)
img_emb2 = model_val(img_t2)#计算相似度img_emb1 = img_emb1 / paddle.norm(img_emb1, axis=1, keepdim=True)
img_emb2 = img_emb2 / paddle.norm(img_emb2, axis=1, keepdim=True)
CosineSimilarity = paddle.sum(paddle.multiply(img_emb1, img_emb2),axis=-1)#结果打印print('CosineSimilarity = {}'.format(CosineSimilarity.numpy()[0]))
CosineSimilarity = -0.09816156327724457
3. 批量验证
#生成测试包(生成较慢,可适当减小TESTBATCHSIZE)TESTBATCHSIZE = 2048img1_data, img2_data, label = reader_creator_test(TESTBATCHSIZE)
100%|██████████| 2048/2048 [03:44<00:00, 9.12it/s]
#生成CosineSimilarities结果包img1_tensor = paddle.to_tensor(img1_data)
img2_tensor = paddle.to_tensor(img2_data)
img_emb1 = model_val(img1_tensor)
img_emb2 = model_val(img2_tensor)
img_emb1 = img_emb1 / paddle.norm(img_emb1, axis=1, keepdim=True)
img_emb2 = img_emb2 / paddle.norm(img_emb2, axis=1, keepdim=True)
CosineSimilarities = paddle.sum(paddle.multiply(img_emb1, img_emb2),axis=-1)#遍历计数比较TrueCount = 0TotalCount = 0similarityTHRE = 0.42for i in range(len(CosineSimilarities.numpy())): if(label[i] == 1 and CosineSimilarities.numpy()[i] >= similarityTHRE):
TrueCount += 1
elif(label[i] == 0 and CosineSimilarities.numpy()[i] < similarityTHRE):
TrueCount += 1
TotalCount += 1#显示准确率Acc = TrueCount/TotalCountprint("TrueCount = {}".format(TrueCount))print("TotalCount = {}".format(TotalCount))print("Acc = {}".format(Acc))
TrueCount = 1541 TotalCount = 2048 Acc = 0.75244140625
四、模型部署
- 请参照我之前的项目【PaddleHub】构建一个人脸识别模型并部署到Jetson Nano上(只要把模型文件换掉再把相似度计算部分改成余弦相似度就行了)
- 本项目开篇的展示图是使用PaddleInference部署在Windows10平台上的效果
五、项目总结
- 曾使用过欧式距离,效果没有余弦距离好
- 效果检验的结果并不是非常理想,准确率只有75.24%(但是部署的时候还行)
- 后续考虑更换其他网络进行测试,以及更换三元组损失(Triplet Loss)进行测试
- 实际上,正样本和负样本构建的时候采取的是随机选取的方式,个人感觉可能会有问题
- 如果出现报错invalid literal for int() with base 10: '.ipynb_checkpoints'则运行右方语句!rm -rf work/modelsaveMyNet/.ipynb_checkpoints




























