







在《圣经》中有一个巴别塔的故事,说是人类联合起来计划兴建一座高塔,希望能通往天堂,但神扰乱了人类的语言,计划也就因此失败。到了今天,AI 技术有望拆除人类语言之间的藩篱,帮助人类造出文明的巴别塔。
近日,Meta 的一项研究向这个方面迈出了重要一步,他们将新提出的方法称为 Massively Multilingual Speech(超多语言语音 / MMS),其以《圣经》作为训练数据的一部分,得到了以下成果:
- 在 1107 种语言上用 wave2vec 2.0 训练得到了一个有 10 亿参数的多语言语音识别模型,相比于 OpenAI 的 Whisper 模型,其错误率降低了 50% 以上。
- 单个音频合成模型就支持这 1107 种语言的文本转语音(TTS)。
- 开发了一个能够辨别 4017 种语言的语言辨识分类器。
对于很多罕见语言的数据稀少问题,Meta 是如何解决的呢?他们采用的方法很有意思,即采用宗教的语料库,因为像是《圣经》这样的语料具有最「对齐的」语音数据。尽管这个数据集偏向宗教内容并且主要是男性声音,但其论文表明这个模型在其它领域以及使用女声时也表现优良。这是基础模型的涌现行为,着实让人惊叹。而更让人惊叹的是,Meta 将新开发的模型(语音识别、TTS 和语言辨识)都免费发布出来了!
- 模型下载:https://github.com/facebookresearch/fairseq/tree/main/examples/mms
- 论文地址:https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
新提出的方法
为了打造出一个能识别千言万语的语音模型,首要的挑战是收集各种语言的音频数据,因为现目前已有的最大语音数据集也只有至多 100 种语言。为了克服这个问题,Meta 的研究者使用了宗教文本,比如《圣经》,这些文本已被翻译成了许多不同语言,并且那些译本都已被广泛研究过。这些译本都有人们用不同语言阅读的录音,并且这些音频也是公开可用的。使用这些音频,研究者创建了一个数据集,其中包含人们用 1100 种语言阅读《新约》的音频,其中每种语言的平均音频长度为 32 小时。
