基于paddle搭建cnn卷积神经网络,实现珍稀动物检测。在原有卷积神经网络上,我们采用两种方式:多尺度特征融合和密集网络连接,进行优化网络模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、项目简介
本项目用包含七种珍稀动物的数据集来实现图像分类效果。




1.1卷积神经网络的概念
上世纪60年代,Hubel等人通过对猫视觉皮层细胞的研究,提出了感受野这个概念,到80年代,Fukushima在感受野概念的基础之上提出了神经认知机的概念,可以看作是卷积神经网络的第一个实现网络,神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
卷积神经网络是多层感知机(MLP)的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来,视觉皮层的细胞存在一个复杂的构造,这些细胞对视觉输入空间的子区域非常敏感,称之为感受野。
CNN由纽约大学的Yann Lecun于1998年提出,其本质是一个多层感知机,成功的原因在于其所采用的局部连接和权值共享的方式:
一方面减少了权值的数量使得网络易于优化
另一方面降低了模型的复杂度,也就是减小了过拟合的风险
该优点在网络的输入是图像时表现的更为明显,使得图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建的过程,在二维图像的处理过程中有很大的优势,如网络能够自行抽取图像的特征包括颜色、纹理、形状及图像的拓扑结构,在处理二维图像的问题上,特别是识别位移、缩放及其他形式扭曲不变性的应用上具有良好的鲁棒性和运算效率等。
1.2实验结果展示

二、数据预处理
# 解压原始数据集!unzip /home/aistudio/data/data300189/animals.zip -d data/
import osimport zipfileimport randomimport jsonimport paddleimport sysimport numpy as npfrom PIL import Imageimport paddleimport matplotlib.pyplot as plt
'''
参数配置
'''train_parameters = { "input_size": [3, 64, 64], #输入图片的shape
"class_dim": -1, #分类数
"src_path":"data/data300189/animals.zip", #原始数据集路径
"target_path":"/home/aistudio/data/animals/animals/", #要解压的路径
"train_list_path": "/home/aistudio/data/train.txt", #train.txt路径
"eval_list_path": "/home/aistudio/data/eval.txt", #eval.txt路径
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"label_dict":{}, #标签字典
"num_epochs": 20, #训练轮数
"train_batch_size": 64, #训练时每个批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.01 #超参数学习率
}
}def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = [] #获取所有类别保存的文件夹名称
data_list_path=target_path
class_dirs = os.listdir(data_list_path)
#总的图像数量
all_class_images = 0
#存放类别标签
class_label=0
#存放类别数目
class_dim = 0
#存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[] #读取每个类别
for class_dir in class_dirs: if class_dir != ".DS_Store": #".DS_Store" 是一个特定的文件名,通常在 macOS 系统中出现。这是 macOS 系统用于存储文件夹的自定义属性的隐藏文件。
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = data_list_path + class_dir # 获取所有图片
img_paths = os.listdir(path) for img_path in img_paths: # 遍历文件夹下的每个图片
name_path = path + '/' + img_path # 每张图片的路径
if class_sum % 8 == 0: # 每8张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n") else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
#乱序
random.shuffle(eval_list) with open(eval_list_path, 'a') as f: for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list) with open(train_list_path, 'a') as f2: for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': ')) print(type(jsons)) print(jsons) with open(train_parameters['readme_path'],'w') as f:
f.write(jsons) print ('生成数据列表完成!')'''
