






本文介绍基于ResNet101神经网络的道路垃圾识别项目。先说明智慧环卫背景及项目意义,接着阐述数据集处理过程,包括解压缩、分离训练集与测试集、预处理及自定义数据集,还讲解了ResNet101网络搭建、训练(优化器、损失函数及训练过程)与预测阶段的实现,可减少环卫劳动力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1.前言
1.1.交流
学习深度学习不是简单的过程,好的开始是成功的一半,我当时学的时候也是一头雾水,只有坚持下去,就能成功,这篇文章我想给到写一个最基本的深度学习项目的一个思想。有什么错误,欢迎指正。有什么问题,也可以留言。
如果有什么看不懂的地方就从官网文档下手!只有官网文档才是最详细的讲解。
模型入门开发
paddle指令详细讲解!
1.2.项目背景
- 环境卫生是城市的名片,智慧环卫更是智慧城市中不可缺少的板块。
- 随着作业严格化、服务综合化、人口老龄化等趋势的发展,环卫行业面临诸多新问题和新挑战,而AI技术的发展成为一大助力,帮助环卫智能升级,实现设施智能化、运营管理信息化、分析决策智慧化。
- 对于现在严峻的环境,保护环境是根本的问题。
1.3.项目介绍
基于resnet101神经网络,通过对道路的分类,分类出有垃圾的道路和干净的道路。基础此可以大大减少这方面的劳动力。
2.数据集处理
2.1.数据集解压缩
首先想要训练一个神经网络,至少要有数据集,所以我们要从这里开始!、
解压缩数据集,默认压缩为目前路径。后面也可跟-d 完整路径/相对路径
! unzip -oq /home/aistudio/data/data199856/archive.zip
2.2.数据集分离训练集和测试集
该项目时通过自己自定义数据集,所以要通过代码实现图片路径和所对应的标签的分别写入train文本文档和text文本文档。在这里我是1:4的比例分离测试集和训练集。 其中会有.ipynb_checkpoints这样的文件,.ipynb_checkpoints 是 Jupyter Notebook 为了自动保存文件而创建的文件夹。当你在 Jupyter Notebook 中编辑并保存 notebook 文件时,系统会自动创建一个 .ipynb_checkpoints 文件夹,并在其中保存当前 notebook 的副本。这样,在意外关闭 Jupyter Notebook 或系统崩溃时,就可以使用这些副本恢复已经编辑过的内容。所以我们要在写到txt当中的时候,我们要将该文件删除。该文件找不到,因为它隐藏了。
os模块都是关于对文件系统操作的一个模块。其目的用于建立文件,获取文件中的一些信息。用处较多。
import osimport cv2
basedir=r'/home/aistudio/Images/Images' #基础文件list_dir=os.listdir(basedir) #获取图片文件夹中的图片名称并存放到列表中if '.ipynb_checkpoints' in list_dir: #如果含有该文件,删除该文件,防止写入txt文件当中
list_dir.remove('.ipynb_checkpoints')
clean=[];ditty=[]for i in list_dir: if 'clean' in i :
clean.append(i) else:
ditty.append(i) #以1:4的比例划分训练集以及测试集with open('test_label.txt','w') as file: #写测试集的图片路径以及所对应的标签
for i in range(int(len(clean)/5)):
file.write(f'{clean[i]} 0\n') for j in range(int(len(ditty)/5)):
file.write(f'{ditty[j]} 1\n')with open('train_label.txt','w') as file: #写训练集的图片路径以及所对应的标签
for i in range(int(len(clean)/5),len(clean)):
file.write(f'{clean[i]} 0\n') for j in range(int(len(ditty)/5),len(ditty)):
file.write(f'{ditty[j]} 1\n')
2.3.数据预处理
在训练之前时,要进行数据预处理,数据预处理如下:
RandomResizedCrop是将输入图像按照随机大小和长宽比进行裁剪
RandomHorizontalFlip是基于概率来执行图片的水平翻转
ToTsensor将 PIL.Image 或 numpy.ndarray 转换成 paddle.Tensor。
Normalize是将输入数据调整为指定大小。
