本文是2021 CCF BDCI花样滑冰选手骨骼点动作识别大赛B榜第三名方案。基于飞桨,采用ICCV2021论文CTRGCN和Focal loss、PaddleVideo套件,构建节点流、骨骼流等四流框架,结合模型集成,在FSD-30数据集上取得良好成绩,还介绍了环境配置、训练与预测流程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本项目是基于飞桨实现花样滑冰选手骨骼点动作识别大赛:花样滑冰选手的细粒度骨骼点动作识别大赛B榜第三名方案。本项目基于ICCV2021论文CTRGCN和Focal loss、PaddleVideo套件构建节点流、骨骼流、节点运动流、骨骼运动流四流框架进行动作识别,取得了B榜第三,A榜15的成绩。
 [](http://)
[](http://)
人体运动分析是近几年许多领域研究的热点问题。在学科的交叉研究上,人体运动分析涉及到计算机科学、运动人体科学、环境行为学和材料科学等。随着研究的深入以及计算机视觉、5G通信的飞速发展,人体运动分析技术已应用于自动驾驶、影视创作、安防异常事件监测和体育竞技分析、康复等实际场景人体运动分析已成为人工智能领域研究的前沿课题。目前的研究数据普遍缺少细粒度语义信息,导致现存的分割或识别任务缺少时空细粒度动作语义模型。此类研究在竞技体育、运动康复、日常健身等方面有非常重大的意义。相比于图片的细粒度研究,时空细粒度语义的人体动作具有动作的类内方差大、类间方差小这一特点,这将导致由细粒度语义产生的一系列问题,利用粗粒度语义的识别模型进行学习难得获得理想的结果。
基于实际需求以及图深度学习模型的发展,本比赛旨在构建基于骨骼点的细粒度人体动作识别方法。通过本赛题建立精度高、细粒度意义明确的动作识别模型,希望大家探索时空细粒度模型的新方法。
数据集Figure Skating Dataset (FSD-30)旨在通过花样滑冰研究人体的运动。在花样滑冰运动中,人体姿态和运动轨迹相较于其他运动呈现复杂性强、类别多的特点,有助于细粒度图深度学习新模型、新任务的研究。
在本次比赛最新发布的数据集中,所有视频素材均从2017-2020 年的花样滑冰锦标赛中采集得到。源视频素材中视频的帧率被统一标准化至每秒30 帧,图像大小被统一标准化至1080 * 720 ,以保证数据集的相对一致性。之后通过2D姿态估计算法Open Pose,对视频进行逐帧骨骼点提取,最后以.npy格式保存数据集。
训练数据集与测试数据集的目录结构如下所示:
train_data.npy train_label.npy test_A_data.npy test_B_data.npy # B榜测试集后续公开
本次比赛最新发布的数据集共包含30个类别,训练集共2922个样本,A榜测试集共628个样本,B榜测试集共634个样本;
train_label.npy文件通过np.load()读取后,会得到一个一维张量,张量中每一个元素为一个值在0-29之间的整形变量,代表动作的标签;
data.npy文件通过np.load()读取后,会得到一个形状为N×C×T×V×M的五维张量,每个维度的具体含义如下:
| 维度符号表示 | 维度值大小 | 维度含义 | 补充说明 |
|---|---|---|---|
| N | 样本数 | 代表N个样本 | 无 |
| C | 3 | 分别代表每个关节点的x,y坐标和置信度 | 每个x,y均被放缩至-1到1之间 |