参数初始化
'''src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']# '''# 解压原始数据到指定路径# '''# unzip_data(src_path,target_path)# '''# 划分训练集与验证集,乱序,生成数据列表# '''#每次生成数据列表前,首先清空train.txt和eval.txtwith open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表 get_data_list(target_path,train_list_path,eval_list_path)<class 'str'>
{
"all_class_images": 889,
"all_class_name": "/home/aistudio/data/animals/animals/",
"class_detail": [
{
"class_eval_images": 12,
"class_label": 0,
"class_name": "Wild_Camel",
"class_trainer_images": 81
},
{
"class_eval_images": 20,
"class_label": 1,
"class_name": "Sika_Deer",
"class_trainer_images": 140
},
{
"class_eval_images": 13,
"class_label": 2,
"class_name": "panda",
"class_trainer_images": 85
},
{
"class_eval_images": 20,
"class_label": 3,
"class_name": "tiger",
"class_trainer_images": 140
},
{
"class_eval_images": 9,
"class_label": 4,
"class_name": "Taiwan_Macaque",
"class_trainer_images": 63
},
{
"class_eval_images": 25,
"class_label": 5,
"class_name": "Chinese_Merganser",
"class_trainer_images": 175
},
{
"class_eval_images": 14,
"class_label": 6,
"class_name": "Yellow-bellied_Tragopan",
"class_trainer_images": 92
}
]
}
生成数据列表完成!import paddleimport paddle.vision.transforms as Timport numpy as npfrom PIL import Imageclass AnimalsDataset(paddle.io.Dataset):
"""
7种animal数据集类的定义
"""
def __init__(self, mode='train'):
"""
初始化函数
"""
self.data = [] with open('data/{}.txt'.format(mode)) as f: for line in f.readlines():
info = line.strip().split('\t') if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])
self.transforms = T.Compose([
T.Resize((64, 64)), # 图片缩放
T.ToTensor(), # 数据的格式转换和标准化、 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __getitem__(self, index):
"""
根据索引获取单个样本
"""
image_file, label = self.data[index]
image = Image.open(image_file) ##读取样本数据
if image.mode != 'RGB':
image = image.convert('RGB')
image = self.transforms(image) ##数据格式转化
return image, np.array(label, dtype='int64') ##封装数据和标签到元组
def __len__(self):
"""
获取样本总数
"""
return len(self.data)''' 构造数据提供器 '''train_dataset = AnimalsDataset(mode='train') eval_dataset = AnimalsDataset(mode='eval')
print(len(train_dataset))print(type(train_dataset))
776 <class '__main__.AnimalsDataset'>
train_loader = paddle.io.DataLoader(train_dataset, batch_size=100, shuffle=True,
num_workers=1,
drop_last=False)print('step num:',len(train_loader))step num: 8
print(len(eval_dataset))
eval_loader=paddle.io.DataLoader(eval_dataset, batch_size=100, shuffle=True,
num_workers=1,
drop_last=False)print('step num:',len(eval_loader))113 step num: 2
三、网络模型设计
3.1CNN网络模型
#定义卷积网络import paddle.nn as nnimport paddle.nn.functional as F# 导入需要的包import paddleimport numpy as npfrom paddle.nn import Conv2D, MaxPool2D, Linear,BatchNorm2D,Dropout2D,Dropout## 组网# 定义 CNN 网络结构class MyCNN(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyCNN, self).__init__() # 创建卷积和池化层
# 创建第1个卷积层
self.conv1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)
