






“中国软件杯”3D智慧医疗赛题要求基于百度飞桨,完成3D医疗数据分割算法及WEB解析平台开发。算法需用PaddleSeg的MedicaSeg,以AMOS2022数据集(含11个器官标注)训练,采用nnunet模型;平台需实现数据导入、分割等功能。baseline提供了克隆仓库、数据处理、训练推理等全流程操作及权重快速推理方案。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

“中国软件杯”大学生软件设计大赛-3D智慧医疗baseline
比赛介绍
“中国软件杯”大学生软件设计大赛是一项面向中国在校学生的公益性赛事,是2022年全国普通高校大学生竞赛榜单内竞赛。大赛由国家工业和信息化部、教育部、江苏省人民政府共同主办,致力于正确引导我国在校学生积极参加软件科研活动,切实增强自我创新能力和实际动手能力,为我国软件和信息技术服务业培养出更多高端、优秀的人才。
赛题背景
为进一步加强新一代智能技术与医学的深度融合,百度设立了“基于百度飞桨的3D 医疗数据解析平台”的企业赛题,将来自智慧医疗产业一线的系统建设需求,与高校赛训内容相结合,以助力高校复合交叉型AI人才培养,更好促进我国未来智慧医疗产业的健康发展。
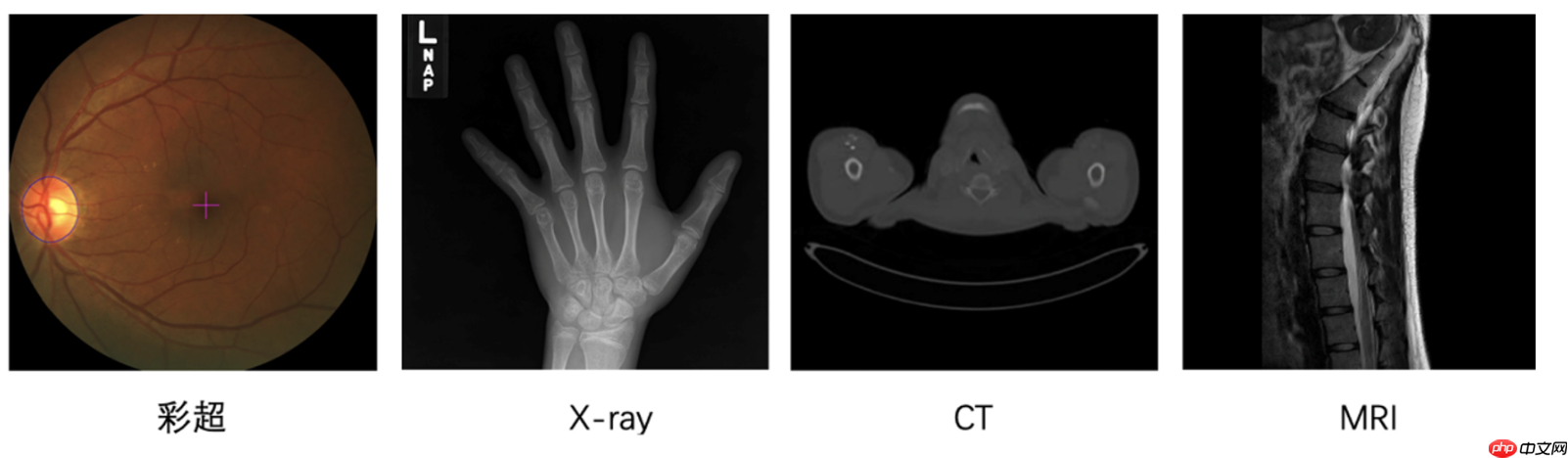
医学影像是临床疾病诊断的重要方式,高效精准的从影像中识别出器官结构或病变,是医学影像学中重要的课题。根据成像原理,医疗影像可以粗略分为两类:
2D成像:一种是在可见光下获取的RGB彩照,如眼底彩照、皮肤彩照等;
3D成像:借助非可见光或其它物理效应,由计算机辅助成像,如CXR/DR(X-Ray),CT,核磁共振(MRI)等。如CT与MRI数据是多个2D切片沿第三个空间维度堆叠而成的;
其中,3D影像能够更直观辅助医生提升诊断效率。然而,医疗影像的读片工作对专业知识要求高,这样繁重且重复性较高的阅片工作,仅能由专业的影像科医生完成。另一方面,医疗影像在医学检查中愈发常见,对阅片专家的需求也在增加。随着深度学习技术的发展,我们看到了使用AI技术辅助医生快速分析阅片、减轻阅片工作负担的可能性。
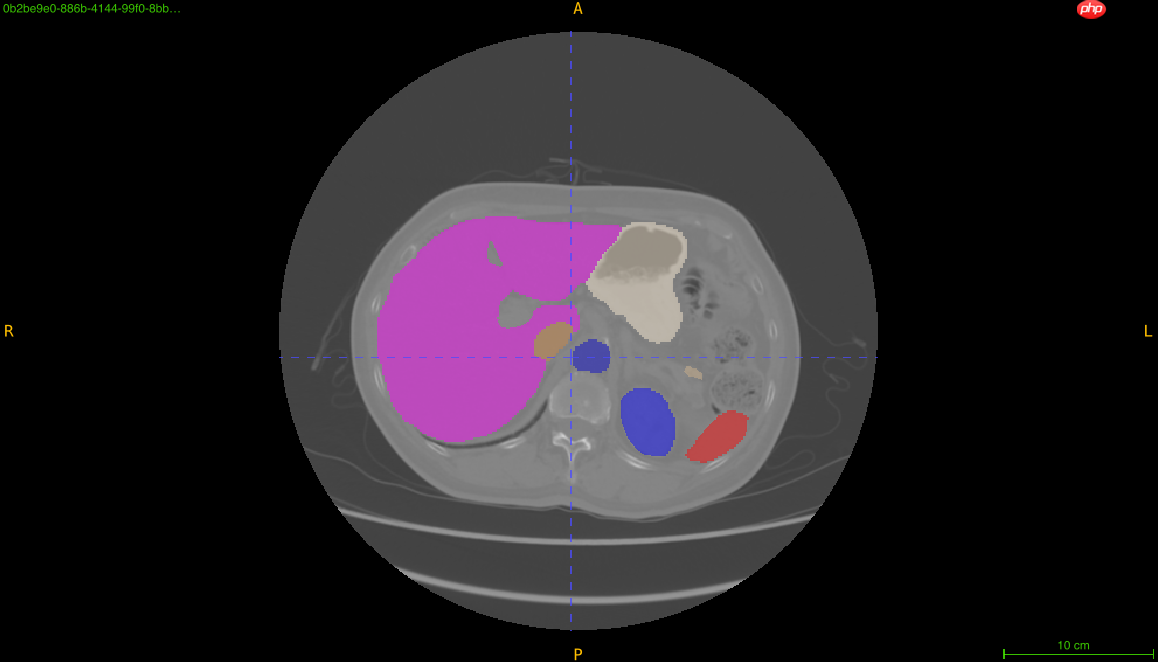
本次竞赛抽取AMOS2022数据集中的部分数据作为训练和评测数据。 注意:本比赛只允许使用提供的数据集。
赛题任务
为更好满足医疗从业者快速构建医疗识别模型及高效进行图像分析的需求,参赛选手需利用深度学习和软件开发技术实现以下两部分内容:

- 算法部分:要求选手基于PaddlePaddle,在官方指定数据集上进行打榜,实现在验证集上,给定任一3D医疗数据,准确地完成医学数据的分割任务,并且在新的、未进行过训练的数据集上能够获得较好的泛化性能。
- 软件部分:要求选手实现基于WEB的3D医疗数据解析平台,其中包含医疗数据的导入、分割、可视化和数据分析功能四大基础功能,且飞桨模型可在本地或云端部署进行推理。选手可设计更多相关场景的附加功能,通过稳定的软件功能和优秀的人机交互,为非AI专业人员提供良好用户体验。
数据集介绍
多器官数据集共有11个器官的标注,包括脾脏、右肾、左肾、胆囊、食道、肝、胃、主动脉、下腔静脉、胰腺、膀胱。本数据集共包含160个训练数据,40个测试数据。
