
2025年12月8日,全球领先的半导体代工企业台积电(tsmc)在欧洲oip(open innovation platform)生态系统论坛上正式披露其面向2028年量产的a14工艺关键性能指标:以2018年推出的n7制程为基准,历经十年五代技术演进,a14将在能效比方面实现高达4.2倍的提升。这一里程碑式进展不仅凸显台积电在先进逻辑制程领域的持续领跑地位,更将深度赋能人工智能、移动计算与高性能计算(hpc)等前沿领域,推动行业重新定义功耗与性能的协同边界。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

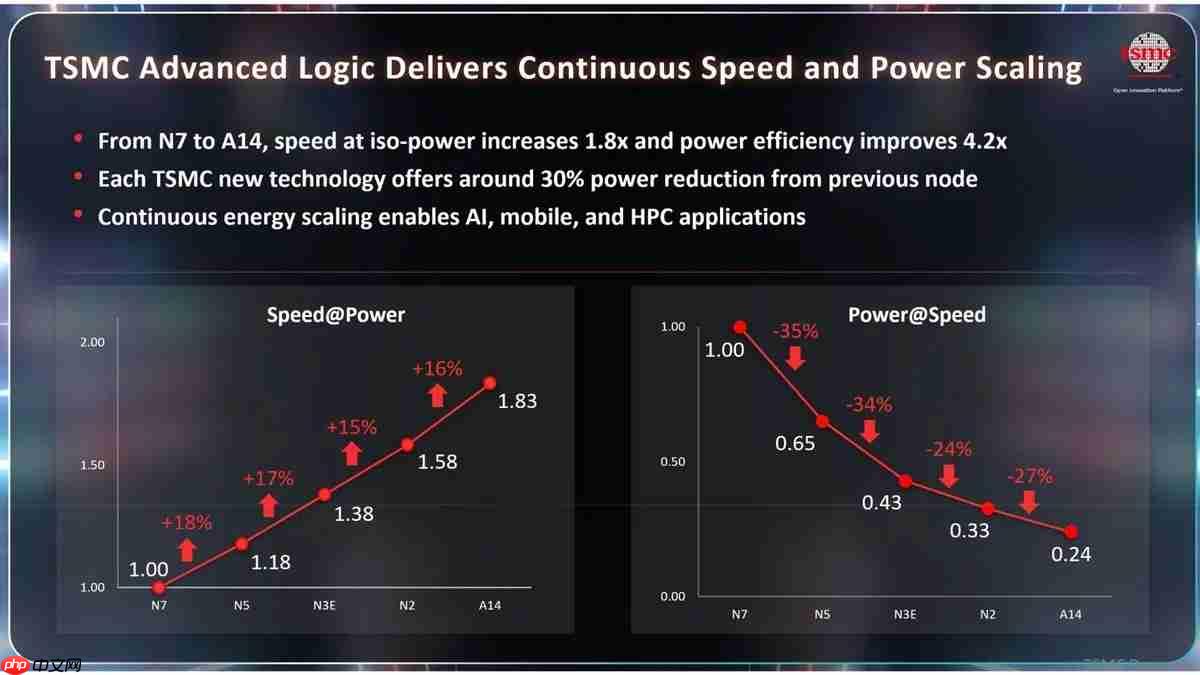
十年跃迁:N7至A14的能效演进图谱
半导体工艺的迭代始终聚焦于“性能(Performance)、功耗(Power)、面积(Area)”三大核心维度,而能效比(Performance per Watt)已成为衡量技术代际跨越最具说服力的综合标尺。台积电此次公布的路线图清晰勾勒出从N7到A14的演进路径——涵盖N5、N3E、N2及最终A14共五代关键节点,每一代均在功耗控制与性能增益之间达成更优平衡。

据台积电官方数据,各代节点呈现高度一致的优化节奏:单代工艺平均可降低约30%的功耗,同时带来15%–18%的性能增益。具体表现为:N7至N5,同功耗下性能提升18%;N5至N3E,再增17%;N3E至N2,提升15%;而A14相较N2,在相同功耗与设计复杂度下性能提升16%,在相同时钟频率与负载条件下功耗下降27%。
经逐代叠加效应测算,A14相较N7实现了双重突破:在恒定功耗前提下,运算性能达N7的1.83倍;在维持同等性能水平时,所需功耗仅为N7的约23.8%(即下降76.2%)。二者结合,最终达成整体能效比提升至N7的4.2倍。这意味着未来基于A14打造的终端设备,无论是在智能手机的日常高负载AI任务,还是在数据中心的密集型推理场景中,都将获得续航延长与算力跃升的双重红利。
底层革新:第二代GAA晶体管与NanoFlex Pro架构协同发力
A14工艺能效跃升的核心驱动力,源于器件结构与设计灵活性的双重突破。作为台积电新一代旗舰制程,A14将首次量产应用第二代全环绕栅极(GAA)晶体管技术。相较于初代GAA,新版本在栅极围栅均匀性、沟道静电控制能力及亚阈值摆幅等方面均有显著增强,有效抑制短沟道效应与漏电,为高密度集成与低电压运行奠定物理基础。