self.BN1=BatchNorm2D(num_features=6)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2) # 尺寸的逻辑:池化层未改变通道数;当前通道数为6
# 创建第2个卷积层
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.BN2=BatchNorm2D(num_features=16)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2) # 创建第3个卷积层
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
self.BN3=BatchNorm2D(num_features=120)
self.DP1=Dropout2D(p=0.2) # 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
# 输入size是[28,28],经过三次卷积和两次池化之后,C*H*W等于120
self.fc1 = Linear(in_features=120*10*10, out_features=64)
self.DP2=Dropout(p=0.2) # 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc2 = Linear(in_features=64, out_features=num_classes) # 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
x=self.BN1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x=self.BN2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x=self.BN3(x)
x=F.relu(x)
x=self.DP1(x) # 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.relu(x)
x=self.DP2(x)
x = self.fc2(x) return x3.2CNN实现多尺度特征融合
可以在不同的卷积层后提取特征,然后在全连接层之前将它们合并,可以通过连接(concatenation)或求和(summation)的方式实现:
新增卷积分支:添加了一个新的卷积分支 conv4,它使用了不同的卷积层和参数来提取多尺度特征。
特征融合:在 forward 方法中,通过 paddle.concat 将两个分支的特征融合在一起。
全连接层输入调整:更新了全连接层的输入特征数,以反映多尺度特征的融合。
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm2D, Dropout2D, Dropout# 定义 CNN 网络结构class MyCNNWithMultiScaleFusion(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyCNNWithMultiScaleFusion, self).__init__()
# 创建卷积和池化层
self.conv1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)
self.BN1 = BatchNorm2D(num_features=6)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.BN2 = BatchNorm2D(num_features=16)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
self.BN3 = BatchNorm2D(num_features=120)
self.DP1 = Dropout2D(p=0.2) # 定义第二个卷积分支
self.conv4 = Conv2D(in_channels=3, out_channels=16, kernel_size=3)
self.BN4 = BatchNorm2D(num_features=16)
self.max_pool4 = MaxPool2D(kernel_size=2, stride=2)
self.conv5 = Conv2D(in_channels=16, out_channels=32, kernel_size=3)
self.BN5 = BatchNorm2D(num_features=32)
self.max_pool5 = MaxPool2D(kernel_size=2, stride=2) # 全连接层
self.fc1 = Linear(in_features=(120*10*10 + 32*14*14), out_features=64) # 考虑到多尺度特征
self.DP2 = Dropout(p=0.2)
self.fc2 = Linear(in_features=64, out_features=num_classes) def forward(self, x):
# 第一个卷积分支
x1 = self.conv1(x)
x1 = self.BN1(x1)
x1 = F.relu(x1)
x1 = self.max_pool1(x1)
x1 = self.conv2(x1)
x1 = self.BN2(x1)
x1 = F.relu(x1)
x1 = self.max_pool2(x1)
x1 = self.conv3(x1)
x1 = self.BN3(x1)
x1 = F.relu(x1)
x1 = self.DP1(x1) # 第二个卷积分支
x2 = self.conv4(x)
x2 = self.BN4(x2)
x2 = F.relu(x2)
x2 = self.max_pool4(x2)
x2 = self.conv5(x2)
x2 = self.BN5(x2)
x2 = F.relu(x2)
x2 = self.max_pool5(x2) # 特征融合
x1 = paddle.reshape(x1, [x1.shape[0], -1])
x2 = paddle.reshape(x2, [x2.shape[0], -1])
x = paddle.concat([x1, x2], axis=1) # 全连接层
x = self.fc1(x)
x = F.relu(x)
x = self.DP2(x)
x = self.fc2(x) return x3.3CNN融入密集网络连接