| T | 2500 | 代表动作的持续时间长度,共有2500帧 | 有的动作的实际长度可能不足2500,例如可能只有500的有效帧数,我们在其后重复补充0直到2500帧,来保证T维度的统一性 |
| V | 25 | 代表25个关节点 | 具体关节点的含义可看下方的骨架示例图 |
| M | 1 | 代表1个运动员个数 | 无 |
骨架示例图:
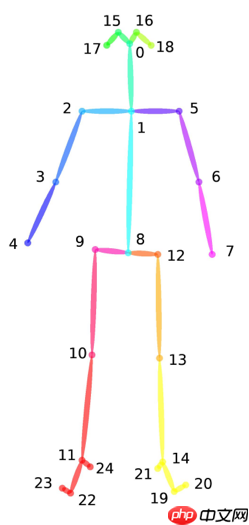
数据集可以从比赛链接处下载,报名成功后,即可获取数据集下载链接。数据集下载完成后,可以将数据集上传到aistudio项目中,上传后的数据集路径在/home/aistudio/data目录下。
如果是直接fork的本项目,在/home/aistudio/data 目录下已经包含了下载好的训练数据和测试数据。注意:由于只能携带两个数据集,故A榜测试集是存放在/home/aistudio/work/PaddleVideo/data/fsd10目录下的。
# 检查数据集所在路径!tree -L 3 /home/aistudio/data !tree -L 3 /home/aistudio/work/PaddleVideo/data/fsd10
/home/aistudio/data
├── data104925
│ ├── train_data.npy
│ └── train_label.npy
└── data117914
└── test_B_data_1118.zip
2 directories, 3 files
/home/aistudio/work/PaddleVideo/data/fsd10
├── example_skeleton.npy
└── test_A_data.zip
0 directories, 2 files1、首先肯定是基于官方baseline的agcn模型调训练参数,为了尽可能的照顾到长时间序列的样本以及统计到有效帧长超于1000的样本训练集占有率不容忽视,控制变量,对比AutoPadding的window_size为500、1000的结果,选择了更优的window_size=1000的配置,至于更大的window_size,考虑到带来的训练代价我认为是不可取的。对比了epochs=100和epochs=200的结果,最终选取了结果更好的epochs=200,与之匹配的是Warmup epochs=20;比较了学习率0.05和0.1,最终选取了0.1;也对标签平滑的系数ls_eps进行了调整,最终选取了ls_eps=0.3。当然也对优化器、学习率策略修改过,但没起到好的作用;Mixup系数保持为最初的优值;CutMix不起作用等等。注意,这些的调整基本都是在设好相同随机数种子1024下进行的。
2、在大部分与1相同的配置(除了ls_eps=1)下,基于官方baseline的agcn模型,分别或同时增加特征注意力(如增加SEBlock)、节点(空间)注意力、时间注意力,全料数据训练在A榜最好取得了66.4的成绩。
3、将训练集划分为了训练集(90%)和验证集(10%),为了进行1的参数调整和对模型进行修改,之后所有训练(除特殊说明)都是仅在划分出来的训练集上进行训练,然后在验证集上验证取得最优(1个epoch验证1次)的验证模型。我们的划分代码中不涉及随机性,在数据集本身样本存放顺序没变下可以保证每次的划分是一致的,从而可以保证可复现性。
