
目标url:
http://www.xiaopian.com/html/...
这个是chrome里显示的源代码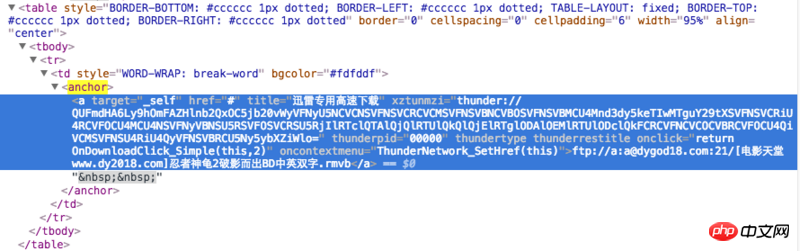
这个是scrapy shell url后用response.css().extract()显示东西
我想知道为何二者不一致?scrapy爬取到的信息并没有对应的thunder链接,而是明面上的ftp链接



Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 1455
1455
















学习是最好的投资!