通过动态定义全连接层的输入特征数,增加了模型的灵活性。
使用了批归一化和Dropout来提高模型的泛化能力和防止过拟合。
通过特征重用机制,增强了网络中特征的流动性和梯度流动。
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm2D, Dropout2D, Dropoutclass MyDenseCNN(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyDenseCNN, self).__init__()
# 创建卷积层和池化层
self.conv1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)
self.BN1 = BatchNorm2D(num_features=6)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=6 + 3, out_channels=16, kernel_size=5)
self.BN2 = BatchNorm2D(num_features=16)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=16 + 6 + 3, out_channels=120, kernel_size=4)
self.BN3 = BatchNorm2D(num_features=120)
self.DP1 = Dropout2D(p=0.2) # 初始化全连接层,待定输入特征数
self.fc1 = None # 先设为None,后面会动态定义
self.DP2 = Dropout(p=0.2)
self.fc2 = Linear(in_features=64, out_features=num_classes) def forward(self, x):
x1 = F.relu(self.BN1(self.conv1(x)))
x1_pool = self.max_pool1(x1) # 调整x2输入大小
x2_input = paddle.concat([x, F.interpolate(x1_pool, size=x.shape[2:])], axis=1)
x2 = F.relu(self.BN2(self.conv2(x2_input)))
x2_pool = self.max_pool2(x2) # 调整x3输入大小
x3_input = paddle.concat([x, F.interpolate(x1_pool, size=x.shape[2:]), F.interpolate(x2_pool, size=x.shape[2:])], axis=1)
x3 = F.relu(self.BN3(self.conv3(x3_input)))
x3_dropped = self.DP1(x3) # 打印x3_dropped的形状
# print(f"x3_dropped shape: {x3_dropped.shape}")
# 动态计算全连接层输入特征数
x_flat = paddle.reshape(x3_dropped, [x3_dropped.shape[0], -1])
in_features_fc1 = x_flat.shape[1] # 动态获取特征数
if self.fc1 is None: # 如果fc1未初始化
self.fc1 = Linear(in_features=in_features_fc1, out_features=64)
x_fc1 = F.relu(self.fc1(x_flat))
x_fc1_dropped = self.DP2(x_fc1)
x_out = self.fc2(x_fc1_dropped) return x_out3.4设置设备,查看模型信息
from paddle.vision.models import resnet50# 设置设备device = paddle.set_device('gpu:0' if paddle.is_compiled_with_cuda() and paddle.cuda.is_available() else 'cpu')import paddlefrom paddle.vision.models import resnet50,vgg11# myCNN = resnet50(pretrained=True,num_classes=7)# myCNN = vgg11(pretrained=False,num_classes=7)# myCNN = MyCNN(num_classes=7)# myCNN = MyCNNWithAttention(num_classes=7)# myCNN = MyCNNWithMultiScaleFusion(num_classes=7)myCNN = MyDenseCNN(num_classes=7) parameters_info = paddle.summary(myCNN, (1, 3, 64, 64))print(parameters_info)
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-10 [[1, 3, 64, 64]] [1, 6, 60, 60] 456
BatchNorm2D-10 [[1, 6, 60, 60]] [1, 6, 60, 60] 24
MaxPool2D-7 [[1, 6, 60, 60]] [1, 6, 30, 30] 0
Conv2D-11 [[1, 9, 64, 64]] [1, 16, 60, 60] 3,616
BatchNorm2D-11 [[1, 16, 60, 60]] [1, 16, 60, 60] 64
MaxPool2D-8 [[1, 16, 60, 60]] [1, 16, 30, 30] 0
Conv2D-12 [[1, 25, 64, 64]] [1, 120, 61, 61] 48,120
BatchNorm2D-12 [[1, 120, 61, 61]] [1, 120, 61, 61] 480
Dropout2D-4 [[1, 120, 61, 61]] [1, 120, 61, 61] 0
Dropout-4 [[1, 64]] [1, 64] 0
Linear-7 [[1, 64]] [1, 7] 455
===========================================================================
Total params: 53,215
Trainable params: 52,931
