
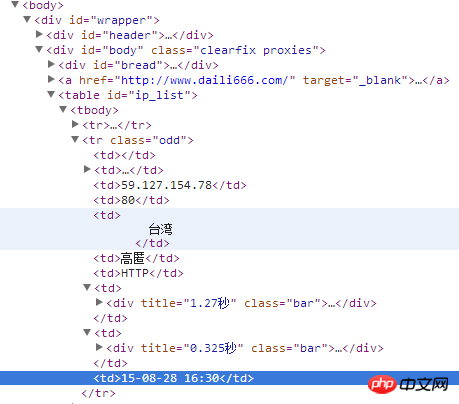
爬取网址是:http://www.xici.net.co/nn/1
以上是HTML网页内容,
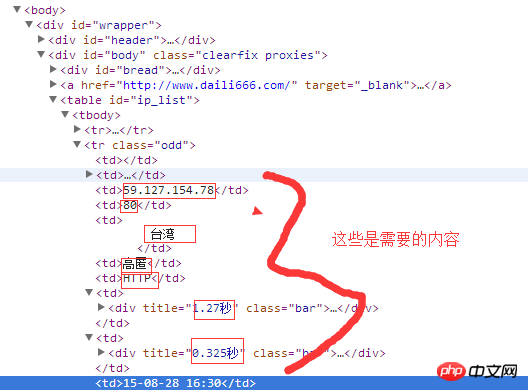
需获取IP地址,端口号,地方,是否高匿,两个时间
一下是我写的Python,但只能实现部分,请各位大神指点下
谢谢。。。。
import re
import urllib
a = raw_input('input url:')
s = urllib.urlopen(a)
s1 = s.read()
def getinfo(aaa):
#reg = re.compile(r'(?(\d+)\.(\d+)\.(\d+)\.(\d+)\s*(\d+) \s*([/u4e00-/u9fa5]+) ')
reg = re.compile(r'(\w+) \s*([\u4e00-\u9fa5]+) ')
l = re.findall(reg, aaa)
print l
getinfo(s1)结果是类似下面的,不一定是表格
|ip|端口号|位置|是否高匿|类型|速度|连接时间|验证时间|
|-|-|-|-|-|-|-|-|-|
|122.89.9.70|80|台湾|高匿|HTTP|1.27秒|0.325秒|15-08-28 16:30|
|123.69.48.45|8080|江苏南京|高匿|HTTPS|1.07秒|0.5秒|15-08-28 17:30|



Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 8
8 607
607
















用xpath去找吧。。 lxml解析
用re来操作html,也是醉了,xpath吧。
推荐用BeautifulSoup
BeautifulSoup 是一个很好的选择,自己写正则表达式代码也显得不够优雅。
……scrapy呀
scrapy...