


快准备好你的 gpu!
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

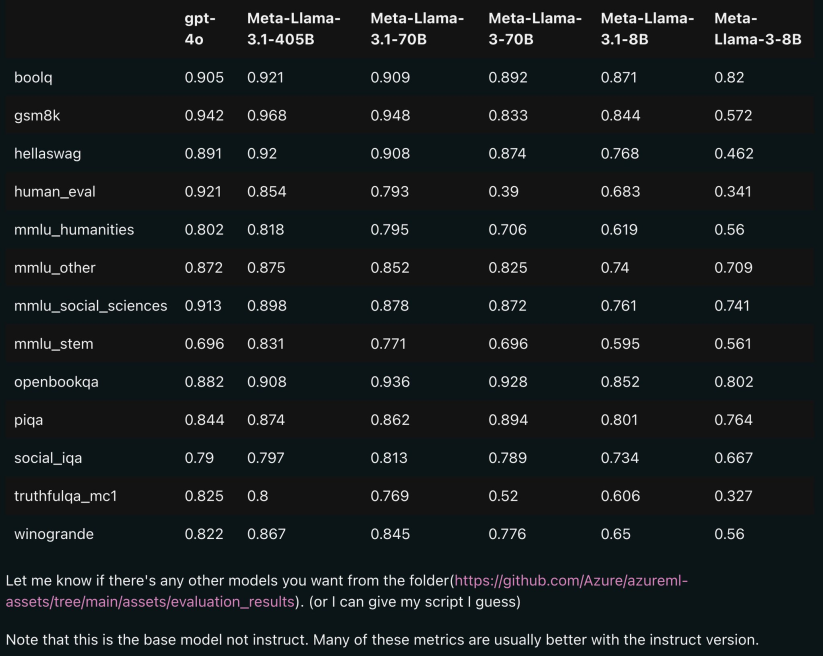
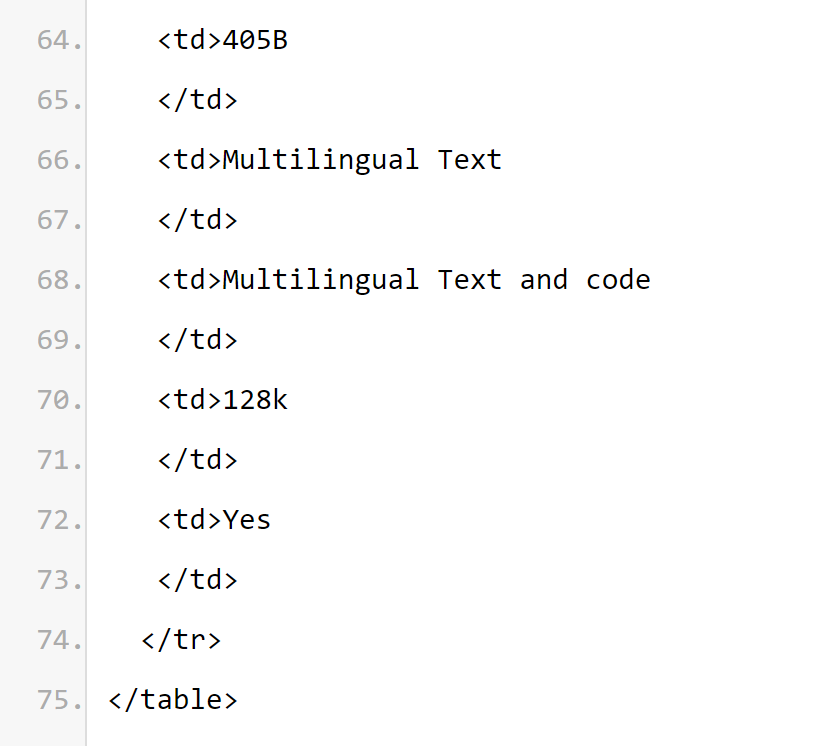
模型使用了公开来源的 15T+ tokens 进行训练,预训练数据截止日期为 2023 年 12 月; 微调数据包括公开可用的指令微调数据集(与 Llama 3 不同)和 1500 万个合成样本; 模型支持多语言,包括英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。