Compose是将用于数据集预处理的接口以列表的方式进行组合。
如果有其他想知道可以去官网看
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
官方文档数据预处理

import paddle.vision.transforms as transforms
data_transform = { "train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), "val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
2.4.使用 paddle.io.Dataset 自定义数据集
本项目需要自己的数据集,即道路检测数据集,定义如下,不是完全的与文档一样,文档中是将图片灰度形式返回。如果用文档中直接套的话,会报错,因为我在数据预处理是增加了RandomResizedCrop,该处理的是3维图片,灰度图不能被处理。下面的注释也很清楚的介绍哪一步是干什么的。
import osimport cv2import numpy as npfrom paddle.io import Datasetimport matplotlib.pyplot as plt
train_data_dir='/home/aistudio/Images/Images'test_data_dir='/home/aistudio/Images/Images'test_label='/home/aistudio/test_label.txt'train_label='/home/aistudio/train_label.txt'class MyDataset(Dataset):
"""
步骤一:继承 paddle.io.Dataset 类
"""
def __init__(self, data_dir, label_path, transform=None):
"""
步骤二:实现 __init__ 函数,初始化数据集,将样本和标签映射到列表中
"""
super(MyDataset, self).__init__()
self.data_list = [] with open(label_path,encoding='utf-8') as f: for line in f.readlines():
image_path, label = line.strip().split(' ')
image_path = os.path.join(data_dir, image_path)
self.data_list.append([image_path, label]) # 传入定义好的数据处理方法,作为自定义数据集类的一个属性
self.transform = transform def __getitem__(self, index):
"""
步骤三:实现 __getitem__ 函数,定义指定 index 时如何获取数据,并返回单条数据(样本数据、对应的标签)
"""
# 根据索引,从列表中取出一个图像
image_path, label = self.data_list[index] # 读取图片
image = cv2.imread(image_path) # 飞桨训练时内部数据格式默认为float32,将图像数据格式转换为 float32
image = image.astype('float32') # 应用数据处理方法到图像上
if self.transform is not None:
image = self.transform(image) # CrossEntropyLoss要求label格式为int,将Label格式转换为 int
label = int(label) # 返回图像和对应标签
return image, label def __len__(self):
"""
步骤四:实现 __len__ 函数,返回数据集的样本总数
"""
return len(self.data_list)
# 打印数据集样本数 train_custom_dataset = MyDataset(train_data_dir,train_label, data_transform['train'])
test_custom_dataset = MyDataset(test_data_dir,test_label, data_transform['val'])print('train_custom_dataset images: ',len(train_custom_dataset), 'test_custom_dataset images: ',len(test_custom_dataset))for data in train_custom_dataset:
