






本文是百度论文复现赛中《Matching Networks for One Shot Learning》的复现代码说明。基于paddlepaddle-gpu2.2.2和python3.7环境,在miniImageNet数据集上完成。复现的5-way 1-shot和5-shot准确率分别为48.3%、62.2%,超论文原结果。介绍了模型背景、数据集、运行步骤、对比试验及复现心得。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、前言
本项目为百度论文复现赛《Matching Networks for One Shot Learning》论文复现代码。
依赖环境:
- paddlepaddle-gpu2.2.2
- python3.7
在miniImageNet数据集下训练和测试。
5-way Acc:
| 1-shot | 5-shot | |
|---|---|---|
| 论文 | 46.6% | 60.0% |
| 复现 | 48.3% | 62.2% |
二、模型背景及其介绍
参考论文:《Matching Networks for One Shot Learning》论文链接
在这项工作中,论文采用了基于深度神经特征的度量学习和利用外部记忆增强神经网络的最新进展。论文中框架学习了一个网络,它将一个小的带标签的support set和一个未带标签的示例映射到本身的标签上,从而避免了调整以适应new class类型的需要。然后我们定义了视觉(使用Omniglot, ImageNet)和语言任务的one-shot学习问题。与其他方法相比,论文算法在ImageNet上的one-shot精度从87.6%提高到93.2%,在Omniglot上从88.0%提高到93.8%。
模型结构如下:
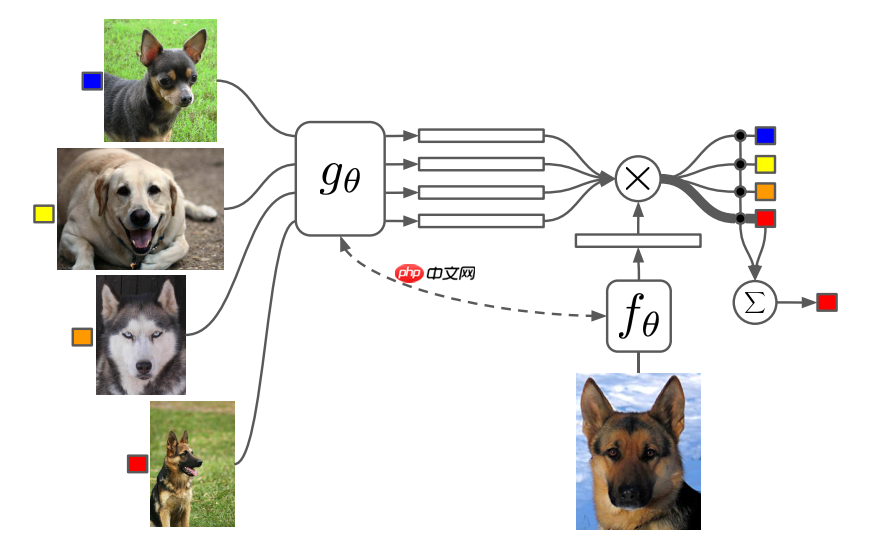
论文主要解决:基于小样本去学习归类(或别的任务),并且这个训练好的模型不需要经过调整,也可以用在对训练过程中未出现过的类别进行归类。
MatchingNet的训练对象如下公式:
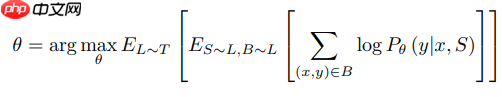
其中,一个 batch 有多个任务,一个任务有一个支持集合一个测试样本,一个支持集有多个样本对。模型应用到新的类别时不需要进行微调,是因为模型学到的是一种映射的方法,
参考论文博客
参考项目地址 复现github地址

四、运行
本项目5-way分类可设1-shot和5-shot。如果用5-shot可设置--n_shot 5,用1-shot可设置--n_shot 1。下面以5-shot为例。
解压miniImagenet数据集到./filelists目录下用于训练
#加载miniImagenet数据集%cd /home/aistudio/work/Paddle-MatchingNet/filelists/ !unzip -oq /home/aistudio/data/data138415/miniImagenet.zip
/home/aistudio/work/Paddle-MatchingNet/filelists
1、训练
训练的模型保存在./record目录下
训练的日志保存在./logs目录下
%cd /home/aistudio/work/Paddle-MatchingNet/ !python3 train.py --n_shot 5
2、保存特征
将提取的特征保存在分类层之前,以提高测试速度。
加载./record目录下的模型进行特征保存
# 可加载预先训练好的模型文件到./record目录下%cd /home/aistudio/work/Paddle-MatchingNet/record/ !unzip -oq /home/aistudio/data/data140016/checkpoint_matchingnet.zip
%cd /home/aistudio/work/Paddle-MatchingNet/ !python3 save_features.py --n_shot 5
3、测试
测试之前执行!python3 save_features.py预先提取特征
这里展示5-shot测试结果
%cd /home/aistudio/work/Paddle-MatchingNet/ !python3 test.py --n_shot 5
/home/aistudio/work/Paddle-MatchingNet W0418 20:57:16.315918 1841 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0418 20:57:16.321213 1841 device_context.cc:465] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/framework/io.py:415: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterable) and not isinstance(obj, ( 600 Test Acc = 62.83% +- 0.73%
五、代码结构
├─data # 数据处理包├─filelists # 数据文件├─methods # 模型方法├─logs # 训练日志├─record # 训练保存文件 │ configs.py # 配置文件│ README.md # readme│ save_features.py # 保存特征│ train.py # 训练│ test.py # 测试
六、对比试验
原论文中没有对miniImageNet做数据增强,本次复现也默认未做数据增强。本项目对是否采用数据增强做了对比实验。 结果如下:
| task | 未扩增 | 扩增 |
|---|---|---|
| 1-shot | 48.3% | 45.3% |
| 5-shot | 62.2% | 60.1% |
发现做数据增强的MatchingNet出现了精度下降的情况,可参考论文复现ProtoNet的分析,项目中有设置train_aug是否做数据增强,可自行测试。
七、复现心得
本项目参照小样本方向论文baseline给出的repo代码复现。复现过程中遇到一个比较大的问题是dataloader的设计编写,原repo设计dataloader采用了iter迭代方式,每次next的是一个sub_dataloader()。我用相同的方式使用paddle复现后,发现内存无限的增长。这个问题一直困扰,最后放弃了原repo使用sub_dataloader()的方式,采用普通的dataloader()的方法。下面给出部分实现SetDataset()的方案代码:
def __getitem__(self, i):
index = self.cl_list[i.item()]
sub_data = np.array(self.sub_meta[index])
ri = np.random.permutation(len(sub_data))
sf_sub_data = sub_data[ri][:self.batch_size]
imgs = []
targets = []
for ssd in sf_sub_data:
image_path = os.path.join(ssd)
img = Image.open(image_path).convert('RGB')
img = self.transform(img)
target = paddle.to_tensor(self.target_transform(index))
imgs.append(img)
targets.append(target)
imgs = paddle.stack(imgs, axis=0)
targets = paddle.stack(targets, axis=0)
return imgs, targets




