0


0

王林
发布时间:2024-07-23 18:28:01
|527人浏览过
|来源于机器之心
转载
快准备好你的 gpu!
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
相关文章
Yu-Gi-Oh!卡牌构筑深度指南:策略、角色与Meta分析
AI裁员潮真相揭秘:企业裁员背后的真实原因与应对策略
Meta AI Chatbot风波:退休老人深陷AI情网去世
AI深度探索:Meta AI研究突破与未来应用洞察
Meta SAM:AI图像分割新纪元,零样本学习颠覆传统
本站声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn
热门AI工具

相关专题

登录token无效解决方法:1、检查token的有效期限,如果token已经过期,需要重新获取一个新的token;2、检查token的签名,如果签名不正确,需要重新获取一个新的token;3、检查密钥的正确性,如果密钥不正确,需要重新获取一个新的token;4、使用HTTPS协议传输token,建议使用HTTPS协议进行传输 ;5、使用双因素认证,双因素认证可以提高账户的安全性。
6489
2023.09.14

登录token无效的解决办法有检查Token是否过期、检查Token是否正确、检查Token是否被篡改、检查Token是否与用户匹配、清除缓存或Cookie、检查网络连接和服务器状态、重新登录或请求新的Token、联系技术支持或开发人员等。本专题为大家提供token相关的文章、下载、课程内容,供大家免费下载体验。
839
2023.09.14

获取token值的方法:1、小程序调用“wx.login()”获取 临时登录凭证code,并回传到开发者服务器;2、开发者服务器以code换取,用户唯一标识openid和会话密钥“session_key”。想了解更详细的内容,可以阅读本专题下面的文章。
1088
2023.12.21

token是一种用于表示用户权限、记录交易信息、支付虚拟货币的数字货币。可以用来在特定的网络上进行交易,用来购买或出售特定的虚拟货币,也可以用来支付特定的服务费用。想了解更多token什么意思的相关内容可以访问本专题下面的文章。
1789
2024.03.01

github中文官网入口https://docs.github.com/zh/get-started,GitHub 是一种基于云的平台,可在其中存储、共享并与他人一起编写代码。 通过将代码存储在GitHub 上的“存储库”中,你可以: “展示或共享”你的工作。 持续“跟踪和管理”对代码的更改。
3310
2026.01.21

http与https的区别:1、协议安全性;2、连接方式;3、证书管理;4、连接状态;5、端口号;6、资源消耗;7、兼容性。本专题为大家提供相关的文章、下载、课程内容,供大家免费下载体验。
2749
2024.08.16

Go语言测试体系与代码质量保障聚焦于构建工程级可靠性系统。本专题深入解析Go的测试工具链(如go test)、单元测试、集成测试及端到端测试实践,结合代码覆盖率分析、静态代码扫描(如go vet)和动态分析工具,建立全链路质量监控机制。通过自动化测试框架、持续集成(CI)流水线配置及代码审查规范,实现测试用例管理、缺陷追踪与质量门禁控制,确保代码健壮性与可维护性,为高可靠性工程系统提供质量保障。
43
2026.02.28

Go语言工程化架构设计专注于构建高可维护性、可演进的企业级系统。本专题深入探讨Go项目的目录结构设计、模块划分、依赖管理等核心架构原则,涵盖微服务架构、领域驱动设计(DDD)在Go中的实践应用。通过实战案例解析接口抽象、错误处理、配置管理、日志监控等关键工程化技术,帮助开发者掌握构建稳定、可扩展Go应用的最佳实践方法。
38
2026.02.28

Go语言以其高效的并发模型和优异的性能表现广泛应用于高并发、高性能场景。其运行时机制包括 Goroutine 调度、内存管理、垃圾回收等方面,深入理解这些机制有助于编写更高效稳定的程序。本专题将系统讲解 Golang 的性能分析工具使用、常见性能瓶颈定位及优化策略,并结合实际案例剖析 Go 程序的运行时行为,帮助开发者掌握构建高性能应用的关键技能。
35
2026.02.28
热门下载
相关下载
精品课程

共12课时 | 0.6万人学习

共12课时 | 1万人学习

共50课时 | 4.6万人学习
最新文章
Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号