Non-trainable params: 284
---------------------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 11.58
Params size (MB): 0.20
Estimated Total Size (MB): 11.83
---------------------------------------------------------------------------
{'total_params': 53215, 'trainable_params': 52931}四、模型训练
# 训练配置,并启动训练过程from paddle.vision.models import resnet50,vgg16# 设置设备device = paddle.set_device('gpu:0' if paddle.is_compiled_with_cuda() else 'cpu')def train(model):
model.train() #调用加载数据的函数
#train_loader = load_data('train')
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 50
acc_epoch=[]
loss_epoch=[] for epoch_id in range(EPOCH_NUM):
acc_set = list()
loss_set=[] for batch_id, data in enumerate(train_loader()): #准备数据,变得更加简洁
#print(batch_id)
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
labels = labels.unsqueeze(1)
#print(images.shape)
#print(labels.shape)
#前向计算的过程
predicts = model(images) #print(predicts.shape)
#计算损失,取一个批次样本损失的平均值
loss = F.cross_entropy(predicts,labels)
avg_loss = paddle.mean(loss)
loss_set.append(avg_loss.numpy())
acc=paddle.metric.accuracy(predicts,labels)
acc_mean = paddle.mean(acc)
acc_set.append(acc.numpy())
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 10 == 0: print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy())) #后向传播,更新参数的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
print("acc is: {}".format(np.array(acc_set).mean()))
acc_epoch.append(np.array(acc_set).mean())
loss_epoch.append(np.array(loss_set).mean()) #print(predicts.shape)
#print(labels.shape)
#print(type(predits))
#print(avg_loss)
# 保存模型
paddle.save(model.state_dict(), './mycnn.pdparams')# 创建模型 # model = resnet50(pretrained=True,num_classes=7)# model = MyCNN(num_classes=7)# model = MyCNNWithMultiScaleFusion(num_classes=7)# model = MyCNNWithAttention(num_classes=7)# model = vgg16(pretrained=True,num_classes=7)model = MyDenseCNN(num_classes=7)# 启动训练过程train(model)print('测试数据集样本量:{}'.format(len(eval_dataset)))测试数据集样本量:113
五、模型评估
def evaluation(model):
print('start evaluation ......') # 定义预测过程
params_file_path = 'mycnn.pdparams'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
model.eval()
acc_set = []
avg_loss_set = [] for batch_id, data in enumerate(eval_loader()):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
labels = labels.unsqueeze(1)
predicts= model(images)
loss = F.cross_entropy(input=predicts, label=labels)
avg_loss = paddle.mean(loss)
acc = paddle.metric.accuracy(predicts,labels)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
#计算多个batch的平均损失和准确率
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean() print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))# model = vgg16(pretrained=True,num_classes=7)# model = MyCNNWithMultiScaleFusion(num_classes=7)# model = MyCNNWithAttention(num_classes=7)model = MyDenseCNN(num_classes=7)# model = resnet50(pretrained=True,num_classes=7)# model = MyCNN(num_classes=7)evaluation(model)start evaluation ...... loss=0.7660975754261017, acc=0.7715384662151337