尤为关键的是,A14同步引入全新升级的NanoFlex Pro标准单元架构。该技术由台积电在N2时代已验证的NanoFlex平台演进而来,通过提供更高自由度的晶体管级可配置能力,使芯片设计师能够对阈值电压(Vt)、驱动强度、电源域划分等关键参数实施精细化调控。相比传统固定单元库,NanoFlex Pro支持按功能模块“按需定制”晶体管特性——例如为AI加速器配置低延迟高驱动单元,为基带模块匹配超低功耗单元,从而在系统层面实现PPA指标的全局最优解。
台积电技术团队指出,这种“场景化微调”能力,正是A14能在多元应用中保持能效领先的关键所在。它打破了以往“一套规格适配全部”的设计惯性,真正实现从“通用制造”向“场景驱动制造”的范式转变。

需说明的是,当前规划中的A14初版暂未集成Super Power Rail(SPR)背面供电架构。台积电明确表示,SPR技术将延至2029年发布的A14增强版中落地,该版本将重点面向高端客户端处理器与云数据中心CPU/GPU,通过分离正面信号布线与背面供电网络,进一步压缩IR压降与供电噪声,释放更高频率与更大规模晶体管阵列的潜力。
AI赋能设计:智能EDA工具链贡献额外7%功耗优化
除工艺本身升级外,台积电正加速推进“制造—设计”闭环的智能化重构。在本次论坛中,公司联合Cadence与Synopsys推出新一代AI原生电子设计自动化(EDA)工具链,包括Cadence Cerebrus AI Studio与Synopsys DSO.ai强化学习平台。

这些工具不再局限于传统规则驱动的流程优化,而是借助大规模训练与实时反馈机制,在数百万级设计变量空间中自主探索帕累托最优解。实测数据显示:通过AI优化自动布局布线(APR)流程,可减少5%的动态功耗;结合金属层堆叠与互连拓扑的AI重布线策略,可再降低2%的静态与开关功耗。两项叠加,为芯片带来总计约7%的额外功耗节省(实际收益依工作电压、温度及设计约束浮动)。
在3nm及以下工艺节点,晶体管数量与互连复杂度呈非线性增长,人工经验已难以覆盖全部优化组合。AI驱动的设计流程,正成为挖掘工艺潜能不可或缺的“第二引擎”,并与先进制程形成“硬件+算法”的双轮驱动新格局。
产业共振:重塑AI芯片与绿色数据中心的技术底座
A14工艺的发布时机,精准契合全球AI基础设施升级与碳中和战略深化的关键窗口。当前,大模型训练成本居高不下,数据中心年耗电量已逼近部分国家总用电量,高能效芯片成为破局刚需。A14所实现的4.2倍能效跃升,正为此提供可规模落地的技术支点。

在移动终端侧,搭载A14工艺的SoC有望在运行多模态AI视觉处理、实时端侧大模型推理等任务时,将功耗压降至N7方案的约1/4,显著缓解发热与续航焦虑。例如,下一代旗舰手机在启用AI超分+HDR实时渲染+语音语义联合建模时,整机功耗预计可下降近70%,真正实现“强AI不减续航”。
在云端与边缘侧,A14将助力服务器芯片在单位瓦特内交付更高TFLOPS算力。初步建模表明,若主流AI加速卡全面切换至A14平台,单机柜算力密度可提升35%以上,同时整机房PUE(电能使用效率)有望降低0.15–0.2,对应年节电量可达数亿千瓦时级别。

从竞争格局看,台积电凭借A14在能效、生态成熟度与客户协同深度上的综合优势,进一步拉开了与三星等同业者的代际差距。尽管后者亦在推进GAA量产,但在标准单元库丰富度、AI设计工具链整合度及晶圆厂-设计公司联合优化机制等方面仍处追赶阶段。A14的提前卡位,将持续强化台积电对苹果、英伟达、AMD、联发科等头部客户的吸引力,并加速先进制程产能向高附加值产品倾斜。
结语:能效跃迁不止于数字,更是系统创新的集中体现
台积电A14工艺的亮相,远不止是一项制程参数的更新,而是晶体管物理结构、电路设计范式、EDA工具智能水平及制造协同体系等多维能力深度融合的成果。十年间4.2倍的能效飞跃,印证了摩尔定律并未终结,而是正以“More than Moore”的形态持续进化——在尺寸微缩之外,更强调异构集成、智能设计与场景适配的系统级创新。半导体产业,正稳步迈向更高能效、更强智能、更可持续的新纪元。
以上就是史诗级突破!台积电A14工艺对比N7,能效暴涨420%!的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 886
886



















