







9 月 12 日,淘天集团联合爱橙科技正式对外开源大模型训练框架 ——megatron-llama,旨在让技术开发者们能够更方便的提升大语言模型训练性能,降低训练成本,并且保持和 llama 社区的兼容性。测试显示,在 32 卡训练上,相比 huggingface 上直接获得的代码版本,megatron-llama 能够取得 176% 的加速;在大规模的训练上,megatron-llama 相比较 32 卡拥有几乎线性的扩展性,而且对网络不稳定表现出高容忍度。目前 megatron-llama 已在开源社区上线。
开源地址:https://github.com/alibaba/megatron-llama

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
在 32 卡训练上,相比 HuggingFace 上直接获得的代码版本,Megatron-LLaMA 能够取得 176% 的加速;即便是采用 DeepSpeed 及 FlashAttention 优化过的版本,Megatron-LLaMA 仍然能减少至少 19% 的训练时间。 在大规模的训练上,Megatron-LLaMA 相比较 32 卡拥有着几乎线性的扩展性。例如使用 512 张 A100 复现 LLaMA-13B 的训练,Megatron-LLaMA 的反向机制相对于原生 Megatron-LM 的 DistributedOptimizer 能够节约至少两天的时间,且没有任何精度损失。 -
Megatron-LLaMA 对网络不稳定表现出高容忍度。即便是在现在性价比较高的 4x200Gbps 通信带宽的 8xA100-80GB 训练集群(这种环境通常是混部环境,网络只能使用一半的带宽,网络带宽是严重的瓶颈,但租用价格相对低廉)上,Megatron-LLaMA 仍然能取得 0.85 的线性扩展能力,然而在这个指标上 Megatron-LM 仅能达到不足 0.7。 Megatron-LM 技术带来的高性能 LLaMA 训练机会 LLaMA 是目前大语言模型开源社区中一项重要工作。LLaMA 在 LLM 的结构中引入了 BPE 字符编码、RoPE 位置编码、SwiGLU 激活函数、RMSNorm 正则化以及 Untied Embedding 等优化技术,在许多客观和主观评测中取得了卓越的效果。LLaMA 提供了 7B、13B、30B、65B/70B 的版本,适用于各类大模型需求的场景,也受到广大开发者的青睐。同诸多开源大模型一样,由于官方只提供了推理版的代码,如何以最低成本开展高效训练,并没有一个标准的范式。 Megatron-LM 是一种优雅的高性能训练解决方案。Megatron-LM 中提供了张量并行(Tensor Parallel,TP,把大乘法分配到多张卡并行计算)、流水线并行(Pipeline Parallel,PP,把模型不同层分配到不同卡处理)、序列并行(Sequence Parallel, SP,序列的不同部分由不同卡处理,节约显存)、DistributedOptimizer 优化(类似 DeepSpeed Zero Stage-2,切分梯度和优化器参数至所有计算节点)等技术,能够显著减少显存占用并提升 GPU 利用率。Megatron-LM 运营着一个活跃的开源社区,持续有新的优化技术、功能设计合并进框架中。 然而,基于 Megatron-LM 进行开发并不简单,在昂贵的多卡机上调试及功能性验证更是十分昂贵的。Megatron-LLaMA 首先提供了一套基于 Megatron-LM 框架实现的 LLaMA 训练代码,支持各种规模的模型版本,并且可以很简单地适配支持 LLaMA 的各类变种,包括对 HuggingFace 格式的 Tokenizer 的直接支持。于是,Megatron-LLaMA 可以很便捷地应用在已有的离线训练链路中,无需进行过多的适配。在中小规模训练 / 微调 LLaMA-7b 和 LLaMA-13b 的场景,Megatron-LLaMA 能够轻松达到业界领先的 54% 及以上的硬件利用率(MFU)。
Megatron-LLaMA 的反向流程优化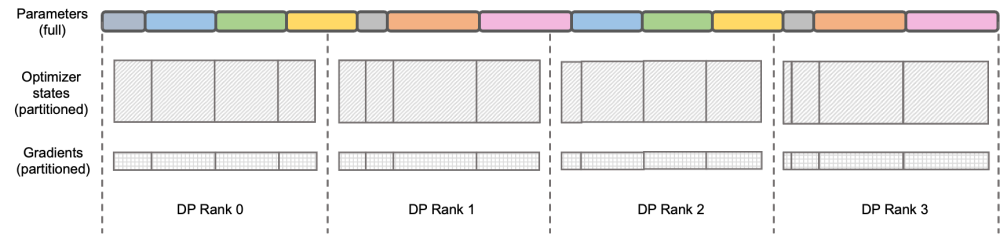 图示:DeepSpeed ZeRO Stage-2
图示:DeepSpeed ZeRO Stage-2