六、样本映射
# 样本映射LABEL_MAP = ['Sika_Deer','panda','Taiwan_Macaque','Chinese_Merganser','tiger','Wild_Camel','Yellow-bellied_Tragopan']for batch_id, data in enumerate(eval_loader()):
images, labels_test = data
images = paddle.to_tensor(images)
predicts= model(images) breakflag=0for idx in range(len(labels_test)):
GT=labels_test[idx]
PR=paddle.argmax(predicts,axis=1)[idx].numpy()
GT=int(GT)
PR=int(PR) print("真实标签:",GT) print("预测值:",PR) print("真实标签:{}".format(LABEL_MAP[GT])) print("预测值:{}".format(LABEL_MAP[PR])) if GT==PR:
flag+=1predict_acc=flag/len(labels_test)print('*****************************************')print(f'predict_acc = {predict_acc*100}%')真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 5 预测值: 4 真实标签:Wild_Camel 预测值:tiger 真实标签: 2 预测值: 2 真实标签:Taiwan_Macaque 预测值:Taiwan_Macaque 真实标签: 0 预测值: 5 真实标签:Sika_Deer 预测值:Wild_Camel 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 2 预测值: 2 真实标签:Taiwan_Macaque 预测值:Taiwan_Macaque 真实标签: 2 预测值: 0 真实标签:Taiwan_Macaque 预测值:Sika_Deer 真实标签: 5 预测值: 0 真实标签:Wild_Camel 预测值:Sika_Deer 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 2 预测值: 3 真实标签:Taiwan_Macaque 预测值:Chinese_Merganser 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 0 预测值: 4 真实标签:Sika_Deer 预测值:tiger 真实标签: 6 预测值: 5 真实标签:Yellow-bellied_Tragopan 预测值:Wild_Camel 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 3 预测值: 3 真实标签:Chinese_Merganser 预测值:Chinese_Merganser 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 5 预测值: 3 真实标签:Wild_Camel 预测值:Chinese_Merganser 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 2 预测值: 2 真实标签:Taiwan_Macaque 预测值:Taiwan_Macaque 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 2 预测值: 2 真实标签:Taiwan_Macaque 预测值:Taiwan_Macaque 真实标签: 0 预测值: 2 真实标签:Sika_Deer 预测值:Taiwan_Macaque 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 1 预测值: 0 真实标签:panda 预测值:Sika_Deer 真实标签: 4 预测值: 5 真实标签:tiger 预测值:Wild_Camel 真实标签: 3 预测值: 2 真实标签:Chinese_Merganser 预测值:Taiwan_Macaque 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 4 预测值: 5 真实标签:tiger 预测值:Wild_Camel 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 6 预测值: 0 真实标签:Yellow-bellied_Tragopan 预测值:Sika_Deer 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 5 预测值: 3 真实标签:Wild_Camel 预测值:Chinese_Merganser 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 6 预测值: 5 真实标签:Yellow-bellied_Tragopan 预测值:Wild_Camel 真实标签: 4 预测值: 2 真实标签:tiger 预测值:Taiwan_Macaque 真实标签: 3 预测值: 0 真实标签:Chinese_Merganser 预测值:Sika_Deer 真实标签: 4 预测值: 5 真实标签:tiger 预测值:Wild_Camel 真实标签: 2 预测值: 2 真实标签:Taiwan_Macaque 预测值:Taiwan_Macaque 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 3 预测值: 3 真实标签:Chinese_Merganser 预测值:Chinese_Merganser 真实标签: 2 预测值: 0 真实标签:Taiwan_Macaque 预测值:Sika_Deer 真实标签: 2 预测值: 0 真实标签:Taiwan_Macaque 预测值:Sika_Deer 真实标签: 0 预测值: 3 真实标签:Sika_Deer 预测值:Chinese_Merganser 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 3 预测值: 3 真实标签:Chinese_Merganser 预测值:Chinese_Merganser 