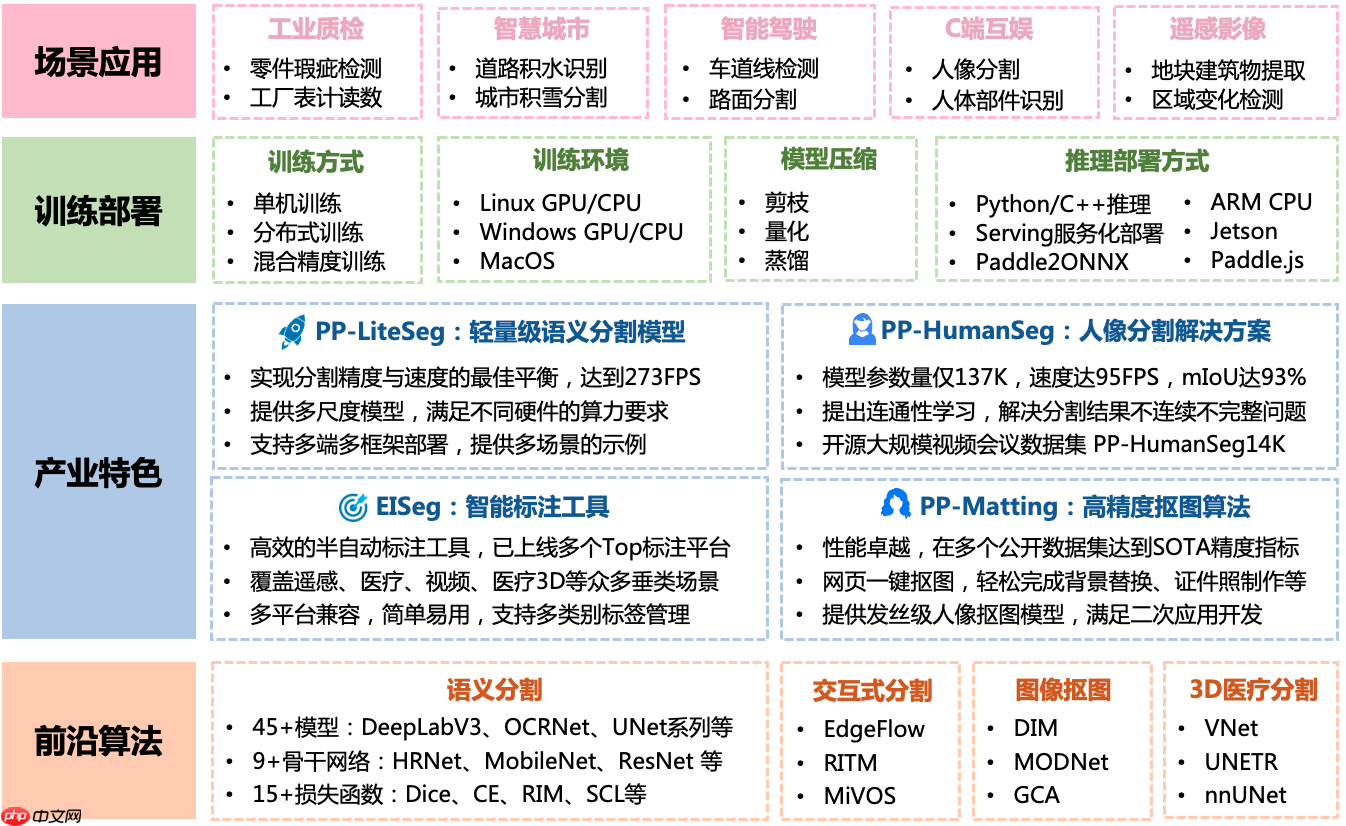
PaddleSeg介绍
PaddleSeg是基于飞桨PaddlePaddle的端到端图像分割套件,内置45+模型算法及140+预训练模型,支持配置化驱动和API调用开发方式,打通数据标注、模型开发、训练、压缩、部署的全流程,提供语义分割、交互式分割、Matting、全景分割四大分割能力,助力算法在医疗、工业、遥感、娱乐等场景落地应用。
本baseline使用PaddleSeg的MedicaSeg开发,github地址:https://github.com/PaddlePaddle/PaddleSeg
老爷们,动动发财的小手,点点star为我们助力,您的支持就是我们的动力~~
# step 1: 克隆PaddleSeg仓库%cd ~/ !git clone --branch develop --depth 1 https://github.com/PaddlePaddle/PaddleSeg.git %cd ~/PaddleSeg
# step2: 解压数据到~/PaddleSeg/contrib/MedicalSeg/data/raw_data!mkdir ~/PaddleSeg/contrib/MedicalSeg/data !unzip -oq ~/data/data204195/base_train.zip -d ~/PaddleSeg/contrib/MedicalSeg/data/raw_data
# step 3: 删除原本的数据集压缩包,节约内存!rm -rf ~/data/data204195/base_train.zip
# 删除掉数据集中一个没用的文件夹,否则会报错!rm -rf ~/PaddleSeg/contrib/MedicalSeg/data/raw_data/.ipynb_checkpoints
###### step 4: 安装依赖包%cd ~/PaddleSeg/contrib/MedicalSeg/ !pip install -r requirements.txt !pip install medpy
# step 5: nnunet cascade lowres训练,混合精度训练快一些,五折训练,这里使用fold 2,一共有0,1,2,3,4共五个fold。# 在训练之前,会先对数据进行预处理,如果觉得耗时过久怀疑出错,可以看一下PaddleSeg/contrib/Medicalseg/data目录里面是否有decathlon、preprocessed、cropped 3个文件夹# 没有这3个文件夹请耐心等待。# 为什么会报错json文件缺失?# 预处理的过程不可中断,如果中断可能导致部分文件丢失,可以把decathlon、preprocessed、cropped报错的文件夹删除,重新生成即可。# 什么是交叉训练?# 假设有100条数据,使用五折交叉验证训练。可以把数据集分为 |20|20|20|20|20|,每次训练的时候,把其中一个作为验证集,其他作为训练集,这样可以得到5个模型,他们的验证集不重复。%cd ~/PaddleSeg/contrib/MedicalSeg/
!python train.py --config ~/configs/nnunet_fold2.yml \
