







译者 | 陈峻
审校 | 重楼
在本文中,我将向您介绍“少样本(few-shot)学习”的相关概念,并重点讨论被广泛应用于文本分类的setfit方法。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

传统的机器学习(ML)
在监督(Supervised)机器学习中,大量数据集被用于模型训练,以便磨练模型能够做出精确预测的能力。在完成训练过程之后,我们便可以利用测试数据,来获得模型的预测结果。然而,这种传统的监督学习方法存在着一个显著缺点:它需要大量无差错的训练数据集。但是并非所有领域都能够提供此类无差错数据集。因此,“少样本学习”的概念应运而生。
在深入研究Sentence Transformer fine-tuning(SetFit)之前,我们有必要简要地回顾一下自然语言处理(Natural Language Processing,NLP)的一个重要方面,也就是:“少样本学习”。
少样本学习
少样本学习是指:使用有限的训练数据集,来训练模型。模型可以从这些被称为支持集的小集合中获取知识。此类学习旨在教会少样本模型,辨别出训练数据中的相同与相异之处。例如,我们并非要指示模型将所给图像分类为猫或狗,而是指示它掌握各种动物之间的共性和区别。可见,这种方法侧重于理解输入数据中的相似点和不同点。因此,它通常也被称为元学习(meta-learning)、或是从学习到学习(learning-to-learn)。
值得一提的是,少样本学习的支持集,也被称为k向(k-way)n样本(n-shot)学习。其中“k”代表支持集里的类别数。例如,在二分类(binary classification)中,k 等于 2。而“n”表示支持集中每个类别的可用样本数。例如,如果正分类有10个数据点,而负分类也有10个数据点,那么 n就等于10。总之,这个支持集可以被描述为双向10样本学习。
既然我们已经对少样本学习有了基本的了解,下面让我们通过使用SetFit进行快速学习,并在实际应用中对电商数据集进行文本分类。
SetFit架构
由Hugging Face和英特尔实验室的团队联合开发的SetFit,是一款用于少样本照片分类的开源工具。你可以在项目库链接--https://github.com/huggingface/setfit?ref=hackernoon.com中,找到关于SetFit的全面信息。
就输出而言,SetFit仅用到了客户评论(Customer Reviews,CR)情感分析数据集里、每个类别的八个标注示例。其结果就能够与由三千个示例组成的完整训练集上,经调优的RoBERTa Large的结果相同。值得强调的是,就体积而言,经微优的RoBERTa模型比SetFit模型大三倍。下图展示的是SetFit架构:
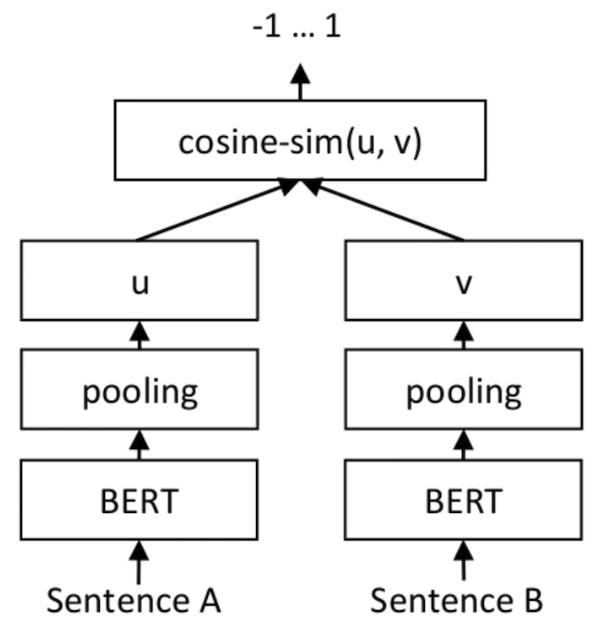
图片来源:https://www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bf
用SetFit实现快速学习
SetFit的训练速度非常快,效率也极高。与GPT-3和T-FEW等大模型相比,其性能极具竞争力。请参见下图:
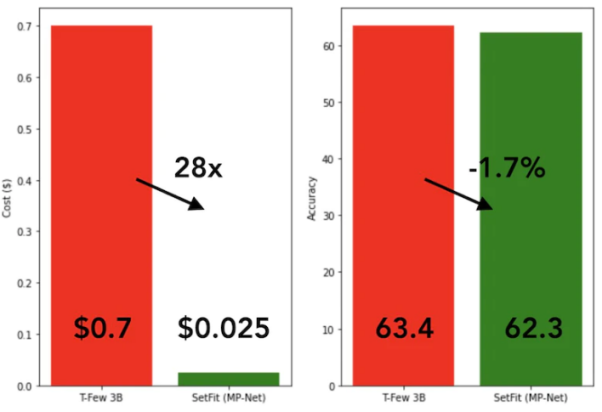 SetFit与T-Few 3B模型的比较
SetFit与T-Few 3B模型的比较
如下图所示,SetFit在少样本学习方面的表现优于RoBERTa。
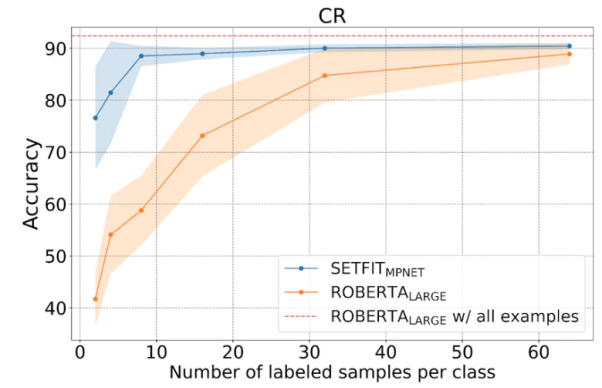
SetFit与RoBERT的比较,图片来源:https://www.php.cn/link/3ff4cea152080fd7d692a8286a587a67
数据集
下面,我们将用到由四个不同类别组成的独特电商数据集,它们分别是:书籍、服装与配件、电子产品、以及家居用品。该数据集的主要目的是将来自电商网站的产品描述归类到指定的标签下。