4、除注意力机制以外,对模型进行过的一些修改,为了扩大时域感受野,我增加了时域卷积的空洞参数为2、3、4等等,采取多分支级联形式,后来看论文发现这个方向的主流模型早都是这样做了,我加了之后提升不是很满意;由于易过拟合,然后对于改过的这些模型进行过增加模型深度并增加随机深度、增加dropout等等,没有大的提升。之后几乎看完了最近所有相关顶会论文,逐步更换著名的2s-Agcn、Ms-Agcn模型、Ms-G3D模型,发现跑的很慢,性能没怎么提升,比最初的agcn还容易过拟合,也进行过自适应图拓扑结构构建方法修改、模型结构修改等,发现训练速度严重影响了我验证想法,当然那些想法也没起到正的作用。
5、对数据进行处理,看到不少论文的数据,不是padding 0进行补全,而是replay进行补全,故也尝试了对训练、验证数据进行replay之后训练验证,发现更易过拟合了,性能更差了;发现数据集类别分布不均匀,我们对数据集进行label shuffle进行数据集类别均匀扩增,同时对dropout等参数进行调整,发现没有带来性能提升,估计是难识别、易混淆的类别不一定是数目少的类别等。
6、基于5,我无意中发现了Focal loss对于训练类别不均衡很有效,可以自适应地可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
7、构建节点流、骨骼流、节点运动流、骨骼运动流四流框架进行多模型融合。
以上,是我这两个月我还能记起来的一些调优过程,其余的记不起来或者比较琐碎,难以言明,当然没说的对我们最终的方案基本没什么影响。
ctrgcn是ICCV2021的一篇基于GNN进行动作识别的就我所知精度最高的论文提出的模型。我们的方法是基于该方法进行了稍微的修改(失败的大尝试就不再赘述了),第一是,控制变量,我们选取了TCN ks=9(原论文是ks=5),第二,是在fc层之前增加了一层Dropout2D,p=0.5。
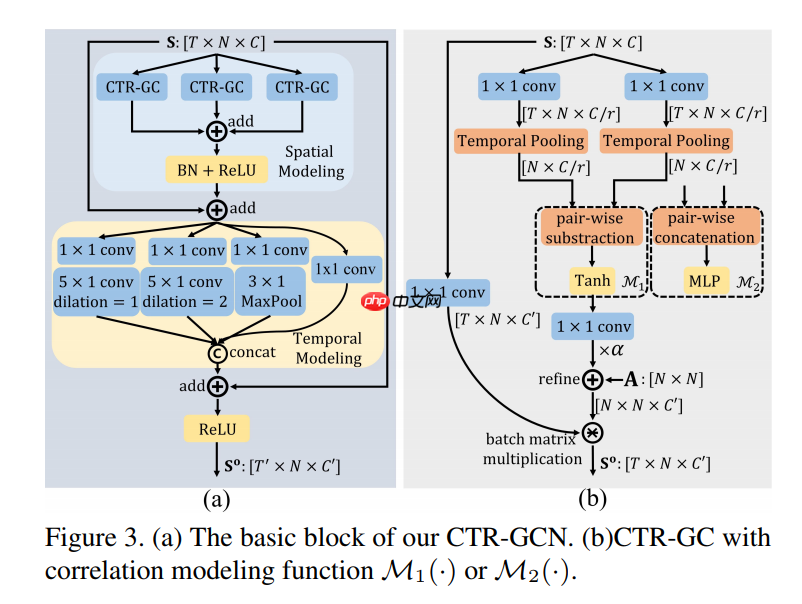
左图是Ctrgcn的两个基本block,其中时间建模是大家常用的多分支级联空洞卷积TCN结构,Ctrgcn使用的是MS_GSD简化的TCN部分,因为分支数过多会使模型速度变慢,注意我们的ks=9。右图是作者的创新之处,CTRGCN的空间GCN模块,对每个样本的每个通道学习了一个自适应的动态的图拓扑结构。
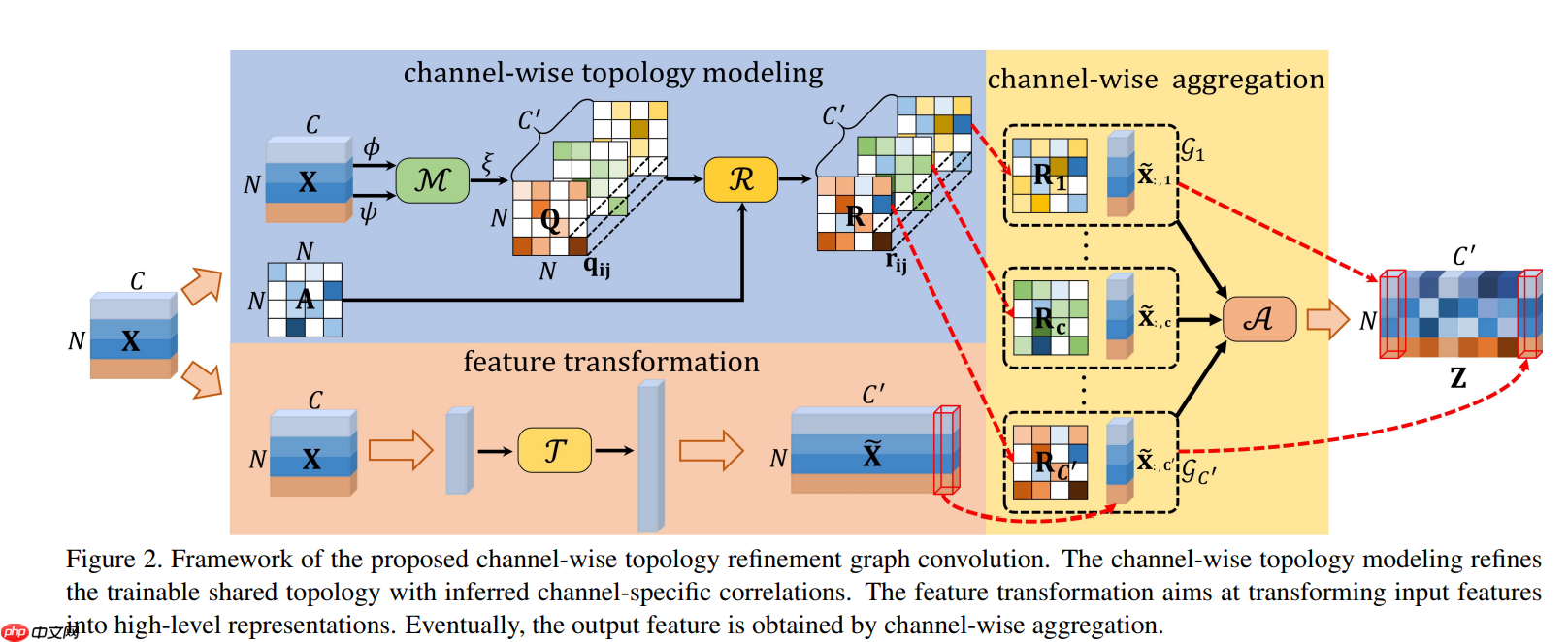
上图是Ctrgcn 空间建模的详细结构。首先是对输入X进行特征变换(降维),得到x1, x2(N, C, T, V);然后进行时间维度全局池化(N, C, V)再利用通道相关性建模函数M()对x1, x2进行处理,M()可以是简单的act(x1-x2),也可以是MLP(x1, x2),这里取的是act(x1-x2),即(N, C, V, 1)-(N, C, 1, V),这样得到(N, C, V, V)的通道特定的关系;最后和初始化为物理图拓扑结构的通道共享自适应图拓扑矩阵(V, V)相加,得到通道细化的图拓扑结构,用来空间信息聚集。
CTGRCN和STGCN除了这两个基本block不同以外,同样是按照STGCN堆叠了10层,每层的通道数、stride等都一致。存放于work/PaddleVideo/paddlevideo/modeling/backbones/agcn.py。参考自原论文源码
