






本文围绕九种蘑菇的图像分类任务展开,采用卷积神经网络结构。先解压数据集并标注,划分出训练集与验证集,定义数据集类并做数据增强。接着选用mobilenet_v2网络,配置优化器等,经100轮训练,通过回调函数保存最佳模型,最后存储模型以备后续评估测试。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

① 问题定义
九种蘑菇的分类的本质是图像分类任务,采用卷积审计网络网络结构进行相关实践。
In [1]
!unzip -oq /home/aistudio/data/data82495/mushrooms_train.zip -d work/
2.2 数据标注
我们先看一下解压缩后的数据集长成什么样子。
In [1]
import paddle
paddle.seed(8888)import numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 9, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':100, 'batch_size': 128, 'lr': 0.01}
In [3]
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Image
imgs = []
paths = os.listdir('work/mushrooms_train')for path in paths:
img_path = os.path.join('work/mushrooms_train', path) if os.path.isdir(img_path):
img_paths = os.listdir(img_path)
img = Image.open(os.path.join(img_path, random.choice(img_paths)))
imgs.append((img, path))
f, ax = plt.subplots(3, 3, figsize=(12,12))for i, img in enumerate(imgs[:9]):
ax[i//3, i%3].imshow(img[0])
ax[i//3, i%3].axis('off')
ax[i//3, i%3].set_title('label: %s' % img[1])
plt.show()
<Figure size 864x864 with 9 Axes>

In [3]
import osimport shutil
train_dir = config_parameters['train_image_dir']
eval_dir = config_parameters['eval_image_dir']
paths = os.listdir('work/mushrooms_train')if not os.path.exists(train_dir):
os.mkdir(train_dir)if not os.path.exists(eval_dir):
os.mkdir(eval_dir)for path in paths:
imgs_dir = os.listdir(os.path.join('work/mushrooms_train', path))
target_train_dir = os.path.join(train_dir,path)
target_eval_dir = os.path.join(eval_dir,path) if not os.path.exists(target_train_dir):
os.mkdir(target_train_dir) if not os.path.exists(target_eval_dir):
os.mkdir(target_eval_dir) for i in range(len(imgs_dir)): if ' ' in imgs_dir[i]:
new_name = imgs_dir[i].replace(' ', '_') else:
new_name = imgs_dir[i]
target_train_path = os.path.join(target_train_dir, new_name)
target_eval_path = os.path.join(target_eval_dir, new_name)
if i % 5 == 0:
shutil.copyfile(os.path.join(os.path.join('work/mushrooms_train', path), imgs_dir[i]), target_eval_path) else:
shutil.copyfile(os.path.join(os.path.join('work/mushrooms_train', path), imgs_dir[i]), target_train_path)print('finished train val split!')
finished train val split!
2.3.2 导入数据集的定义实现
In [4]
#数据集的定义class TowerDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(TowerDataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
In [5]
from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)),
T.RandomHorizontalFlip(5),
T.RandomRotation(15),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
In [6]
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=128,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=128, #num_workers=2,
#use_shared_memory=True
)
2.3.3 实例化数据集类
根据所使用的数据集需求实例化数据集类,并查看总样本量。
In [7]
print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
训练集样本量: 42,验证集样本量: 11
③ 模型选择和开发
3.1 网络构建
本次我们使用mobilenet_v2网络来完成我们的案例实践。
In [11]
import paddlefrom paddle.vision.models import mobilenet_v2 network=paddle.vision.models.mobilenet_v2(pretrained=True,num_classes=9) model=paddle.Model(network)
2021-04-20 04:52:16,152 - INFO - unique_endpoints {''}
2021-04-20 04:52:16,153 - INFO - File /home/aistudio/.cache/paddle/hapi/weights/mobilenet_v2_x1.0.pdparams md5 checking...
2021-04-20 04:52:16,203 - INFO - Found /home/aistudio/.cache/paddle/hapi/weights/mobilenet_v2_x1.0.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.1.weight. classifier.1.weight receives a shape [1280, 1000], but the expected shape is [1280, 9].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.1.bias. classifier.1.bias receives a shape [1000], but the expected shape is [9].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
④ 模型训练和优化器的选择
In [12]
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/mushroom')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.01)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
In [13]
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=128,
callbacks=callbacks,
verbose=1) # 日志展示格式
⑤模型训练效果展示
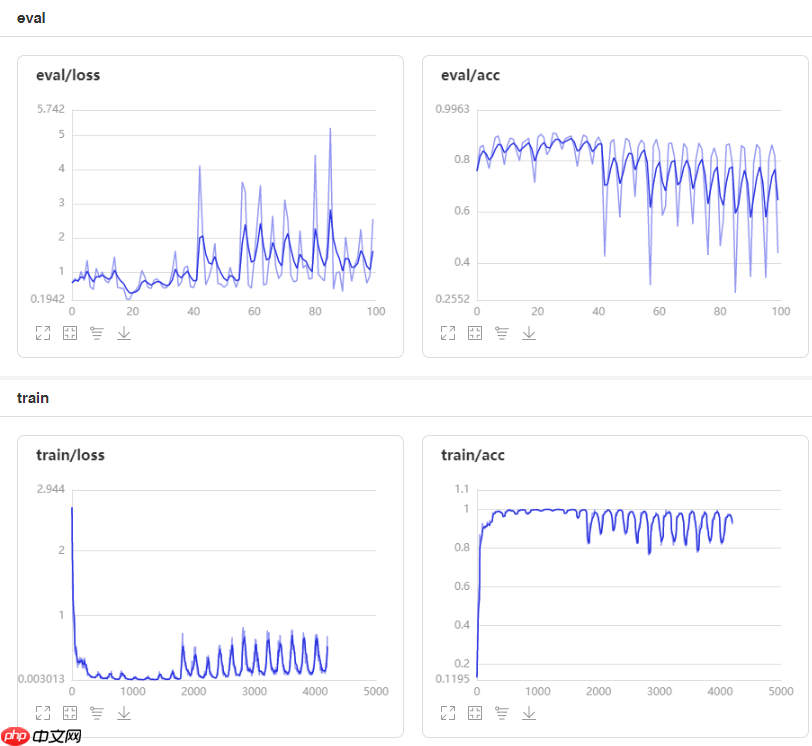
⑥模型存储
将我们训练得到的模型进行保存,以便后续评估和测试使用。
In [14]
model.save(get('model_save_dir'))




























