






本文介绍基于paddleclas的多场景杂草分类研究。使用昆士兰州牧场8种杂草的17508张原位图像,经处理生成训练集(15000张)和验证集(2509张)。选用含49个卷积层和1个全连接层的resnet50模型,通过paddleclas训练,可边训边评并保存最优模型,还能单独评估及用存盘模型预测。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于PaddleClas的多场景杂草分类
一、数据集介绍
- 选定的杂草种类是昆士兰州牧场草原的本地物种。它们包括:"Chinee apple", "Snake weed", "Lantana", "Prickly acacia", "Siam weed", "Parthenium", "Rubber vine" and "Parkinsonia". 这些图像是从昆士兰州以下地点的杂草侵扰中收集的地点收集:"Black River", "Charters Towers", "Cluden", "Douglas", "Hervey Range", "Kelso", "McKinlay" and "Paluma". 下表和图表按杂草、位置和地理分布对数据集进行了细分。
-
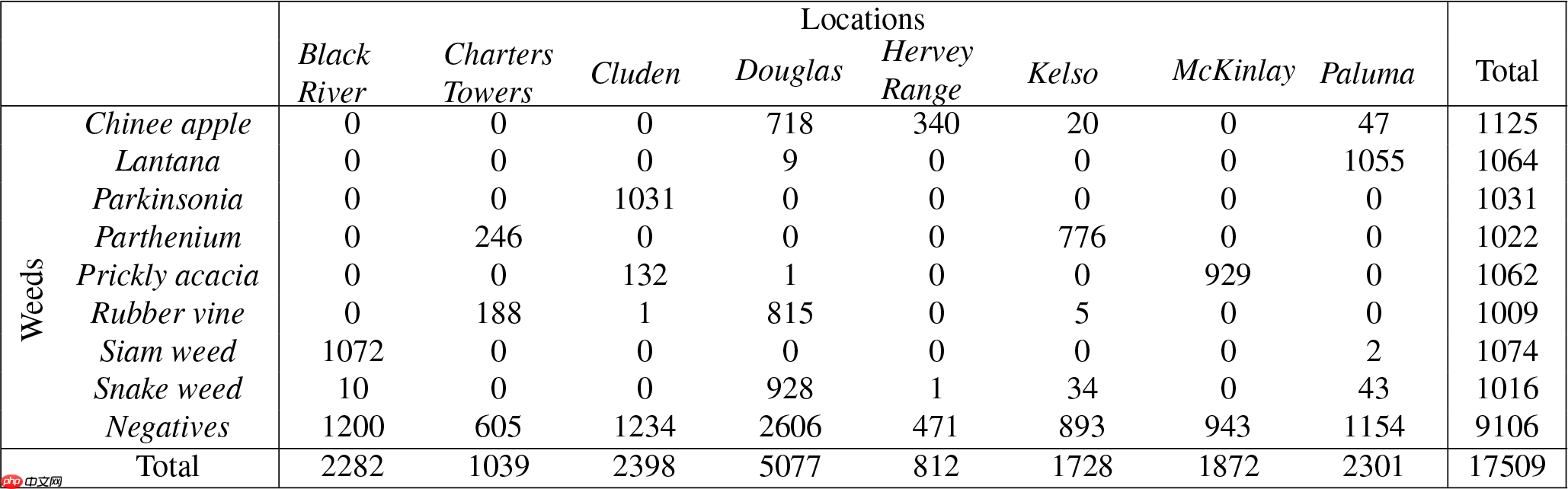
-
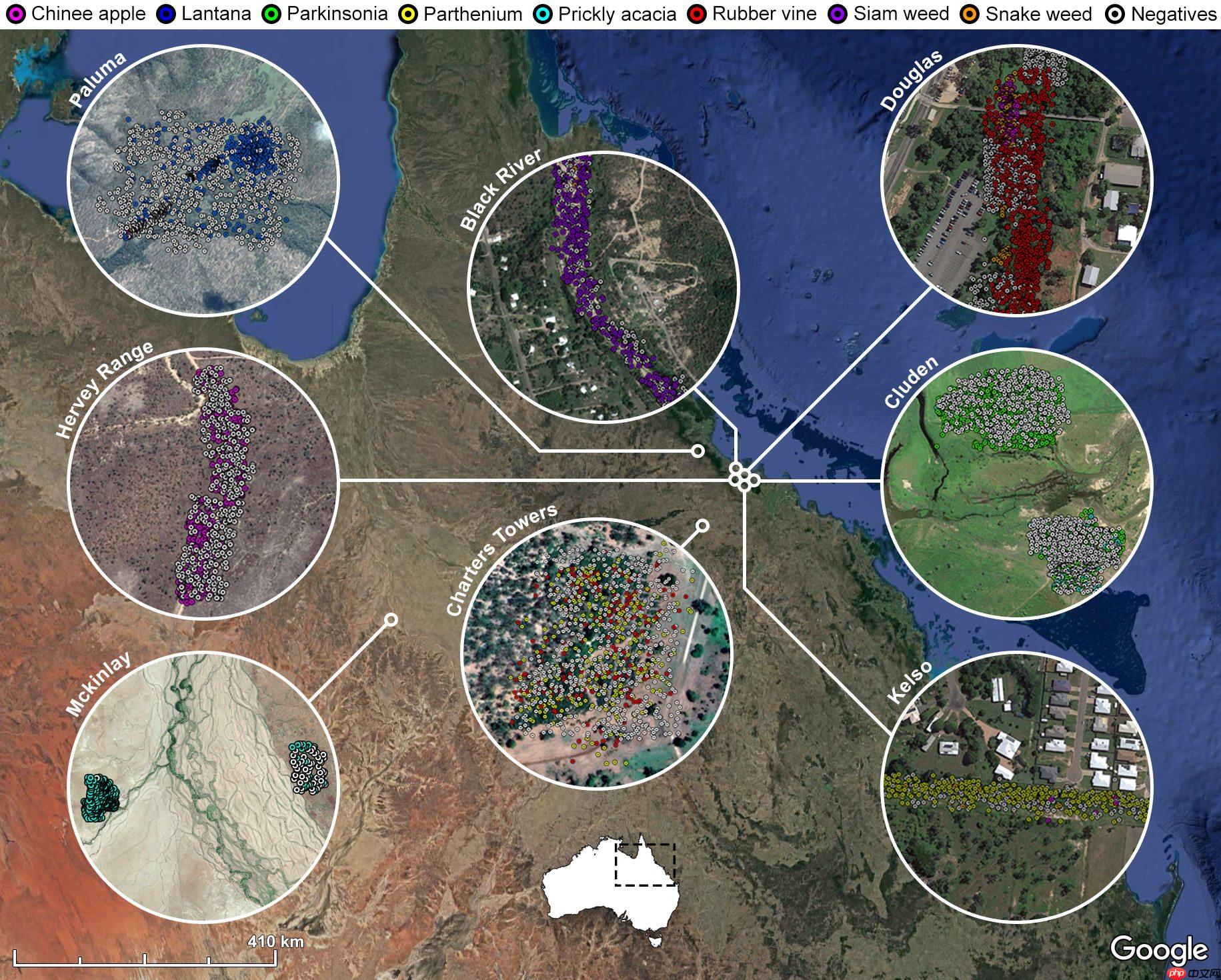
- 此数据集的采集更加贴合在自然环境当中,注重实用性。
-

