







淘天集团和爱橙科技于9月12日正式发布了开源的大模型训练框架——Megatron-LLaMA。该框架的目标是使技术开发者能够更方便地提升大语言模型的训练性能,降低训练成本,并与LLaMA社区保持兼容性。测试结果显示,在32卡训练上,与在HuggingFace上直接获取的代码版本相比,Megatron-LLaMA能够实现176%的加速;在大规模训练上,Megatron-LLaMA几乎线性扩展,且对网络不稳定表现出较高的容忍度。目前,Megatron-LLaMA已在开源社区上线
开源地址:https://github.com/alibaba/megatron-llama
大语言模型的卓越表现一次又一次地超出了人们的想象。在过去几个月里,LLaMA和LLaMA2向开源社区全面开放,为那些想要训练自己的大语言模型的人们提供了一个很好的选择。在开源社区中,已经有很多基于LLaMA开发的模型,包括续训/SFT(如Alpaca、Vicuna、WizardLM、Platypus、StableBegula、Orca、OpenBuddy、Linly、Ziya等)和从零开始训练(如Baichuan、QWen、InternLM、OpenLLaMA)的工作。这些工作不仅在各种大模型能力客观评测榜单上表现出色,同时也展示了在长文本理解、长文本生成、代码编写、数学求解等实际应用场景中的出色性能。此外,业界还出现了许多有趣的产品,例如LLaMA结合Whisper的语音聊天机器人、LLaMA结合Stable Diffusion的绘画软件,以及医学/法律领域的辅助咨询机器人等
尽管从 HuggingFace 上可以拿到 LLaMA 的模型代码,但用自己的数据训一个 LLaMA 模型对个人用户或中小型组织并不是一件低成本且简单的工作。大模型的体积和数据的规模,使得在普通的计算资源上无法完成有效的训练,算力和成本成为严重的瓶颈。Megatron-LM 社区的用户在这方面的诉求非常急迫。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
淘天集团和爱橙科技在大模型应用上有着非常广阔应用场景,在大模型的高效训练上进行了非常多的投入。LLaMA 的问世,在数据处理、模型设计、微调及强化学习反馈调整等方面都给予了包括淘天集团和爱橙科技在内的许多公司非常多的启示,也助力业务应用场景取得了新的突破。因此,为了回馈整个 LLaMA 开源社区、促进中文预训练大模型开源社区的发展,让开发者们能够更方便地提升大语言模型的训练性能,降低训练成本,淘天集团联合爱橙科技将部分内部优化技术开源,发布 Megatron-LLaMA,期望与每一位合作伙伴共建 Megatron 及 LLaMA 生态。
Megatron-LLaMA 提供了一套标准的 Megatron-LM 实现的 LLaMA,并提供了与 HuggingFace 格式自由切换的工具,方便与社区生态工具兼容。Megatron-LLaMA 重新设计了 Megatron-LM 的反向流程,使得无论在节点数较少需要开较大梯度聚合(Gradient Accumulation, GA)、或是节点数较多必须使用小 GA 的场景,都能够取得卓越的训练性能。
- 在 32 卡训练上,相比 HuggingFace 上直接获得的代码版本,Megatron-LLaMA 能够取得 176% 的加速;即便是采用 DeepSpeed 及 FlashAttention 优化过的版本,Megatron-LLaMA 仍然能减少至少 19% 的训练时间。