image, label = data print('shape of image: ',image.shape)
plt.title(str(label))
plt.imshow(image[0])
plt.show()
break
train_custom_dataset images: 192 test_custom_dataset images: 46 shape of image: [3, 224, 224]
<Figure size 640x480 with 1 Axes>

1.5.使用 paddle.io.DataLoader 定义数据读取器
上述的操作只是将我们的数据构造成了训练数据集和测试数据集
下面的操作是将迭代读取数据集,只有这样子才可以放到神经网络中进行‘ 炼丹 ’。
import paddle
train_loader = paddle.io.DataLoader(train_custom_dataset, batch_size=32, shuffle=True, num_workers=1, drop_last=True)
test_loader = paddle.io.DataLoader(test_custom_dataset, batch_size=32, shuffle=True, num_workers=1, drop_last=True)for batch_id, data in enumerate(train_loader()): #打印训练数据的shape 以及bachsize的数目
images, labels = data print("batch_id: {}, 训练数据shape: {}, 标签数据shape: {}".format(batch_id, images.shape, labels.shape)) breakfor batch_id, data in enumerate(test_loader()): #打印测试数据的shape 以及bachsize的数目
images, labels = data print("batch_id: {}, 测试数据shape: {}, 标签数据shape: {}".format(batch_id, images.shape, labels.shape)) break
batch_id: 0, 训练数据shape: [32, 3, 224, 224], 标签数据shape: [32] batch_id: 0, 测试数据shape: [32, 3, 224, 224], 标签数据shape: [32]
3.Resnet网络
3.1.什么是resnet网络
ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。resnet模型可以说是最经典的模型,它的残差结构到现在也在使用。所以该项目就以它来作为神经网络
3.2.网络中的亮点
1.超深的网络结构(可以超过1000层)。 2.提出residual(残差结构)模块。 3.使用Batch Normalization 加速训练(丢弃dropout)。
3.3.网络特点residual结构
esidual结构使用了一种shortcut的连接方式,也可理解为捷径。让特征矩阵隔层相加,注意F(X)和X形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加。
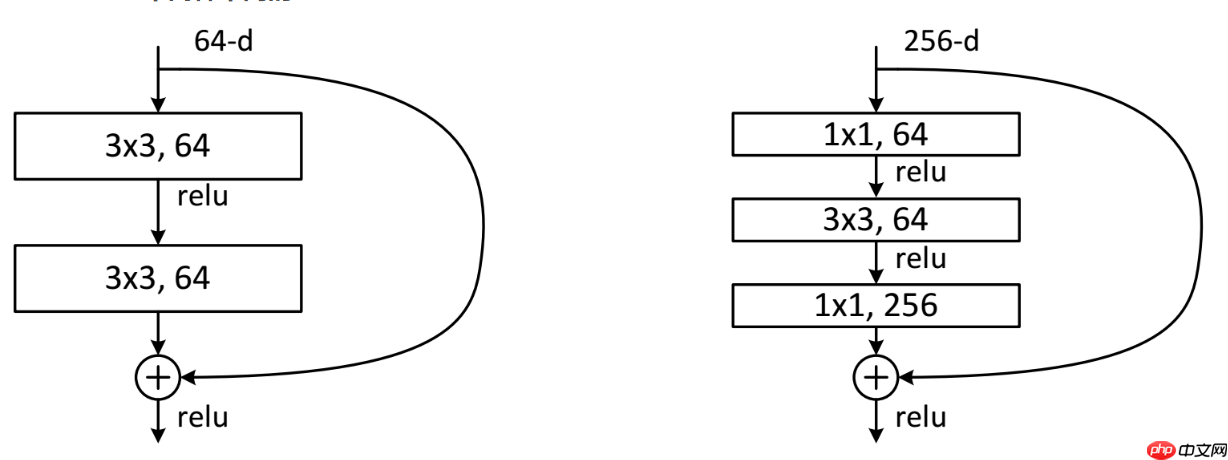
3.4.手工搭建神经网络
上面的数据集处理基本完成,现在我们需要一个搭建好的‘容器’去让这些数据放里面并且进行训练。
基本的网络结构就是如下
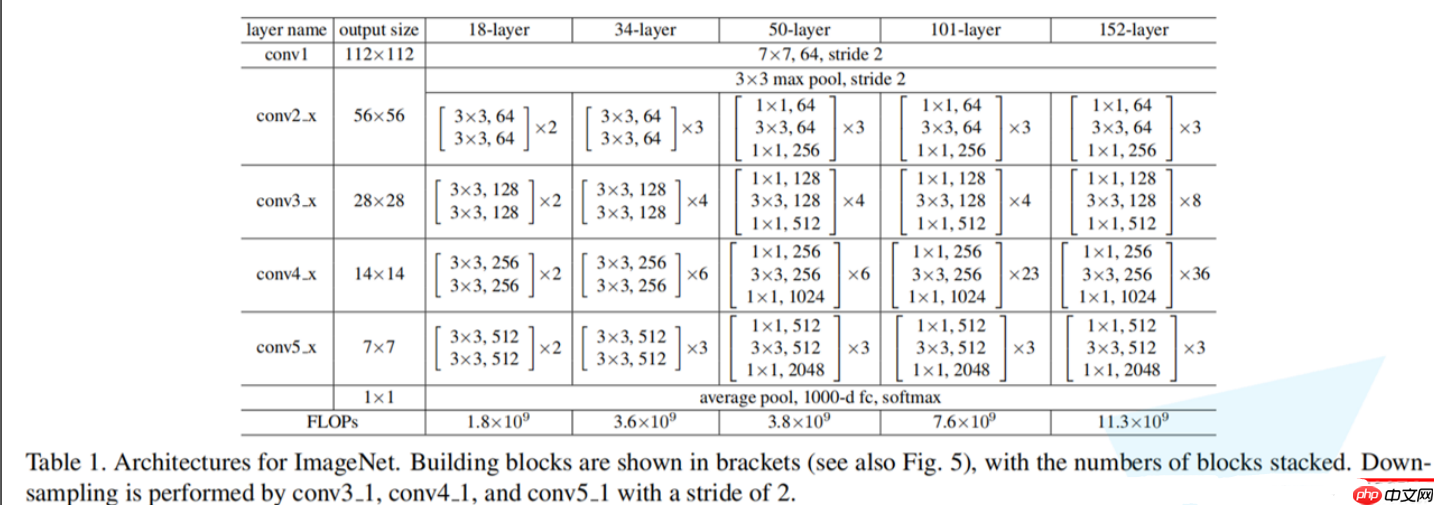
开始搭建网络!
搭建网络的时候要通过看上面网络结构进行构思,并且当写的时候一定要跟着BatchNorm2D和RELU,这都是要紧跟着conv2d的。
BatchNorm2D实现了批归一化层(Batch Normalization Layer)的功能,可用作卷积和全连接操作的批归一化函数,根据当前批次数据按通道计算的均值和方差进行归一化
RELU:稀疏 ReLU 激活层,创建一个可调用对象以计算输入 x 的 ReLU 。ReLU(x)=max(x,0)
import paddle.nn as nnimport paddle.nn.functional as Fimport paddleclass resnet101(nn.Layer):
def __init__(self,nums_classes):
super(resnet101,self).__init__()