采用了focal loss,这个损失函数是在标准交叉熵损失基础上修改得到的,可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。存放于work/PaddleVideo/paddlevideo/modeling/losses/base.py,在
work/PaddleVideo/paddlevideo/modeling/losses/cross_entropy_loss.py 调用
class FocalLoss(nn.Layer):
def __init__(self, alpha=1.0, gamma=2, ignore_index=-100):
super().__init__()
self.alpha = alpha
self.gamma = gamma
self.ignore_index = ignore_index
def forward(self, score, labels, soft_label=False, **kwargs):
pt = F.softmax(score.detach(), axis=-1) if not soft_label:
labels_oh = F.one_hot(labels, pt.shape[-1])
else:
labels_oh = labels
pt = paddle.max(pt*labels_oh, axis=-1, keepdim=True)
loss_ce = F.cross_entropy(score, labels, ignore_index=self.ignore_index, reduction='none', soft_label=soft_label, **kwargs)
#print(loss_ce.shape, pt.shape)
loss = ((1 - pt) ** self.gamma) * self.alpha * loss_ce
return loss.mean()在work/PaddleVideo/configs/recognition/agcn/agcn_fsd.yaml中设置。
MODEL: #MODEL field
framework: "RecognizerGCN" #Mandatory, indicate the type of network, associate to the 'paddlevideo/modeling/framework/' .
backbone: #Mandatory, indicate the type of backbone, associate to the 'paddlevideo/modeling/backbones/' .
name: "AGCN" #Mandatory, The name of backbone.
head:
name: "STGCNHead" #Mandatory, indicate the type of head, associate to the 'paddlevideo/modeling/heads'
num_classes: 30 #Optional, the number of classes to be classified.
ls_eps: 0.3 #0.1DATASET: #DATASET field
batch_size: 16 #Mandatory, bacth size
num_workers: 4 #Mandatory, the number of subprocess on each GPU.