- 在大规模的训练上,Megatron-LLaMA 相比较 32 卡拥有着几乎线性的扩展性。例如使用 512 张 A100 复现 LLaMA-13B 的训练,Megatron-LLaMA 的反向机制相对于原生 Megatron-LM 的 DistributedOptimizer 能够节约至少两天的时间,且没有任何精度损失。
- Megatron-LLaMA 对网络不稳定表现出高容忍度。即便是在现在性价比较高的 4x200Gbps 通信带宽的 8xA100-80GB 训练集群(这种环境通常是混部环境,网络只能使用一半的带宽,网络带宽是严重的瓶颈,但租用价格相对低廉)上,Megatron-LLaMA 仍然能取得 0.85 的线性扩展能力,然而在这个指标上 Megatron-LM 仅能达到不足 0.7。
Megatron-LM 技术带来的高性能 LLaMA 训练机会
LLaMA是目前大语言模型开源社区中一项重要的工作。LLaMA在LLM的结构中引入了BPE字符编码、RoPE位置编码、SwiGLU激活函数、RMSNorm正则化以及Untied Embedding等优化技术,在许多客观和主观评测中取得了卓越的效果。LLaMA提供了7B、13B、30B、65B/70B的版本,适用于各类大模型需求的场景,也受到广大开发者的青睐。和许多其他开源大模型一样,由于官方只提供了推理版的代码,如何以最低成本开展高效训练,并没有一个标准的范式
Megatron-LM 是一种优雅的高性能训练解决方案。Megatron-LM 中提供了张量并行(Tensor Parallel,TP,把大乘法分配到多张卡并行计算)、流水线并行(Pipeline Parallel,PP,把模型不同层分配到不同卡处理)、序列并行(Sequence Parallel, SP,序列的不同部分由不同卡处理,节约显存)、DistributedOptimizer 优化(类似 DeepSpeed Zero Stage-2,切分梯度和优化器参数至所有计算节点)等技术,能够显著减少显存占用并提升 GPU 利用率。Megatron-LM 运营着一个活跃的开源社区,持续有新的优化技术、功能设计合并进框架中。
然而,开发基于Megatron-LM并不简单,特别是在昂贵的多卡机器上进行调试和功能验证更是十分昂贵的。Megatron-LLaMA首先提供了一套基于Megatron-LM框架实现的LLaMA训练代码,支持各种规模的模型版本,并且可以简单地适配支持LLaMA的各种变种,包括直接支持HuggingFace格式的Tokenizer。因此,Megatron-LLaMA可以轻松应用于现有的离线训练链路中,无需进行过多的适配。在中小规模训练/微调LLaMA-7b和LLaMA-13b的场景中,Megatron-LLaMA能够轻松达到业界领先的54%以上的硬件利用率(MFU)
Megatron-LLaMA 的反向流程优化
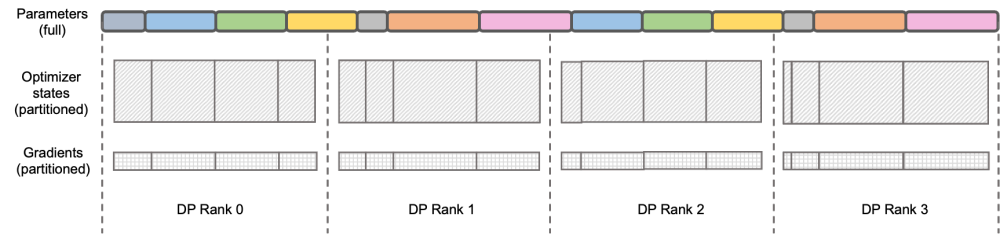
需要重新书写的内容是:图示:DeepSpeed ZeRO 阶段-2
DeepSpeed ZeRO 是微软推出的一套分布式训练框架,其中提出的技术对很多后来的框架都有非常深远的影响。DeepSpeed ZeRO Stage-2(后文简称 ZeRO-2)是该框架中一项节约显存占用且不增加额外计算量和通信量的技术。如上图所示,由于计算需要,每个 Rank 都需要拥有全部的参数。但对于优化器状态而言,每个 Rank 只负责其中的一部分即可,不必所有 Rank 同时执行完全重复的操作。于是 ZeRO-2 提出将优化器状态均匀地切分在每个 Rank 上(注意,这里并不需要保证每个变量被均分或完整保留在某个 Rank 上),每个 Rank 在训练进程中只负责对应部分的优化器状态和模型参数的更新。在这种设定下,梯度也可以按此方式进行切分。默认情况下,ZeRO-2 在反向时在所有 Rank 间使用 Reduce 方式聚合梯度,而后每个 Rank 只需要保留自身所负责的参数的部分,既消除了冗余的重复计算,又降低了显存占用。