self.nums_classes=nums_classes
self.first=nn.Sequential(
nn.Conv2D(3,64,7,stride=2,padding=3),
nn.BatchNorm2D(64),
nn.ReLU(),
nn.MaxPool2D(3,stride=2,padding=1)
)
self.second=self.add_layer(64,256,64,3)
self.third=self.add_layer(128,512,256,4,2)
self.forth=self.add_layer(256,1024,512,23,2)
self.fifth=self.add_layer(512,2048,1024,3,2)
self.avg_pool = nn.AvgPool2D(7)
self.fc = nn.Linear(2048,self.nums_classes) def add_layer(self,in_chnnel,out_chnnel,pre_chnnel,sums,stride=1):
layer=[]
layer.append(residual(in_chnnel,out_chnnel,pre_chnnel,stride)) for i in range(sums-1):
layer.append(residual(in_chnnel,out_chnnel,out_chnnel)) return nn.Sequential(*layer) def forward(self,x):
x=self.first(x)
x=self.second(x)
x=self.third(x)
x=self.forth(x)
x=self.fifth(x)
x=self.avg_pool(x)
x = paddle.flatten(x, 1)
x=self.fc(x) return x
class residual(nn.Layer): ##in_chnnel:本层需要的一开始的卷积后的维度
def __init__(self,in_chnnel,out_chnnel,pre_chnnel,stride=1): ##out_chnnel:本层最后输出的维度,
##pre_chnnel:表示前一层的输出维度
super(residual,self).__init__()
self.shorcut=None
if pre_chnnel!=out_chnnel: ##如果输入层为首层,需要通过卷积将输入的x升维到输出层,就像
self.shorcut=nn.Sequential(
nn.Conv2D(pre_chnnel,out_chnnel,1,stride,0),
nn.BatchNorm2D(out_chnnel)
)
self.first=nn.Sequential(
nn.Conv2D(pre_chnnel,in_chnnel,1,1,0),
nn.BatchNorm2D(in_chnnel),
nn.ReLU()
)
self.final=nn.Sequential(
nn.Conv2D(in_chnnel,in_chnnel,3,stride,1),
nn.BatchNorm2D(in_chnnel),
nn.ReLU(),
nn.Conv2D(in_chnnel,out_chnnel,1,1,0),
nn.BatchNorm2D(out_chnnel),
nn.ReLU()
) def forward(self,x):
y=self.first(x)
y=self.final(y) if self.shorcut is None: return F.relu(x+y) else: return F.relu(self.shorcut(x)+y)
net=resnet101(2)
params_info = paddle.summary(net,(1, 3, 224, 224))print(params_info)
3.训练阶段
3.1.定义优化器以及损失函数
一个完整的模型除了有神经网络还有所对应的优化器以及损失函数,如下面所示
import paddle## 将resnet模型及其所有子层设置为训练模式。这只会影响某些模块,如Dropout和BatchNorm。net.train() optim=paddle.optimizer.Adam(learning_rate=0.001,parameters=net.parameters()) loss_fun=paddle.nn.CrossEntropyLoss()
3.2.开始训练
# 设置迭代次数epochs = 36paddle.device.set_device('gpu:0')
bestacc=0for epoch in range(epochs):