test_batch_size: 1
test_num_workers: 0
train:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "data/fsd10/train_data.npy" #Mandatory, train data index file path
label_path: "data/fsd10/train_label.npy"
valid:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "data/fsd10/val_data.npy" #Mandatory, train data index file path
label_path: "data/fsd10/val_label.npy"
test_mode: True
test:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
#file_path: "/home/aistudio/data/data104924/test_A_data.npy" #Mandatory, valid data index file path
#file_path: "data/fsd10/val_data.npy" #Mandatory, train data index file path
#label_path: "data/fsd10/val_label.npy"
file_path: "/home/aistudio/data/data117914/test_B_data.npy"
test_mode: TruePIPELINE: #PIPELINE field
train: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 1000
#mode: bone_motion
transform: #Mandotary, image transfrom operator
- SkeletonNorm:
valid: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 1000
#mode: bone_motion
transform: #Mandotary, image transfrom operator
- SkeletonNorm:
test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "AutoPadding"
window_size: 1000
#mode: bone
transform: #Mandotary, image transfrom operator
- SkeletonNorm:OPTIMIZER: #OPTIMIZER field
name: 'Momentum'
momentum: 0.9
learning_rate:
iter_step: True
name: 'CustomWarmupCosineDecay'
max_epoch: 200
warmup_epochs: 20
warmup_start_lr: 0.0
cosine_base_lr: 0.1
weight_decay:
name: 'L2'
value: 1e-4 # 1e-4MIX:
name: "Mixup"
alpha: 0.2 # 0.2METRIC:
name: 'SkeletonMetric'
out_file: 'submission.csv'INFERENCE:
name: 'STGCN_Inference_helper'
num_channels: 2
window_size: 1000
vertex_nums: 25
person_nums: 1model_name: "AGCN"output_dir: "./output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_bm"log_interval: 20 #Optional, the interal of logger, default:10epochs: 200 #Mandatory, total epoch#save_interval: 10#resume_epoch: 119val_interval: 1按照该领域的传统,我们也对输入样本在work/PaddleVideo/paddlevideo/loader/pipelines/skeleton_pipeline.py文件中的AutoPadding类中进行修改(得到骨骼数据、节点运动数据或骨骼运动数据),使得可以用mode参数来控制使用节点流、骨骼流、还是节点运动流、骨骼运动流进行模型训练。如此得到了四个在90%训练集训练并在10%验证集验证的最好模型(这四个模型并没有来得及进行全料训练集训练)。
name: "AutoPadding"window_size: 1000mode: bone_motion
def get_bone(joint_data): bone_data = np.zeros_like(joint_data) for v1, v2 in inward_ori_index: bone_data[:, :, v1, :] = joint_data[:, :, v1, :]-joint_data[:, :, v2, :]
return bone_data
def get_joint_motion(joint_data): motion_data = np.zeros_like(joint_data) frame_len = motion_data.shape[1] # C, T, V, M
#print(frame_len)
