






超分辨率重建通过软件方法从低分辨率图像恢复高分辨率图像,可降低硬件成本,满足多领域需求。常用PSNR、SSIM评价效果。EDSR是较优方法,去除BN层,性能提升,文中还涉及其数据集处理、网络结构及训练测试等内容,效果优于双线性插值。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

超分辨率重建
意义
客观世界的场景含有丰富多彩的信息,但是由于受到硬件设备的成像条件和成像方式的限制,难以获得原始场景中的所有信息。而且,硬件设备分辨率的限制会不可避免地使图像丢失某些高频细节信息。在当今信息迅猛发展的时代,在卫星遥感、医学影像、多媒体视频等领域中对图像质量的要求越来越高,人们不断寻求更高质量和更高分辨率的图像,来满足日益增长的需求。
空间分辨率的大小是衡量图像质量的一个重要指标,也是将图像应用到实际生活中重要的参数之一。分辨率越高的图像含有的细节信息越多,图像清晰度越高,在实际应用中对各种目标的识别和判断也更加准确。
但是通过提高硬件性能从而提高图像的分辨率的成本高昂。因此,为了满足对图像分辨率的需求,又不增加硬件成本的前提下,依靠软件方法的图像超分辨率重建应运而生。
超分辨率图像重建是指从一系列有噪声、模糊及欠采样的低分辨率图像序列中恢复出一幅高分辨率图像的过程。可以针对现有成像系统普遍存在分辨率低的缺陷,运用某些算法,提高所获得低分辨率图像的质量。因此,超分辨率重建算法的研究具有广阔的发展空间。
方法的具体细节
评价指标
峰值信噪比
峰值信噪比(Peak Signal-to-Noise Ratio), 是信号的最大功率和信号噪声功率之比,来测量被压缩的重构图像的质量,通常以分贝来表示。PSNR指标值越高,说明图像质量越好。
SSIM计算公式如下:
PSNR=10∗lgMSEMAXI2
MSE表示两个图像之间对应像素之间差值平方的均值。
MAXI 表示图像中像素的最大值。对于8bit图像,一般取255。
MSE=M∗N1i=1∑Nj=1∑M(fij−fij′)2
fij表示图像X在ij处的像素值
fij′表示图像Y在ij处的像素值
结构相似性评价
结构相似性评价(Structural Similarity Index), 是衡量两幅图像相似度的指标,取值范围为0到1。SSIM指标值越大,说明图像失真程度越小,图像质量越好。
SSIM计算公式如下:
L(X,Y)=μX2+μY2+C12μXμY+C1
C(X,Y)=σX2+σY2+C22σXσY+C2
S(X,Y)=σXσY+C3σXY+C3
SSIM(X,Y)=L(X,Y)∗C(X,Y)∗S(X,Y)

