







对基础模型进行 scaling 是指使用更多数据、计算和参数进行预训练,简单来说就是「规模扩展」。
虽然直接扩展模型规模看起来简单粗暴,但也确实为机器学习社区带来了不少表现突出的模型。之前不少研究都认可扩大神经经济模型规模的做法,所谓量变引起质变,这种观点也被称为神经扩展律(neural scaling laws)。 然而,随着模型规模的增加,带来的是计算资源的密集消耗。这意味着更大规模的模型需要更多的计算资源,包括处理器和内存。这对于许多实际应用来说是不可行的,尤其是在资源有限的设备上。 因此,研究人员开始关注如何更高效地使用计算资源以提高模
近段时间,又有不少人认为“数据”才是那些当前最佳的关闭源模型的关键,不管是 LLM、VLM 还是扩散模型。随着数据质量的重要性得到认可,已经涌现出了不少旨在提升数据质量的研究:要么是从大型数据库中过滤出高质量数据,要么是生成高质量的新数据。但是,过去的扩展律一般是将“数据”视为一个同质实体,并未将近期人们关注的“数据质量”作为一个考量维度。
尽管网络上的数据模型庞大,但高质量数据(基于多个评估指标)通常很有限。现在,开创性的研究来了——数据过滤维度上的扩展律!它来自卡内基梅隆大学和Bosch Center for AI,其中尤其关注了「大规模」与「高质量」之间的数量 - 质量权衡(QQT)。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

- 论文标题:Scaling Laws for Data Filtering—Data Curation cannot be Compute Agnostic
- 论文地址:https://arxiv.org/pdf/2404.07177.pdf
- 代码地址:https://github.com/locuslab/scaling_laws_data_filtering
如图 1 所示,当训练多个 epoch 时,高质量数据的效用(utility)就不大了(因为模型已经完成了学习)。

此时,使用更低质量的数据(一开始的效用更小)往往比重复使用高质量数据更有助益。
在数量 - 质量权衡(QQT)之下,我们该如何确定训练使用怎样的数据搭配更好?
为了解答这个问题,任何数据整编(data curation)工作流程都必须考虑模型训练所用的总计算量。这不同于社区对数据过滤(data filtering)的看法。举个例子,LAION 过滤策略是从常见爬取结果中提取出质量最高的 10%。
但从图 2 可以看出,很明显一旦训练超过 35 epoch,在完全未整编的数据集上训练的效果优于在使用 LAION 策略整编的高质量数据上训练的效果。