- (a) 在受控实验室环境中拍摄的马缨丹叶图像。(b) 来自DeepWeeds数据集的马缨丹样本图像,原位拍摄,捕捉整个植物的真实视图。
二、模型介绍
- 通过与多个模型的对比,最终我们选择了ResNet50模型
-
ResNet50
- Resnet50 网络中包含了 49 个卷积层、一个全连接层。如图下图所示,Resnet50网络结构可以分成七个部分,第一部分不包含残差块,主要对输入进行卷积、正则化、激活函数、最大池化的计算。第二、三、四、五部分结构都包含了残差块,图 中的绿色图块不会改变残差块的尺寸,只用于改变残差块的维度。在 Resnet50 网 络 结 构 中 , 残 差 块 都 有 三 层 卷 积 , 那 网 络 总 共 有1+3×(3+4+6+3)=49个卷积层,加上最后的全连接层总共是 50 层,这也是Resnet50 名称的由来。网络的输入为 224×224×3,经过前五部分的卷积计算,输出为 7×7×2048,池化层会将其转化成一个特征向量,最后分类器会对这个特征向量进行计算并输出类别概率。
-

三、数据处理

In [ ]
!mkdir img !unzip /home/aistudio/data/data200134/images.zip -d /home/aistudio/img
In [3]
# 导入相关包from sklearn.utils import shuffleimport osimport pandas as pdimport numpy as npfrom PIL import Imageimport paddleimport paddle.nn as nnfrom paddle.io import Datasetimport paddle.vision.transforms as Timport paddle.nn.functional as Ffrom paddle.metric import Accuracyimport random
- 据官方paddleclas的提示,我们需要把图像变为两个txt文件
- train_txt,val_txt方便训练时读取数据集
In [4]
dirpath = "img"# 先得到总的txt后续再进行划分,因为要划分出验证集,所以要先打乱,因为原本是有序的def get_all_txt():
all_list = []
i = 0
for root in os.listdir(dirpath):
i = i + 1
if("0.jpg" in root):
all_list.append(os.path.join(root)+" 0\n") if("1.jpg" in root):
all_list.append(os.path.join(root)+" 1\n") if("2.jpg" in root):
all_list.append(os.path.join(root)+" 2\n") if("3.jpg" in root):
all_list.append(os.path.join(root)+" 3\n") if("4.jpg" in root):
all_list.append(os.path.join(root)+" 4\n") if("5.jpg" in root):
all_list.append(os.path.join(root)+" 4\n") if("6.jpg" in root):
all_list.append(os.path.join(root)+" 4\n") if("7.jpg" in root):
all_list.append(os.path.join(root)+" 4\n")
allstr = ''.join(all_list)
f = open('all_list.txt','w',encoding='utf-8')
f.write(allstr) return all_list , i
all_list,all_lenth = get_all_txt()print(all_lenth-1) # 有意者是预测的图片,得减去
17508
In [5]
#打乱原先循序random.shuffle(all_list) random.shuffle(all_list)
In [6]
#划分训练集和验证集train_size = int(15000) train_list = all_list[:train_size] val_list = all_list[train_size:]print(len(train_list))print(len(val_list))
15000 2509
In [7]
# 运行cell,生成txt train_txt = ''.join(train_list)
f_train = open('train_list.txt','w',encoding='utf-8')
f_train.write(train_txt)
f_train.close()print("train_list.txt 生成成功!")
train_list.txt 生成成功!
In [8]
# 运行cell,生成txtval_txt = ''.join(val_list)
f_val = open('val_list.txt','w',encoding='utf-8')
f_val.write(val_txt)
f_val.close()print("val_list.txt 生成成功!")
val_list.txt 生成成功!
四、模型训练
In [9]
!unzip -oq /home/aistudio/data/data98136/PaddleClas-release-2.1.zip
- 由于使用的是相对路径,所以我们需要把生成的数据列表移动到“/home/aistudio/PaddleClas-release-2.1/dataset”
In [11]
!mv img PaddleClas-release-2.1/dataset/ !mv all_list.txt PaddleClas-release-2.1/dataset/ !mv train_list.txt PaddleClas-release-2.1/dataset/ !mv val_list.txt PaddleClas-release-2.1/dataset/
In [13]
%cd PaddleClas-release-2.1!ls
/home/aistudio/PaddleClas-release-2.1 configs docs MANIFEST.in README_cn.md setup.py dataset __init__.py paddleclas.py README.md tools deploy LICENSE ppcls requirements.txt
- Paddleclas为我们提供了非常多模型,我们可以根据需求自行选择,"/home/aistudio/PaddleClas-release-2.1/configs"这是配置文件所在的路径,记得修改相关配置


In [ ]
#我们使用提前准备好的配置文件!python tools/train.py \
-c /home/aistudio/ResNet50.yaml
五、模型评估
- 在训练的过程中,PaddleClas就可以进行边训练边评估,并根据评估的精度值将最优模型参数存储在output/xxx/best_model目录中。 在训练结束后,可以再单独使用eval.py文件进行评估操作。 然后就可以使用存盘的模型文件进行模型预测,一般在研究阶段和比赛阶段,就是这样操作的。 在实际工业落地的时候,对速度要求更高,一般需要将存盘文件转换为推理模型,然后进行推理和部署。
In [ ]
!python tools/eval.py \
-c /home/aistudio/ResNet50.yaml \
-o pretrained_model="/home/aistudio/PaddleClas-release-2.1/output/ResNet50/best_model"\
-o load_static_weights=False
- 模型训练完成之后,可以加载训练得到的预训练模型(就是存盘文件),进行模型预测。在模型库的 tools/infer/infer.py 中提供了完整的示例,只需执行下述命令即可完成模型预测:
In [ ]
!python tools/infer/infer.py \
-i ~/work/test \
--model ResNet50 \
--pretrained_model "/home/aistudio/PaddleClas-release-2.1/output/ResNet50/best_models" \
--load_static_weights False \
--class_num=8




