--log_iters 20 --precision fp16 --nnunet --save_dir output/cascade_lowres/fold2 --save_interval 2000 --use_vdl # --resume_model output/cascade_lowres/fold2/iter_30000
# 为了防止内存溢出,请替换cascade预测下一阶段的部分代码!mv ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/cascade_utils.py ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/cascade_utils_backup.py !cp ~/cascade_utils.py ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/
# step 6: fold2的数据集划分验证一下精度,运行一下,生成下个命令需要用的json,如果不使用后处理策略可以不运行# 有的数据很大,可能导致内存溢出,可以切换A100环境预测下一阶段# 可以除去--predict_next_stage参数,不预测该数据的下一阶段# predict_next_stage的作用是什么?# cascade unet分为2阶段,第一阶段会把分辨率降低进行训练,增强模型的感受野。第二阶段会把第一阶段的模型预测结果和原始数据一起作为输入,所以训练low resolution模型后,# 需要预测下一阶段的输入数据。# 交叉验证和二阶段训练结合为什么这么难懂?# 一阶段交叉训练:|20|20|20|20|20|# 二阶段交叉训练:|20(concat(原始数据,一阶段预测的结果))|20(concat(原始数据,一阶段预测的结果))|20(concat(原始数据,一阶段预测的结果))|20(concat(原始数据,一阶段预测的结果))|20(concat(原始数据,一阶段预测的结果))|# 为了训练第二阶段,需要使用五个模型预测整个数据集,这样二阶段才能训练。%cd ~/PaddleSeg/contrib/MedicalSeg/
!python nnunet/single_fold_eval.py --config ~/configs/nnunet_fold2.yml \
--model_path output/cascade_lowres/fold2/iter_30000/model.pdparams --val_save_folder output/cascade_lowres_val \
--precision fp16 --predict_next_stage