为了便于采用少样本的训练方法,我们将从四个类别中各选择八个样本,从而得到总共32个训练样本。而其余样本则将留作测试之用。简言之,我们在此使用的支持集是4向8样本学习。下图展示的是自定义电商数据集的示例:
 自定义电商数据集样本
自定义电商数据集样本
我们采用名为“all-mpnet-base-v2”的Sentence Transformers预训练模型,将文本数据转换为各种向量嵌入。该模型可以为输入文本,生成维度为768的向量嵌入。
如下命令所示,我们将通过在conda环境(是一个开源的软件包管理系统和环境管理系统)中安装所需的软件包,来开始SetFit的实施。
!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
安装完软件包后,我们便可以通过如下代码加载数据集了。
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})我们来参照下图,看看训练样本和测试样本数。
一款WordPress内核的物流公司网站主题,适合各大物流公司企业建站用,商业主题,免费分享,本主题分享目的旨在学习参考之用,无任何收费行为。 wordpress官方网站上下载并安装wordpress3.32及以上版本。安装方法:上传后进者wp主题至wp-content\themes文件夹,进入后台"外观-主题-选择主题-启用"激活本主题。此为作者在Chinaz投稿第三版,请保
 训练和测试数据
训练和测试数据
我们使用sklearn软件包中的LabelEncoder,将文本标签转换为编码标签。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
通过LabelEncoder,我们将对训练和测试数据集进行编码,并将编码后的标签添加到数据集的“标签”列中。请参见如下代码:
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)下面,我们将初始化SetFit模型和句子转换器(sentence-transformers)模型。
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})初始化完成两个模型后,我们现在便可以调用训练程序了。
trainer.train()
在完成了2个训练轮数(epoch)后,我们将在eval_dataset上,对训练好的模型进行评估。
trainer.evaluate()
经测试,我们的训练模型的最高准确率为87.5%。虽然87.5%的准确率并不算高,但是毕竟我们的模型只用了32个样本进行训练。也就是说,考虑到数据集规模的有限性,在测试数据集上取得87.5%的准确率,实际上是相当可观的。
此外,SetFit还能够将训练好的模型,保存到本地存储器中,以便后续从磁盘加载,用于将来的预测。
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)如下代码展示了根据新的数据进行的预测结果:
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
可见,其预测输出为1,而标签的LabelEncoded值为“服装与配件”。由于传统的AI模型需要大量的训练资源(包括时间和数据),才能有稳定水准的输出。而我们的模型与之相比,既准确又高效。
至此,相信您已经基本掌握了“少样本学习”的概念,以及如何使用SetFit来进行文本分类等应用。当然,为了获得更深刻的理解,我强烈建议您选择一个实际场景,创建一个数据集,编写对应的代码,并将该过程延展到零样本学习、以及单样本学习上。
译者介绍
陈峻(Julian Chen)是51CTO社区的编辑,他在IT项目实施方面有十多年的经验,擅长管理内外部资源和风险,并专注于传播网络和信息安全的知识和经验
原文标题:Mastering Few-Shot Learning with SetFit for Text Classification,作者:Shyam Ganesh S)




