这两种方式,一般情况下能较为准确地评价重建效果。但是毕竟人眼的感受是复杂丰富的,所以有时也会出现一定的偏差。
EDSR

SRResNet在SR的工作中引入了残差块,取得了更深层的网络,而EDSR是对SRResNet的一种提升,其最有意义的模型性能提升是去除掉了SRResNet多余的模块(BN层)
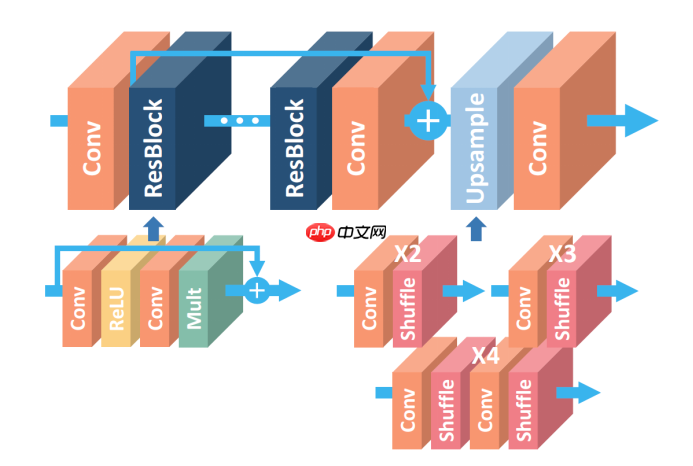
EDSR把批规范化处理(batch normalization, BN)操作给去掉了。
论文中说,原始的ResNet最一开始是被提出来解决高层的计算机视觉问题,比如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是最优的。由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1损失函数来优化网络模型。
1.解压数据集
因为训练时间可能不是很长,所以这里用了BSD100,可以自行更换为DIV2K或者coco
# !unzip -o /home/aistudio/data/data121380/DIV2K_train_HR.zip -d train
# !unzip -o /home/aistudio/data/data121283/Set5.zip -d test
2.定义dataset
import osfrom paddle.io import Datasetfrom paddle.vision import transformsfrom PIL import Imageimport randomimport paddleimport PILimport numbersimport numpy as npfrom PIL import Imagefrom paddle.vision.transforms import BaseTransformfrom paddle.vision.transforms import functional as Fimport matplotlib.pyplot as pltclass SRDataset(Dataset):
def __init__(self, data_path, crop_size, scaling_factor):
"""
:参数 data_path: 图片文件夹路径
:参数 crop_size: 高分辨率图像裁剪尺寸 (实际训练时不会用原图进行放大,而是截取原图的一个子块进行放大)
:参数 scaling_factor: 放大比例
"""
self.data_path=data_path
self.crop_size = int(crop_size)
self.scaling_factor = int(scaling_factor)
self.images_path=[] # 如果是训练,则所有图像必须保持固定的分辨率以此保证能够整除放大比例
# 如果是测试,则不需要对图像的长宽作限定
# 读取图像路径
for name in os.listdir(self.data_path):
self.images_path.append(os.path.join(self.data_path,name)) # 数据处理方式
self.pre_trans=transforms.Compose([ # transforms.CenterCrop(self.crop_size),
transforms.RandomCrop(self.crop_size),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5), # transforms.ColorJitter(brightness=0.3, contrast=0.3, hue=0.3),
])
self.input_transform = transforms.Compose([
transforms.Resize(self.crop_size//self.scaling_factor),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5]),
])
self.target_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5]),
]) def __getitem__(self, i):
# 读取图像
img = Image.open(self.images_path[i], mode='r')
img = img.convert('RGB')
img=self.pre_trans(img)
lr_img = self.input_transform(img)
hr_img = self.target_transform(img.copy())
return lr_img, hr_img def __len__(self):
return len(self.images_path)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized
测试dataset
# 单元测试train_path='train/DIV2K_train_HR'test_path='test'ds=SRDataset(train_path,96,2)
l,h=ds[1]# print(type(l))print(l.shape)print(h.shape)
l=np.array(l)
h=np.array(h)print(type(l))
l=l.transpose(2,1,0)
h=h.transpose(2,1,0)print(l.shape)print(h.shape)
plt.subplot(1, 2, 1)
plt.imshow(((l+1)/2))
plt.title('l')
plt.subplot(1, 2, 2)
plt.imshow(((h+1)/2))
plt.title('h')
plt.show()W1225 11:33:49.800403 8727 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W1225 11:33:49.804852 8727 device_context.cc:422] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
[3, 48, 48] [3, 96, 96] <class 'numpy.ndarray'> (48, 48, 3) (96, 96, 3)
<Figure size 432x288 with 2 Axes>
定义网络结构
较rsresnet少了归一化层,以及更深的残差块
from paddle.nn import Layerfrom paddle import nnimport math
n_feat = 256kernel_size = 3# 残差块 尺寸不变class _Res_Block(nn.Layer):
def __init__(self):
super(_Res_Block, self).__init__()
self.res_conv = nn.Conv2D(n_feat, n_feat, kernel_size, padding=1)
self.relu = nn.ReLU() def forward(self, x):
y = self.relu(self.res_conv(x))
y = self.res_conv(y)
y *= 0.1
# 残差加入
y = paddle.add(y, x) return yclass EDSR(nn.Layer):
def __init__(self):
super(EDSR, self).__init__()
in_ch = 3
num_blocks = 32
self.conv1 = nn.Conv2D(in_ch, n_feat, kernel_size, padding=1) # 扩大
self.conv_up = nn.Conv2D(n_feat, n_feat * 4, kernel_size, padding=1)
self.conv_out = nn.Conv2D(n_feat, in_ch, kernel_size, padding=1)
self.body = self.make_layer(_Res_Block, num_blocks) # 上采样