当前的神经扩展律无法建模质量与数量之间这种动态的权衡。此外,视觉 - 语言模型的扩展律研究甚至还要更加更少,目前的大多数研究都仅限于语言建模领域。
今天我们要介绍的这项开创性研究攻克了之前的神经扩展律的三大重要局限,其做到了:
(1)在扩展数据时考虑「质量」这个轴;
(2)估计数据池组合的扩展律(而无需真正在该组合上进行训练),这有助于引导实现最优的数据整编决策;
(3)调整 LLM 扩展律,使之适用于对比训练(如 CLIP),其中每一批都有平方数量的比较次数。
该团队首次针对异构和数量有限的网络数据提出了扩展律。
大型模型是在多种质量的数据池组合上训练完成的。通过对从各个数据池的扩散参数(如图 1 (a) 中的 A-F)派生的聚合数据效用进行建模,就可以直接估计模型在这些数据池的任意组合上的性能。
需要重点指出,这种方法并不需要在这些数据池组合上进行训练就能估计它们的扩展律,而是可以根据各个组成池的扩展参数直接估计它们的扩展曲线。
相比于过去的扩展律,这里的扩展律有一些重要差异,可以建模对比训练机制中的重复,实现 O (n²) 比较。举个例子,如果训练池的大小倍增,对模型损失有影响的比较次数就会变成原来的四倍。
他们用数学形式描述了来自不同池的数据的相互交互方式,从而可以在不同的数据组合下估计模型的性能。这样便可以得到适合当前可用计算的数据整编策略。
这项研究给出的一个关键信息是:数据整编不能脱离计算进行。
当计算预算少时(更少重复),在 QQT 权衡下质量优先,如图 1 中低计算量下的激进过滤(E)的最佳性能所示。
另一方面,当计算规模远超过所用训练数据时,有限高质量数据的效用会下降,就需要想办法弥补这一点。这会得到不那么激进的过滤策略,即数据量更大时性能更好。
该团队进行了实验论证,结果表明这个用于异构网络数据的新扩展律能够使用 DataComp 的中等规模池(128M 样本)预测从 32M 到 640M 的各种计算预算下的帕累托最优过滤策略。
一定计算预算下的数据过滤
该团队通过实验研究了不同计算预算下数据过滤的效果。
他们使用一个大型初始数据池训练了一个 VLM。至于基础的未过滤数据池,他们选用了近期的数据整编基准 Datacomp 的「中等」规模版本。该数据池包含 128M 样本。他们使用了 18 个不同的下游任务,评估的是模型的零样本性能。
他们首先研究了用于获得 LAION 数据集的 LAION 过滤策略,结果见图 2。他们观察到了以下结果:
1. 在计算预算低时,使用高质量数据更好。
2. 当计算预算高时,数据过滤会造成妨害。
原因为何?
LAION 过滤会保留数据中大约 10% 的数据,因此计算预算大约为 450M,来自已过滤 LAION 池的每个样本会被使用大约 32 次。这里的关键见解是:对于同一个样本,如果其在训练过程中被多次看见,那么每一次所带来的效用就会下降。
之后该团队又研究了其它两种数据过滤方法:
(1)CLIP 分数过滤,使用了 CLIP L/14 模型;
(2)T-MARS,在掩蔽了图像中的文本特征(OCR)后基于 CLIP 分数对数据进行排名。对于每种数据过滤方法,他们采用了四个过滤层级和多种不同的总计算量。
图 3 给出了在计算规模为 32M、128M、640M 时 Top 10-20%、 Top 30%、Top 40% CLIP 过滤的结果比较。

在 32M 计算规模时,高度激进的过滤策略(根据 CLIP 分数仅保留前 10-20%)得到的结果最好,而最不激进的保留前 40% 的过滤方法表现最差。但是,当计算规模扩展到 640M 时,这个趋势就完全反过来了。使用 T-MARS 评分指标也能观察类似的趋势。
数据过滤的扩展律
该团队首先用数学方式定义了效用(utility)。
他们的做法不是估计 n 的样本在训练结束时的损失,而是考虑一个样本在训练阶段的任意时间点的瞬时效用。其数学公式为:

这表明,一个样本的瞬时效用正比于当前损失且反比于目前所见到的样本数量。这也符合我们的直观想法:当模型看到的样本数量变多,样本的效用就会下降。其中的重点是数据效用参数 b 。
接下来是数据被重复使用之下的效用。
数学上,一个被见到 k+1 次的样本的效用参数 b 的定义为:

其中 τ 是效用参数的半衰期。τ 值越高,样本效用随着重复而衰减得越慢。δ 则是效用随重复的衰减情况的简洁写法。那么,模型在看过 n 个样本且每个样本都被看过 k 次之后的损失的表达式就为:

其中 n_j 是在第 j 轮训练 epoch 结束时的模型看到的样本数量。这一等式是新提出的扩展律的基础。
最后,还有一层复杂性,即异构的网络数据。
然后就得到了他们给出的定理:给定随机均匀采样的 p 个数据池,其各自的效用和重复参数分别为 (b_1, τ_1)...(b_p, τ_p),则每个 bucket 的新重复半衰期就为 τˆ = p・τ。此外,组合后的数据池在第 k 轮重复时的有效效用值 b_eff 是各个效用值的加权平均值。其数学形式为:

其中 ,这是新的每 bucket 衰减参数。
,这是新的每 bucket 衰减参数。
最后,可以在 (3) 式中使用上述定理中的 b_eff,就能估计出在数据池组合上进行训练时的损失。
针对各种数据效用池拟合扩展曲线
该团队用实验探究了新提出的扩展律。
图 4 给出了拟合后的各种数据效用池的扩展曲线,其使用的数据效用指标是 T-MARS 分数。
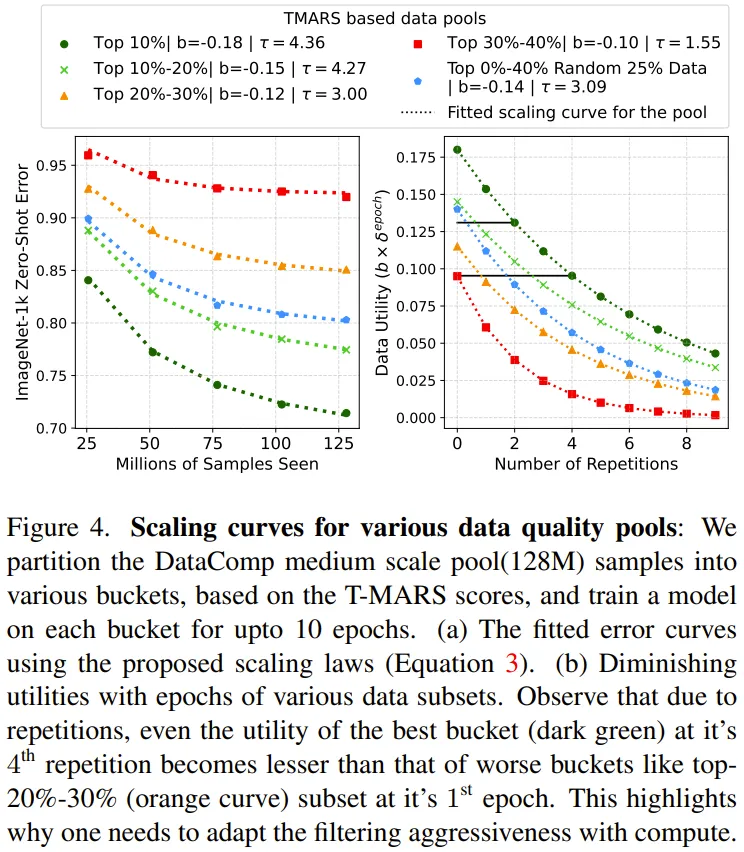
图 4 的第 2 列表明各个数据池的效用会随 epoch 增多而降低。下面是该团队给出的一些重要观察结果:
1. 网络数据是异构的,无法通过单一一组扩展参数进行建模。
2. 不同数据池有不同的数据多样性。
3. 具有重复现象的高质量数据的效果赶不上直接使用低质量数据。
结果:在 QQT 下为数据组合估计扩展律
前面针对不同质量的数据池推断了各自相应的参数 a、b、d、τ。而这里的目标是确定当给定了训练计算预算时,最有效的数据整编策略是什么。
通过前面的定理以及各个数据池的扩展参数,现在就能估计不同池组合的扩展律了。举个例子,可以认为 Top-20% 池是 Top-10% 和 Top 10%-20% 池的组合。然后,这种来自扩展曲线的趋势就可以用于预测给定计算预算下的帕累托最优数据过滤策略。
图 5 给出了不同数据组合的扩展曲线,这是在 ImageNet 上评估的。

这里需要强调,这些曲线是基于上述定理,直接根据各个组成池的扩展参数估计的。他们并未在这些数据池组合上训练来估计这些扩展曲线。散点是实际的测试性能,其作用是验证估计得到的结果。
可以看到:(1)当计算预算低 / 重复次数少时,激进的过滤策略是最好的。
(2)数据整编不能脱离计算进行。
对扩展曲线进行扩展
2023 年 Cherti et al. 的论文《Reproducible scaling laws for contrastive language-image learning》研究了针对 CLIP 模型提出的扩展律,其中训练了计算规模在 3B 到 34B 训练样本之间的数十个模型,并且模型涵盖不同的 ViT 系列模型。在这样的计算规模上训练模型的成本非常高。Cherti et al. (2023) 的目标是为这一系列的模型拟合扩展律,但对于在小数据集上训练的模型,其扩展曲线有很多错误。
CMU 这个团队认为这主要是因为他们没考虑到重复使用数据造成的效用下降问题。于是他们使用新提出的扩展律估计了这些模型的误差。
图 6 是修正之后扩展曲线,其能以很高的准确度预测误差。

这表明新提出的扩展律适用于用 34B 数据计算训练的大型模型,这说明在预测模型训练结果时,新的扩展律确实能考虑到重复数据的效用下降情况。
更多技术细节和实验结果请参阅原论文。




