然后他们又纳入了基督教的其它许多读物的无标注录音,从而将可用语言数量增加到了 4000 以上。尽管这个数据集领域单一,并且大都是男声,但分析结果表明 Meta 新开发的模型在女声上表现也同样优良,并且该模型也不会格外偏向于产生更宗教式的语言。研究者在博客中表示,这主要是得益于他们使用的 Connectionist Temporal Classification(连接主义时间分类)方法,相比于大型语言模型(LLM)或序列到序列语音识别模型,这种方法要远远更为受限。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
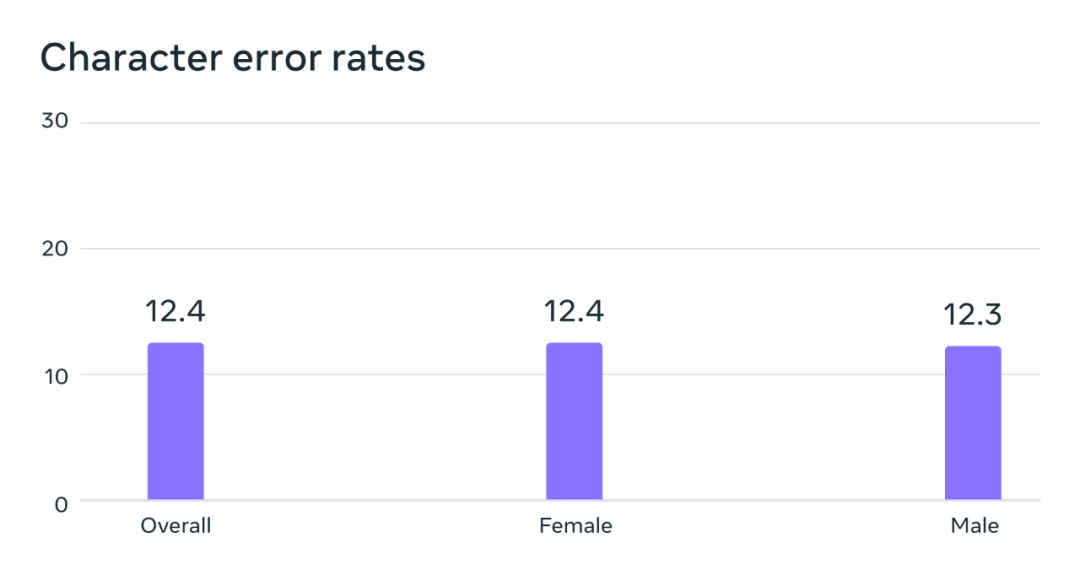
潜在的性别偏见情况分析。在 FLEURS 基准上,这个在超多语言语音(MMS)数据集上训练的自动语音识别模型在男声和女声上的错误率是差不多的。
为了提升数据质量,使之能被机器学习算法使用,他们还采用了一些预处理方法。首先,他们在现有的 100 多种语言的数据上训练了一个对齐模型,然后再搭配使用了一个高效的强制对齐算法,该算法可处理 20 分钟以上的超长录音。之后,经过多轮对齐过程,最终再执行一步交叉验证过滤,基于模型准确度移除可能未对齐的数据。为了方便其他研究者创建新的语音数据集,Meta 将该对齐算法添加到了 PyTorch 并放出了该对齐模型。
要训练出普遍可用的监督式语音识别模型,每种语言仅有 32 小时的数据可不够。因此,他们的模型是基于 wav2vec 2.0 开发的,这是他们之前在自监督语音表征学习上的研究成果,能极大减少训练所需的有标注数据量。具体来说,研究者使用 1400 多种语言的大约 50 万小时语音数据训练了一个自监督模型 —— 这个语言数量已经超过之前任何研究的五倍以上了。然后,基于具体的语音任务(比如多语言语音识别或语言辨识),研究者再对所得模型进行微调。
结果