motion_data[:, :frame_len-1, :, :] = joint_data[:, 1:frame_len, :, :]-joint_data[:, :frame_len-1, :, :]
return motion_data除此之外,我们还有第5个模型,是节点流的除batch_size=8以外其他条件相同的训练验证最好模型。在work/PaddleVideo/paddlevideo/tasks/test.py中修改从而得到五个model使得可以加载五个权重,并根据如下配置对输入模型数据进行处理实现四流框架,最好将这五个模型的输出score进行平均,作为最终的score,得到预测标签,生成提交文件得以提交。
is_joint = ['j', 'j', 'jm', 'b', 'bm']
outputs = 0.
for mi, model in enumerate(models):
if is_joint[mi]=='b':
new_data = copy.deepcopy(data) new_data[0] = get_bone(new_data[0])
pred = model(new_data, mode='test')
elif is_joint[mi]=='jm':
new_data = copy.deepcopy(data) new_data[0] = get_joint_motion(new_data[0])
pred = model(new_data, mode='test')
elif is_joint[mi]=='bm':
new_data = copy.deepcopy(data) new_data[0] = get_bone(new_data[0]) new_data[0] = get_joint_motion(new_data[0])
pred = model(new_data, mode='test') else:
pred = model(data, mode='test')
outputs += pred/len(models) # 最初的,用于节点流
def get_frame_num(self, data):
C, T, V, M = data.shape for i in range(T - 1, -1, -1):
tmp = np.sum(data[:, i, :, :]) if tmp > 0: T = i + 1
break
return T # 改后的,用于其他三流
def get_frame_num(self, data):
C, T, V, M = data.shape for i in range(T - 1, -1, -1): #tmp = np.sum(data[:, i, :, :])
#if tmp > 0:
if np.any(data[:, i, :, :]): T = i + 1
break
return T在work/PaddleVideo/paddlevideo/loader/pipelines/skeleton_pipeline.py文件中的AutoPadding类中的这个函数我在11月16日训练骨骼流时发现IndexError: index 2500 is out of bounds for axis 1 with size 2500这个bug(bug出现原因是:最初的get_frame_num函数把某些bone数据判断为全为0,则按其代码逻辑最后输出T=2500(后面数组索引边界溢出),而不是T=0,总归没有输出真正的有效帧长),故将注释掉的部分注释掉,更改为了我认为更准确求有效帧长的if np.any(data[:, i, :, :]):这句,造成的影响是之前训练的节点流最好模型可能会和用当前的函数训练有细微的区别,在比赛结束准备复现材料时验证发现对于节点流模型,最初版本的get_frame_num函数带来的效果要更好,改后的因为部分样本有效帧长变长,进一步加大了过拟合,导致性能下降。其余四个模型都是在改后训练得到的。因此如果均在原get_frame_num函数下训练,可能取得比现在更好的成绩。不过要复现我们的结果,请对除第一个节点流模型之外的三流模型和bs=8的节点流模型训练使用改后的get_frame_num函数。
模型日志文件有的是由多个文件组成,因为训练中断,重新resume产生的。
虽然设置了随机数种子,但因为每次启动的V100机器不同,底层的cudnn算法的不确定性没有消除,可能会对结果产生略微偏差。没有像torch.backends.cudnn.benchmark=False、torch.backends.cudnn.deterministic=True一样利用paddle限制底层的cudnn选择算法和算法本身的不确定性。
可以在终端输入visualdl service upload --logdir=work/PaddleVideo/output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_b然后复制出来的链接在谷歌浏览器打开就可以看到骨骼流模型的训练日志了。
1、节点流验证集精度曲线,val_best=66.996
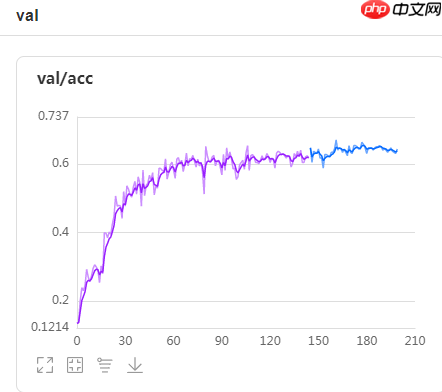
2、骨骼流验证集精度曲线,val_best=67.763
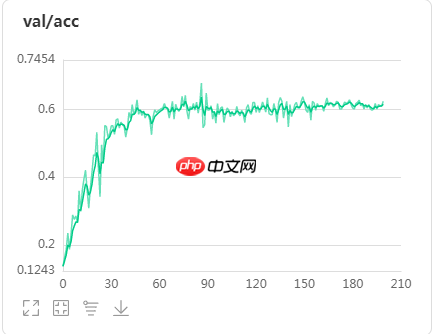
3、节点运动流验证集精度曲线,val_best=61.075
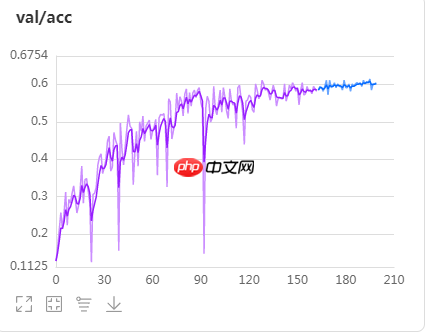
4、骨骼运动流验证集精度曲线,val_best=60.417
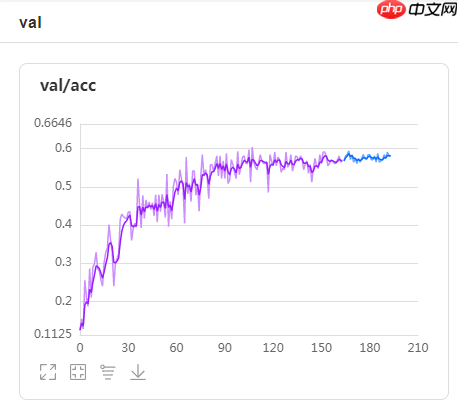
5、bs=8,节点流验证集精度曲线,val_best=67.005
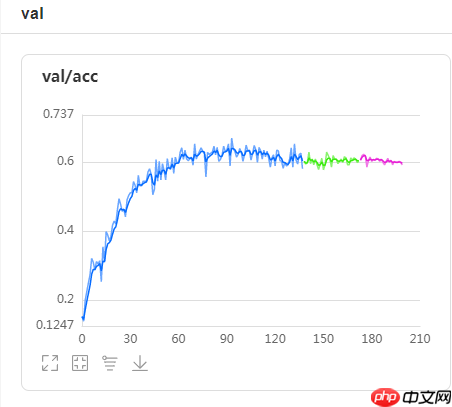
由此五个模型集成取得了A榜15,B榜第3的成绩!