Megatron-LM DistributedOptimizer
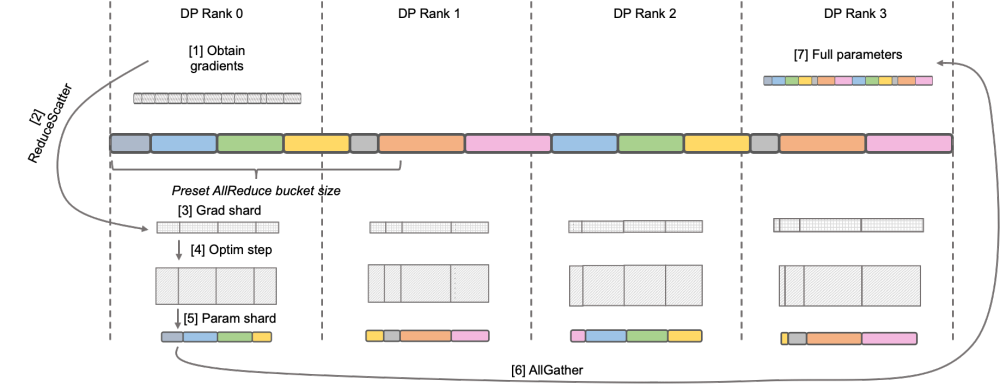
原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切
Megatron-LLaMA OverlappedDistributedOptimizer
为了解决这一问题,Megatron-LLaMA 改进了原生 Megatron-LM 的 DistributedOptimizer,使其梯度通信的算子能够可以和计算相并行。特别的,相比于 ZeRO 的实现,Megatron-LLaMA 在并行的前提下,通过巧妙的优化优化器分区策略,使用了更具有具有扩展性的集合通信方式来提升扩展性。OverlappedDistributedOptimizer 的主要设计保证了如下几点:a) 单一集合通信算子数据量足够大,充分利用通信带宽;b) 新切分方式所需通信数据量应等于数据并行所需的最小通信数据量;c) 完整参数或梯度与切分后的参数或梯度的转化过程中,不能引入过多显存拷贝。
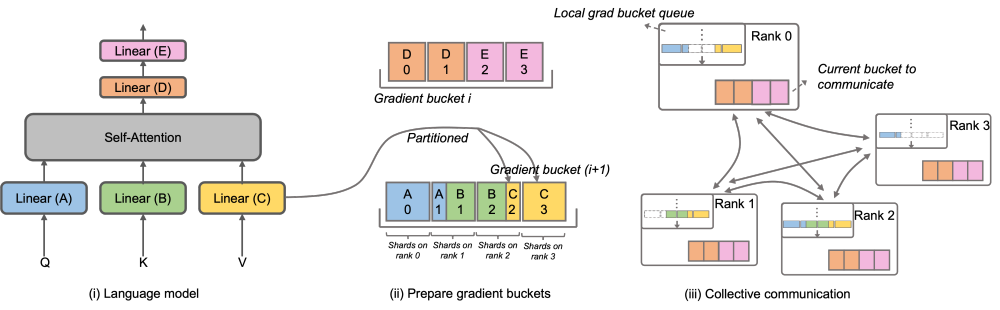
具体而言,Megatron-LLaMA对DistributedOptimizer进行了改进,提出了OverlappedDistributedOptimizer,用于在训练的反向流程中结合新的切分方式进行优化。如图所示,在初始化OverlappedDistributedOptimizer时,会预先为所有参数分配它们所属的Bucket。每个Bucket中的参数是完整的,一个参数只属于一个Bucket,一个Bucket中可能有多个参数。在逻辑上,每个Bucket将被连续地等分为P份(P为数据并行组的数量),数据并行组中的每个Rank将负责其中的一份
Bucket被放置在本地梯度桶队列中,以确保通信顺序。在进行训练计算的同时,数据并行组之间以桶为单位,通过集合通信交换各自所需的梯度。在Megatron-LLaMA中,Bucket的实现尽可能地采用了地址索引,只有在需要更改值时才会分配新的空间,以避免显存浪费
通过结合大量的工程优化,上述设计使得在大规模训练时,Megatron-LLaMA能够充分利用硬件,实现比原生的Megatron-LM更好的加速效果。在常用的网络环境中,将训练规模从32张A100卡扩展到512张A100卡,Megatron-LLaMA仍能够达到0.85的扩展比
Megatron-LLaMA 的未来计划
Megatron-LLaMA是一个由淘天集团和爱橙科技共同开源并提供后续维护支持的训练框架,在内部已经得到广泛应用。随着越来越多的开发者加入LLaMA的开源社区并贡献可供互相借鉴的经验,相信未来在训练框架层面会面临更多挑战和机会。Megatron-LLaMA将密切关注社区的发展,并与广大开发者共同推动以下方向的发展:
- 自适应最优配置选择
- 更多模型结构或局部设计改动的支持
- 在更多不同类硬件环境下的极致性能训练解决方案
项目地址:https://github.com/alibaba/Megatron-LLaMA





