net.train() for batch_id, data in enumerate(train_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 训练数据标签
predicts = net(x_data) # 预测结果
# 计算损失
loss = loss_fun(predicts, y_data) # 反向传播
loss.backward() if (batch_id) % 2 == 0:
acc=(np.sum(predicts.argmax(1).numpy()==y_data.numpy()))/len(y_data) print("train epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id+1, loss.numpy(), acc)) # 更新参数
optim.step() # 梯度清零
optim.clear_grad() if epoch % 5==0:
net.eval() for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 测试数据
y_data = data[1] # 测试数据标签
predicts = net(x_data) # 预测结果
# 计算损失与精度
loss = loss_fun(predicts, y_data) # 打印信息
acc=(np.sum(predicts.argmax(1).numpy()==y_data.numpy()))/len(y_data) print("test batch_id: {}, loss is: {}, curr_acc is: {} bestacc is {}".format(batch_id+1, loss.numpy(), acc, bestacc)) if bestacc<acc:
bestacc=acc
paddle.save(net.state_dict(), "resnet1_net.pdparams")
由于数据集不是很多,所以导致数据的精确不是很高,只有90%左右的准确率,不过也是够用了。
4.预测阶段
4.1.测试集预测
在评估的时候,我们也将最高的精确度的模型权重保存了下来,现在我们使用测试集预测一下道路干不干净。并输出总精度
pre_net=resnet101(2)
layer_state_dict=paddle.load('/home/aistudio/resnet1_net.pdparams')
pre_net.set_state_dict(layer_state_dict)
pre_net.eval()#使用测试集来看看精度for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 测试数据
y_data = data[1] # 测试数据标签
predicts = pre_net(x_data) # 预测结果
print(predicts.numpy()) print('预测的标签信息为:',predicts.argmax(1).numpy()) print('真实的标签信息为:',y_data.numpy()) # 打印信息
acc=(np.sum(predicts.argmax(1).numpy()==y_data.numpy()))/len(y_data) print("test batch_id: {} acc is: {}".format(batch_id, acc))
4.2.个体预测
个体预测时只需要读取一张图片,然后增加一个维度,就可以放入到神经网络,进行识别是否是干净的道路
import paddle
image=cv2.imread(r'/home/aistudio/Images/Images/clean_7.jpg')
image=data_transform['val'](image)
plt.rcParams['font.sans-serif']=['FZHuaLi-M14S']
plt.imshow(image[0])
plt.title('')
image=paddle.reshape(image,[1,3,224,224])
predict=pre_net(image)print(predict.numpy()) #明显可以看出是第0个标签大,即干净的道路if predict.argmax(1)==0:
plt.title('干净的道路')else:
plt.title('不干净的道路')
plt.show()
[[2.4930854 1.1419637]]
<Figure size 640x480 with 1 Axes>




