本项目基于PaddleVideo套件完成CTRGCN网络训练:
本项目完全基于PaddleVideo套件实现,代码结构与PaddleVideo一致,与方案有关的主要文件已在三、模型构建思路及调优过程部分提到
configs中放有每个模型对应的配置文件;data文件下存放数据集;output下存放我们输出的模型,paddlevideo是我们训练、搭建模型的工具箱;main.py控制训练、验证、预测,其余的没怎么用到
!tree -L 1 /home/aistudio/work/PaddleVideo/
/home/aistudio/work/PaddleVideo/ ├── configs ├── data ├── docs ├── __init__.py ├── LICENSE ├── main.py ├── MANIFEST.in ├── output ├── paddlevideo ├── README_cn.md ├── README.md ├── requirements.txt ├── run.sh ├── setup.py ├── submission.csv └── tools 6 directories, 10 files
按90%训练集、10%验证集划分,并将划分好的数据集放到work/PaddleVideo/data/fsd10目录下
import numpy as np
labels = np.load("data/data104925/train_label.npy")
data = np.load("data/data104925/train_data.npy")print(len(data))2922
val_index = []for i in range(30):
index = np.argwhere(labels==i).reshape(-1) #print(index)
val_len = round(len(index)*0.1)
val_index.extend(index[:val_len])print(len(val_index))
val_data = data[val_index]
val_labels = labels[val_index]
train_data = np.delete(data, val_index, 0)
train_labels = np.delete(labels, val_index, None)print(len(train_data), len(train_labels), len(val_data), len(val_labels))
np.save("work/PaddleVideo/data/fsd10/train_data.npy", train_data)
np.save("work/PaddleVideo/data/fsd10/train_label.npy", train_labels)
np.save("work/PaddleVideo/data/fsd10/val_data.npy", val_data)
np.save("work/PaddleVideo/data/fsd10/val_label.npy", val_labels)291 2631 2631 291 291
# 进入到PaddleVideo目录下%cd ~/work/PaddleVideo/
/home/aistudio/work/PaddleVideo
!python3.7 -m pip install --upgrade pip !python3.7 -m pip install --upgrade paddlenlp !python3.7 -m pip install --upgrade -r requirements.txt
!python3.7 main.py -c configs/recognition/agcn/agcn_fsd.yaml --validate --amp
你将会看到类似如下的训练日志
请使用GPU版本的配置环境运行本模块
可以在work/PaddleVideo/configs/recognition/agcn下的agcn_fsd.yaml修改训练参数
# 设置随机数种子import paddleimport randomimport osimport numpy as npdef seed_paddle(seed=1024):
seed = int(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
paddle.seed(seed)
seed_paddle(1024)# 为了加快训练,使用混合精度训练!python3.7 main.py -c configs/recognition/agcn/agcn_fsd.yaml --validate --amp
上面是默认节点流模型训练的,将work/PaddleVideo/configs/recognition/agcn下的agcn_fsd.yaml中的
name: "AutoPadding"window_size: 1000mode: bone
train和valid部分的mode改为bone、joint_motion 或 bone_motion再重启环境,从(三)训练模型再次开始运行即可进行其他三流模型的训练,batch_size设为8可以进行bs=8的节点流训练。
注意:每次进行不同实验要记得修改work/PaddleVideo/configs/recognition/agcn下的agcn_fsd.yaml中的output_dir,不然会覆盖掉之前训练的结果!!!还有不要和work/PaddleVideo/output/AGCN下的
ctrgcn_dr05_leps03_ks9_nofreeze_floss、ctrgcn_dr05_leps03_ks9_nofreeze_floss_b、ctrgcn_dr05_leps03_ks9_nofreeze_floss_jm、ctrgcn_dr05_leps03_ks9_nofreeze_floss_bm、ctrgcn_dr05_leps03_ks9_nofreeze_floss_bs8
重名,因为可能会把我的最优结果覆盖掉!!!如果训练中途因网络或其他意外断开,可以修改work/PaddleVideo/configs/recognition/agcn下的agcn_fsd.yaml中的resume_epoch从断开处继续训练。
即训练节点流的时候要修改work/PaddleVideo/paddlevideo/loader/pipelines/skeleton_pipeline.py文件中的AutoPadding类中的这个函数为以下形式:
# 最初的,用于节点流
def get_frame_num(self, data):
C, T, V, M = data.shape for i in range(T - 1, -1, -1):