真实标签: 4 预测值: 0 真实标签:tiger 预测值:Sika_Deer 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 3 预测值: 2 真实标签:Chinese_Merganser 预测值:Taiwan_Macaque 真实标签: 4 预测值: 1 真实标签:tiger 预测值:panda 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 5 预测值: 2 真实标签:Wild_Camel 预测值:Taiwan_Macaque 真实标签: 4 预测值: 1 真实标签:tiger 预测值:panda 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 2 预测值: 2 真实标签:Taiwan_Macaque 预测值:Taiwan_Macaque 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 1 预测值: 4 真实标签:panda 预测值:tiger 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 2 预测值: 3 真实标签:Taiwan_Macaque 预测值:Chinese_Merganser 真实标签: 3 预测值: 1 真实标签:Chinese_Merganser 预测值:panda 真实标签: 2 预测值: 4 真实标签:Taiwan_Macaque 预测值:tiger 真实标签: 0 预测值: 4 真实标签:Sika_Deer 预测值:tiger 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 5 预测值: 2 真实标签:Wild_Camel 预测值:Taiwan_Macaque 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 4 预测值: 3 真实标签:tiger 预测值:Chinese_Merganser 真实标签: 5 预测值: 5 真实标签:Wild_Camel 预测值:Wild_Camel 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 4 预测值: 0 真实标签:tiger 预测值:Sika_Deer 真实标签: 1 预测值: 1 真实标签:panda 预测值:panda 真实标签: 6 预测值: 6 真实标签:Yellow-bellied_Tragopan 预测值:Yellow-bellied_Tragopan 真实标签: 6 预测值: 5 真实标签:Yellow-bellied_Tragopan 预测值:Wild_Camel 真实标签: 4 预测值: 4 真实标签:tiger 预测值:tiger 真实标签: 0 预测值: 0 真实标签:Sika_Deer 预测值:Sika_Deer 真实标签: 2 预测值: 0 真实标签:Taiwan_Macaque 预测值:Sika_Deer ***************************************** predict_acc = 63.0%
七、模型推理
# 模型推理import matplotlib.pyplot as pltfrom PIL import Imageimport numpy as np
images_dir=['work/Chinese_Merganser.jpg','work/panda.jpg','work/Sika_Deer.jpg','work/Taiwan_Macaque.jpg','work/tiger.jpg','work/Wild_Came.jpg','work/Yellow-bellied_Tragopan.jpg']for i in images_dir:
img = Image.open(i)
plt.figure("Image") # 图像窗口名称
plt.imshow(img) if img.mode != 'RGB':
img = img.convert('RGB') # 转换成模型可读入的shape
transforms = T.Compose([
T.Resize((64, 64)), # 图片缩放
T.ToTensor(), # 数据的格式转换和标准化、 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
test_img=transforms(img)
print(test_img.shape)
test_img=test_img.unsqueeze(0) print(test_img.shape)
result=model(test_img)
PR=paddle.argmax(result).numpy() print(PR) print("预测值:{}".format(LABEL_MAP[PR]))
plt.show()[3, 64, 64] [1, 3, 64, 64] 3 预测值:Chinese_Merganser
<Figure size 640x480 with 1 Axes>
[3, 64, 64] [1, 3, 64, 64] 1 预测值:panda
<Figure size 640x480 with 1 Axes>
[3, 64, 64] [1, 3, 64, 64] 0 预测值:Sika_Deer
<Figure size 640x480 with 1 Axes>
[3, 64, 64] [1, 3, 64, 64] 2 预测值:Taiwan_Macaque
<Figure size 640x480 with 1 Axes>
[3, 64, 64] [1, 3, 64, 64] 4 预测值:tiger
<Figure size 640x480 with 1 Axes>
[3, 64, 64] [1, 3, 64, 64] 3 预测值:Chinese_Merganser
<Figure size 640x480 with 1 Axes>
[3, 64, 64] [1, 3, 64, 64] 6 预测值:Yellow-bellied_Tragopan
<Figure size 640x480 with 1 Axes>
八、项目总结
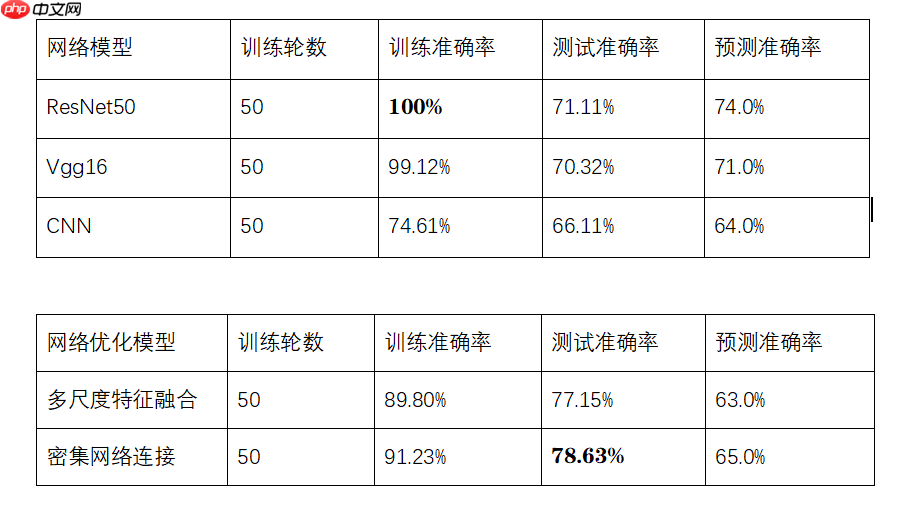
由以上实验结果分析,本次图像分类项目采用ResNet50网络模型效果最好,在训练集上的准确率达到100%,预测准确率达到74%,准确率相较于其他网络模型较高,其他优化后的模型,如CNN实现多尺度特征融合以及CNN融入密集网络连接,在测试集上的准确率较高。