self.upsample = nn.Sequential(self.conv_up, nn.PixelShuffle(2)) # 32个残差块
def make_layer(self, block, layers):
res_block = [] for _ in range(layers):
res_block.append(block()) return nn.Sequential(*res_block) def forward(self, x):
out = self.conv1(x)
out = self.body(out)
out = self.upsample(out)
out = self.conv_out(out) return out看paddle能不能用gpu
import paddleprint(paddle.device.get_device())
gpu:0
paddle.device.set_device('gpu:0')CUDAPlace(0)
训练,一般4个小时就可以达到一个不错的效果,set5中psnr可以达到27左右,当然这时间还是太少了
import osfrom math import log10from paddle.io import DataLoaderimport paddle.fluid as fluidimport warningsfrom paddle.static import InputSpecif __name__ == '__main__':
warnings.filterwarnings("ignore", category=Warning) # 过滤报警信息
train_path='train/DIV2K_train_HR'
test_path='test'
crop_size = 96 # 高分辨率图像裁剪尺寸
scaling_factor = 2 # 放大比例
# 学习参数
checkpoint = './work/edsr_paddle' # 预训练模型路径,如果不存在则为None
batch_size = 30 # 批大小
start_epoch = 0 # 轮数起始位置
epochs = 10000 # 迭代轮数
workers = 4 # 工作线程数
lr = 1e-4 # 学习率
# 先前的psnr
pre_psnr=32.35
try:
model = paddle.jit.load(checkpoint) print('加载先前模型成功') except: print('未加载原有模型训练')
model = EDSR() # 初始化优化器
scheduler = paddle.optimizer.lr.StepDecay(learning_rate=lr, step_size=1, gamma=0.99, verbose=True)
optimizer = paddle.optimizer.Adam(learning_rate=scheduler,
parameters=model.parameters())
criterion = nn.MSELoss()
train_dataset = SRDataset(train_path, crop_size, scaling_factor)
test_dataset = SRDataset(test_path, crop_size, scaling_factor)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=workers,
)
test_loader = DataLoader(test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=workers,
) for epoch in range(start_epoch, epochs+1):
model.train() # 训练模式:允许使用批样本归一化
train_loss=0
n_iter_train = len(train_loader)
train_psnr=0
# 按批处理
for i, (lr_imgs, hr_imgs) in enumerate(train_loader):
lr_imgs = lr_imgs
hr_imgs = hr_imgs
sr_imgs = model(lr_imgs)
loss = criterion(sr_imgs, hr_imgs)
optimizer.clear_grad()
loss.backward()
optimizer.step()
train_loss+=loss.item()
psnr = 10 * log10(1 / loss.item())
train_psnr+=psnr
epoch_loss_train=train_loss / n_iter_train
train_psnr=train_psnr/n_iter_train print(f"Epoch {epoch}. Training loss: {epoch_loss_train} Train psnr {train_psnr}DB")
model.eval() # 测试模式
test_loss=0
all_psnr = 0
n_iter_test = len(test_loader) with paddle.no_grad(): for i, (lr_imgs, hr_imgs) in enumerate(test_loader):
lr_imgs = lr_imgs
hr_imgs = hr_imgs
sr_imgs = model(lr_imgs)
loss = criterion(sr_imgs, hr_imgs)
psnr = 10 * log10(1 / loss.item())
all_psnr+=psnr
test_loss+=loss.item()
epoch_loss_test=test_loss/n_iter_test
epoch_psnr=all_psnr / n_iter_test print(f"Epoch {epoch}. Testing loss: {epoch_loss_test} Test psnr{epoch_psnr} dB") if epoch_psnr>pre_psnr:
paddle.jit.save(model, checkpoint,input_spec=[InputSpec(shape=[1,3,48,48], dtype='float32')])
pre_psnr=epoch_psnr print('模型更新成功')
scheduler.step()加载先前模型成功 Epoch 0: StepDecay set learning rate to 0.0001.
测试,需要自己上传一张低分辨率的图片
import paddlefrom paddle.vision import transformsimport PIL.Image as Imageimport numpy as np
imgO=Image.open('img_003_SRF_2_LR.png',mode="r") #选择自己图片的路径img=transforms.ToTensor()(imgO).unsqueeze(0)#导入模型net=paddle.jit.load("./work/edsr_paddle")
source = net(img)[0, :, :, :]
source = source.cpu().detach().numpy() # 转为numpysource = source.transpose((1, 2, 0)) # 切换形状source = np.clip(source, 0, 1) # 修正图片img = Image.fromarray(np.uint8(source * 255))
plt.figure(figsize=(9,9))
plt.subplot(1, 2, 1)
plt.imshow(imgO)
plt.title('input')
plt.subplot(1, 2, 2)
plt.imshow(img)
plt.title('output')
plt.show()
img.save('./sr.png')EDSR_X2效果
双线性插值放大效果

EDSR_X2放大效果

双线性插值放大效果

EDSR_X2放大效果

<br/>




