tmp = np.sum(data[:, i, :, :]) if tmp > 0: T = i + 1
break
return T如果复现其他三流和bs=8的节点流模型,请使用这个函数的以下形式:
# 改后的,用于其他三流
def get_frame_num(self, data):
C, T, V, M = data.shape for i in range(T - 1, -1, -1): #tmp = np.sum(data[:, i, :, :])
#if tmp > 0:
if np.any(data[:, i, :, :]): T = i + 1
break
return T最后,准备复现材料时,验证发现,最初的get_frame_num函数只对bone流数据产生索引超出边界的错误(原因回顾三、模型构建思路及调优过程),其他三流无bug。因此对于bone流以外的三流,如果不以复现我们方案为目的,可以尝试一下最初的get_frame_num函数是否会带来更好的结果,这留为未来的验证。
模型训练完成后,可使用测试脚本进行预测得到我们的提交文件,
!python3.7 main.py --test -c configs/recognition/agcn/agcn_fsd.yaml -w output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss/AGCN_best.pdparams
通过-c参数指定配置文件,通过-w指定权重存放路径进行模型测试。
评估结果保存在submission.csv文件中,可在评测官网提交查看得分。
虽然这里只指定了一个节点流的模型权重存放路径,但其实我们在work/PaddleVideo/paddlevideo/tasks/test.py内部还写着四个其他三流和bs=8节点流的模型权重路径,因此实际上构建的是5个模型,分别加载5个权重
weights = [weights]+["output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_bs8/AGCN_best138.pdparams", "output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_jm/AGCN_best163.pdparams", \ "output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_b/AGCN_best.pdparams", "output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_bm/AGCN_best164.pdparams"] models = [] for w in weights:
state_dicts = load(w) models.append(build_model(cfg.MODEL)) models[-1].eval() models[-1].set_state_dict(state_dicts)同时可以回顾三、模型构建思路及调优过程部分可以知道我们已经修改test.py文件完成了四流框架+bs=8节点流共5个模型集成的工作,可以直接得到集成后的预测结果。如果使用自己的模型权重预测,请注意对应修改
weights = [weights]+["output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_bs8/AGCN_best138.pdparams", "output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_jm/AGCN_best163.pdparams", \ "output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_b/AGCN_best.pdparams", "output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss_bm/AGCN_best164.pdparams"]
is_joint = ['j', 'j', 'jm', 'b', 'bm']
这两部分,over~
test:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/work/PaddleVideo/data/fsd10/test_A_data.npy"
test_mode: True!unzip -oq /home/aistudio/work/PaddleVideo/data/fsd10/test_A_data.zip -d /home/aistudio/work/PaddleVideo/data/fsd10
!python3.7 main.py --test -c configs/recognition/agcn/agcn_fsd.yaml -w output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss/AGCN_best.pdparams
test:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "/home/aistudio/data/data117914/test_B_data.npy"
test_mode: True!unzip -oq /home/aistudio/data/data117914/test_B_data_1118.zip -d /home/aistudio/data/data117914/
!python3.7 main.py --test -c configs/recognition/agcn/agcn_fsd.yaml -w output/AGCN/ctrgcn_dr05_leps03_ks9_nofreeze_floss/AGCN_best.pdparams
# 验证复现结果与我们的是否一致import pandas as pdimport numpy as np
df1 = pd.read_csv("submission_B.csv") # 换成submission_A.csv即可验证A榜df2 = pd.read_csv("submission.csv") # 这里是你生成的提交文件np.sum(df1["predict_category"].values!=df2["predict_category"].values)0
以上就是2021 CCF BDCI基于飞桨实现花样滑冰选手骨骼点动作识别-B榜第3名方案的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 849
849






