## 可选步骤:先运行step 7,如果提示内存溢出则运行此命令,替代原本的推理代码!mv ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/predict_utils.py ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/predict_utils_old.py !cp ~/predict_utils.py ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/
# step 7: 推理# 为什么要用json文件?# nnunet采用了后处理策略对预测结果进行修正,但是后处理策略是否一定会涨点呢?对每个类别,对比使用了后处理和不使用后处理策略的精度,这样就可以决定每个类别是否使用后处理策略。# 需要后处理涨点的类别存放在json中,这是json的作用。# 是否一定要该折对应的json?# 不是,json只是决定某个类别是否使用后处理,即使使用其他折的json,也可以预测,但是后处理的类别可能会错误,这个时候后处理的预测结果不可靠。# 不希望使用后处理策略怎么办?# 命令中加上--disable_postprocessing即可%cd ~/PaddleSeg/contrib/MedicalSeg/
!python nnunet/predict.py --image_folder data/decathlon/imagesTs \
--output_folder ~/submit \
--plan_path data/preprocessed/nnUNetPlansv2.1_plans_3D.pkl \
--model_paths output/cascade_lowres/fold2/iter_30000/model.pdparams \
--postprocessing_json_path output/cascade_lowres_val/postprocessing.json --model_type cascade_lowres \
--num_threads_preprocessing 1 --num_threads_nifti_save 1
# step 8: 打包提交,生成submit.zip,在/home/aistudio目录下!zip -j ~/submit.zip ~/submit/*.nii.gz
nnunet高精度模型 推理-提交全流程
使用提供的权重,快速进行推理提交
# step 1: 克隆PaddleSeg仓库--已有请忽略%cd ~/ !git clone https://github.com/PaddlePaddle/PaddleSeg.git %cd ~/PaddleSeg
# step2: 解压数据到~/PaddleSeg/contrib/MedicalSeg/data/raw_data --- 如果已经运行过数据预处理,请忽略。~/PaddleSeg/contrib/MedicalSeg/data这个目录下是否有decalthon和preprocess这2个文件夹!mkdir ~/PaddleSeg/contrib/MedicalSeg/data !unzip -oq ~/data/data204195/base_train.zip -d ~/PaddleSeg/contrib/MedicalSeg/data/raw_data
# step 3: 删除原本的数据集压缩包,节约内存!rm -rf ~/data/data204195/base_train.zip
# 删除掉数据集中一个没用的文件夹,否则会报错!rm -rf ~/PaddleSeg/contrib/MedicalSeg/data/raw_data/.ipynb_checkpoints
# step 4: 安装依赖包 --- 已安装请忽略%cd ~/PaddleSeg/contrib/MedicalSeg/ !pip install -r requirements.txt !pip install medpy
# step 5: fold2的数据集验证一下精度,这里的目的是触发数据预处理,不然step 6没法推理,如果PaddleSeg/contrib/MedicalSeg/data/decathlon文件夹存在,可以跳过%cd ~/PaddleSeg/contrib/MedicalSeg/
!python nnunet/single_fold_eval.py --config ~/configs/nnunet_fold2.yml \
--model_path ~/baseline_model/model.pdparams --val_save_folder output/cascade_lowres_val \
--precision fp16
## 可选步骤:先运行step 6,如果提示内存溢出则运行此命令,替代原本的推理代码!mv ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/predict_utils.py ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/predict_utils_old.py !cp ~/predict_utils.py ~/PaddleSeg/contrib/MedicalSeg/nnunet/utils/
# step 6: 使用提供的权重推理,nnunet默认使用tta策略,速度比较慢%cd ~/PaddleSeg/contrib/MedicalSeg/
!python nnunet/predict.py --image_folder data/decathlon/imagesTs \
--output_folder ~/submit \
--plan_path data/preprocessed/nnUNetPlansv2.1_plans_3D.pkl \
--model_paths ~/baseline_model/model.pdparams \
--postprocessing_json_path ~/baseline_model/postprocessing.json --model_type cascade_lowres \
--num_threads_preprocessing 1 --num_threads_nifti_save 1 --precision fp16
# step 7: 打包提交,生成submit.zip,在/home/aistudio目录下!zip -j ~/submit.zip ~/submit/*.nii.gz




