DeepSpeed ZeRO 是微软推出的一套分布式训练框架,其中提出的技术对很多后来的框架都有非常深远的影响。DeepSpeed ZeRO Stage-2(后文简称 ZeRO-2)是该框架中一项节约显存占用且不增加额外计算量和通信量的技术。如上图所示,由于计算需要,每个 Rank 都需要拥有全部的参数。但对于优化器状态而言,每个 Rank 只负责其中的一部分即可,不必所有 Rank 同时执行完全重复的操作。于是 ZeRO-2 提出将优化器状态均匀地切分在每个 Rank 上(注意,这里并不需要保证每个变量被均分或完整保留在某个 Rank 上),每个 Rank 在训练进程中只负责对应部分的优化器状态和模型参数的更新。在这种设定下,梯度也可以按此方式进行切分。默认情况下,ZeRO-2 在反向时在所有 Rank 间使用 Reduce 方式聚合梯度,而后每个 Rank 只需要保留自身所负责的参数的部分,既消除了冗余的重复计算,又降低了显存占用。
Megatron-LM DistributedOptimizer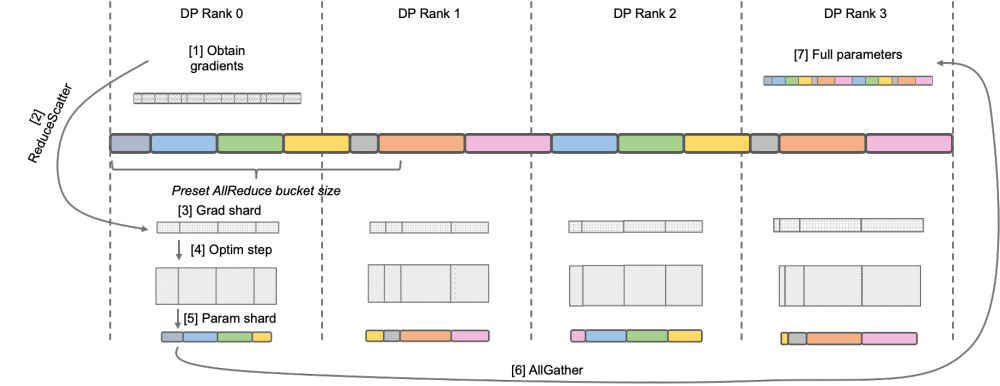 原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。
原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。 
Megatron-LLaMA OverlappedDistributedOptimizer
为了解决这一问题,Megatron-LLaMA 改进了原生 Megatron-LM 的 DistributedOptimizer,使其梯度通信的算子能够可以和计算相并行。特别的,相比于 ZeRO 的实现,Megatron-LLaMA 在并行的前提下,通过巧妙的优化优化器分区策略,使用了更具有具有扩展性的集合通信方式来提升扩展性。OverlappedDistributedOptimizer 的主要设计保证了如下几点:a) 单一集合通信算子数据量足够大,充分利用通信带宽;b) 新切分方式所需通信数据量应等于数据并行所需的最小通信数据量;c) 完整参数或梯度与切分后的参数或梯度的转化过程中,不能引入过多显存拷贝。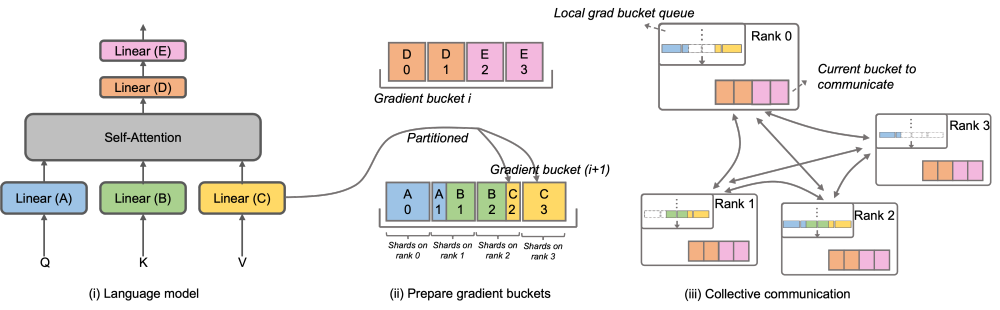
具体而言,Megatron-LLaMA 改进了 DistributedOptimizer 的机制,提出了 OverlappedDistributedOptimizer,用于结合新的切分方式优化训练中的反向流程。如上图所示,在 OverlappedDistributedOptimizer 初始化时,会预先给所有参数分配其所属的 Bucket。Bucket 中的参数是完整的,一个参数仅属于一个 Bucket,一个 Bucket 中可能有多个参数。逻辑上,每个 Bucket 将会被连续等分成 P(P 为数据并行组的数量)等份,数据并行组中的每个 Rank 负责其中的一份。 Bucket 被放置在一个本地队列(Local grad bucket queue)中,从而保证通信顺序。在训练计算的同时,数据并行组间以 Bucket 为单位,通过集合通讯交换各自需要的梯度。Megatron-LLaMA 中 Bucket 的实现尽可能采用了地址索引,只在有需要值更改时才新分配空间,避免了显存浪费。 上述的设计,再结合大量的工程优化,使得在大规模训练时,Megatron-LLaMA 可以很充分地使用硬件,实现了比原生 Megatron-LM 更好的加速。从32张A100卡扩展到512张A100卡的训练,Megatron-LLaMA在常用混部的网络环境中仍然能够取得0.85的扩展比。
Megatron-LLaMA 的未来计划Megatron-LLaMA 是由淘天集团和爱橙科技共同开源并提供后续维护支持的训练框架,在内部已有广泛的应用。随着越来越多的开发者涌入 LLaMA 的开源社区并贡献可以相互借鉴的经验,相信未来在训练框架层面会有更多的挑战和机会。Megatron-LLaMA 将会紧密关注社区的发展,并与广大开发者共同推进以下方向: 自适应最优配置选择 - 更多模型结构或局部设计改动的支持
在更多不同类硬件环境下的极致性能训练解决方案
项目地址:https://github.com/alibaba/Megatron-LLaMA




























