







文 |ai_study

原标题:Neural Network Batch Processing - Pass Image Batch To PyTorch CNN
准备数据建立模型了解批处理如何传递到网络训练模型分析模型的结果在上一节中,我们了解了前向传播以及如何将单个图像从训练集中传递到我们的网络。现在,让我们看看如何使用一批图像来完成此操作。我们将使用数据加载器来获取批处理,然后,在将批处理传递到网络之后,我们将解释输出。
传递一个 batch的图像到网络首先,回顾一下上一节的代码设置。我们需要以下内容:
imports。训练集。网络类定义。To disable gradient tracking。(可选的)网络类实例。现在,我们将使用我们的训练集来创建一个新的DataLoader实例,并设置我们的batch_size = 10,这样输出将更易于管理。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> data_loader = torch.utils.data.DataLoader( train_set, batch_size=10)</code>
我们将从数据加载器中提取一个批次,并从该批次中解压缩图像和标签张量。我们将使用复数形式命名变量,因为当我们在数据加载器迭代器上调用next时,我们知道数据加载器会返回一批10张图片。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> batch = next(iter(data_loader))> images, labels = batch</code>
这给了我们两个张量,一个图像张量和一个对应标签的张量。
在上一节中,当我们从训练集中提取单个图像时,我们不得不unsqueeze() 张量以添加另一个维度,该维度将有效地将单例图像转换为一个大小为1的batch。现在我们正在使用数据加载器,默认情况下我们正在处理批处理,因此不需要进一步的处理。
数据加载器返回一批图像,这些图像被打包到单个张量中,该张量具有反映以下轴的形状。
这意味着张量的形状是良好的形状,无需将其unsqueeze()。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> images.shapetorch.Size([10, 1, 28, 28])> labels.shapetorch.Size([10])</code>
让我们解释这两种形状。图像张量的第一个轴告诉我们,我们有一批十张图像。这十个图像具有一个高度和宽度为28的单一颜色通道。
标签张量的单轴形状为10,与我们批中的十张图像相对应。每个图像一个标签。
好的。通过将图像张量传递到网络来进行预测。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> preds = network(images)> preds.shapetorch.Size([10, 10])> predstensor( [ [ 0.1072, -0.1255, -0.0782, -0.1073, 0.1048, 0.1142, -0.0804, -0.0087, 0.0082, 0.0180], [ 0.1070, -0.1233, -0.0798, -0.1060, 0.1065, 0.1163, -0.0689, -0.0142, 0.0085, 0.0134], [ 0.0985, -0.1287, -0.0979, -0.1001, 0.1092, 0.1129, -0.0605, -0.0248, 0.0290, 0.0066], [ 0.0989, -0.1295, -0.0944, -0.1054, 0.1071, 0.1146, -0.0596, -0.0249, 0.0273, 0.0059], [ 0.1004, -0.1273, -0.0843, -0.1127, 0.1072, 0.1183, -0.0670, -0.0162, 0.0129, 0.0101], [ 0.1036, -0.1241245, -0.0842, -0.1047, 0.1097, 0.1176, -0.0682, -0.0126, 0.0128, 0.0147], [ 0.1093, -0.1292, -0.0961, -0.1006, 0.1106, 0.1096, -0.0633, -0.0163, 0.0215, 0.0046], [ 0.1026, -0.1204, -0.0799, -0.1060, 0.1077, 0.1207, -0.0741, -0.0124124, 0.0098, 0.0202], [ 0.0991, -0.1275, -0.0911, -0.0980, 0.1109, 0.1134, -0.0625, -0.0391, 0.0318, 0.0104], [ 0.1007, -0.1212, -0.0918, -0.0962, 0.1168, 0.1105, -0.0719, -0.0265, 0.0207, 0.0157] ])</code>
预测张量的形状为10 x 10,这给了我们两个长度为10的轴。这反映了以下事实:我们有十个图像,并且对于这十个图像中的每一个,我们都有十个预测类别。
第一维的元素是长度为十的数组。这些数组元素中的每一个包含对应图像每个类别的十个预测。
第二维的元素是数字。每个数字都是特定输出类别的分配值。输出类别由索引编码,因此每个索引代表一个特定的输出类别。该映射由该表给出。
Fashion MNIST 类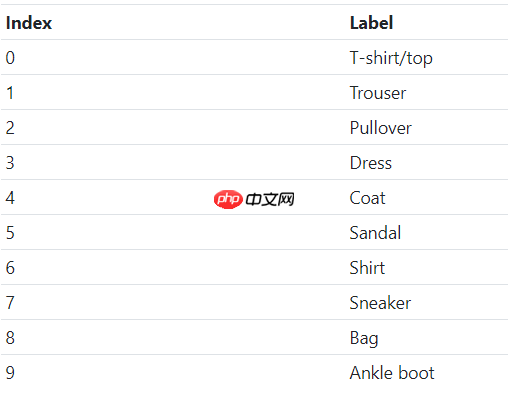

为了对照标签检查预测,我们使用argmax() 函数找出哪个索引包含最高的预测值。一旦知道哪个索引具有最高的预测值,就可以将索引与标签进行比较,以查看是否存在匹配项。

为此,我们在预测张量上调用argmax() 函数,并指定第二维。
第二个维度是我们的预测张量的最后一个维度。请记住,在我们所有关于张量的工作中,张量的最后一个维度始终包含数字,而其他所有维度都包含其他较小的张量。
在预测张量的情况下,我们有十组数字。argmax() 函数的作用是查看这十组中的每组,找到最大值,然后输出其索引。
对于每组十个数字:
查找最大值。输出指标对此的解释是,对于批次中的每个图像,我们正在找到具有最高值的预测类别(每列的最大值)。这是网络预测的类别。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> preds.argmax(dim=1)tensor([5, 5, 5, 5, 5, 5, 4, 5, 5, 4])> labelstensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])</code>
argmax() 函数的结果是十个预测类别的张量。每个数字是出现最大值的索引。我们有十个数字,因为有十个图像。一旦有了这个具有最大值的索引张量,就可以将其与标签张量进行比较。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> preds.argmax(dim=1).eq(labels)tensor([0, 0, 0, 0, 0, 0, 0, 0, 1, 0], dtype=torch.uint8)> preds.argmax(dim=1).eq(labels).sum()tensor(1)</code>
为了实现比较,我们使用eq() 函数。eq() 函数计算argmax输出和标签张量之间的逐元素相等运算。
如果argmax输出中的预测类别与标签匹配,则为1,否则为0。
最后,如果在此结果上调用sum() 函数,则可以将输出缩减为该标量值张量内的单个正确预测数。
我们可以将最后一个调用包装到名为get_num_correct() 的函数中,该函数接受预测和标签,并使用item()方法返回Python数目的正确预测。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">def get_num_correct(preds, labels): return preds.argmax(dim=1).eq(labels).sum().item()</code>
调用此函数,我们可以看到我们得到了值1。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">> get_num_correct(preds, labels)1</code>总结
现在,我们应该对如何将一批输入传递到网络以及在处理卷积神经网络时预期的形状有一个很好的了解。
文章中内容都是经过仔细研究的,本人水平有限,翻译无法做到完美,但是真的是费了很大功夫,希望小伙伴能动动你性感的小手,分享朋友圈或点个“在看”,支持一下我 ^_^
英文原文链接是:
https://deeplizard.com/learn/video/p1xZ2yWU1eo




