研究者在一些已有基准上评估了新开发的模型。
其多语言语音识别模型的训练使用了含 10 亿参数的 wav2vec 2.0 模型,训练数据集包含 1100 多种语言。随着语言数量增加,模型性能确实会下降,但下降幅度非常小:当语言数量从 61 种增加到 1107 种时,字符错误率仅上升了 0.4%,但语言覆盖范围却增加了 18 倍以上。
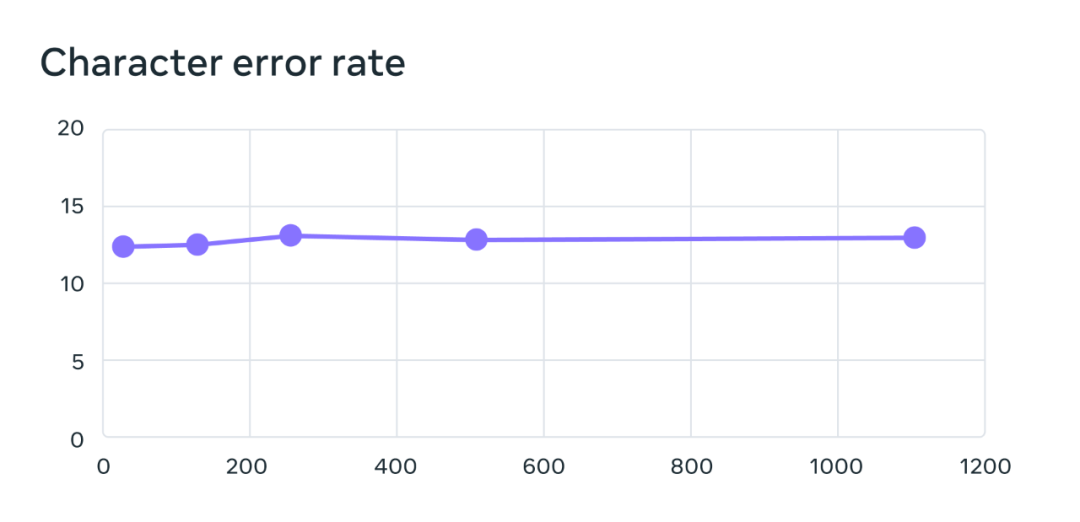
在 61 种 FLEURS 语言的基准测试上,随语言数量增长的字符错误率变化情况,错误率越高,模型越差。
通过对比 OpenAI 的 Whisper 模型,研究者发现他们的模型的词错误率仅有 Whisper 的一半,而同时新模型支持的语言数量还多 11 倍。这个结果足以表明新方法的卓越能力。
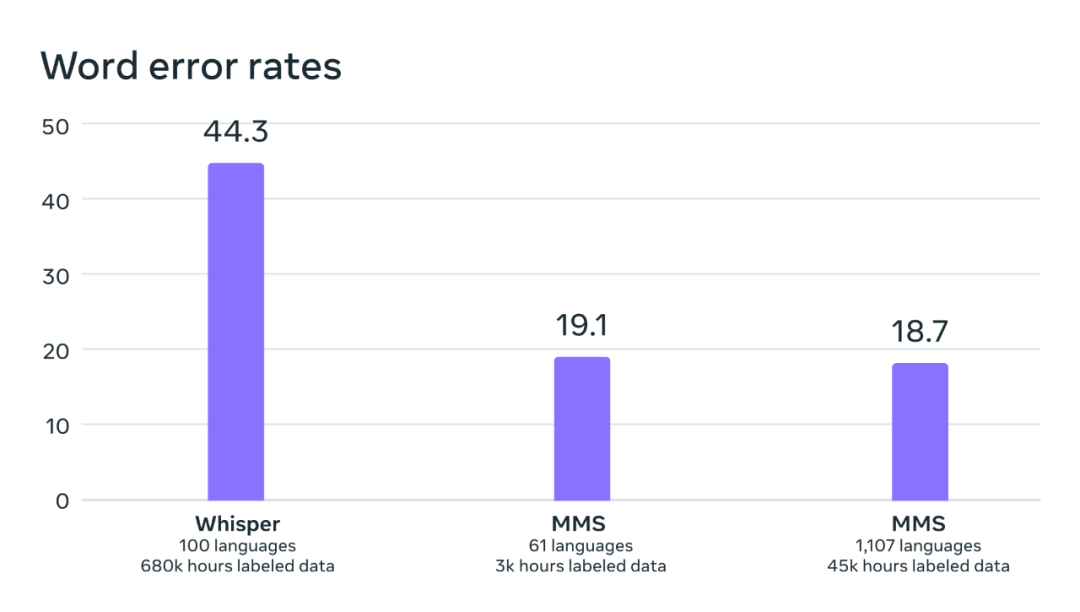
在可直接比较的 54 种 FLEURS 语言的基准测试上,OpenAI Whisper 与 MMS 的词错误率对比。
接下来,使用之前已有的数据集(如 FLEURS 和 CommonVoice)和新数据集,Meta 的研究者还训练了一个语言辨识(LID)模型,并在 FLEURS LID 任务上进行了评估。结果表明,新模型不仅表现很棒,而且支持的语言数量也增加了 40 倍。
之前的研究在 VoxLingua-107 基准上也仅支持 100 多种语言,而 MMS 支持超过 4000 种语言。
另外 Meta 还构建了一个支持 1100 种语言的文本转语音系统。当前文本转语音模型的训练数据通常是来自单个说话人的语音语料。MMS 数据的一个局限性是许多语言都只有少量说话人,甚至往往只有一个说话人。但是,在构建文本转语音系统时,这却成了一个优势,于是 Meta 就顺便造了一个支持 1100 多种语言的 TTS 系统。研究者表示,这些系统生成的语音质量其实相当好,下面给出了几个例子。
约鲁巴语、伊洛科语和迈蒂利语的 MMS 文本转语音模型演示。
尽管如此,研究者表示 AI 技术都仍不完美,MMS 也是如此。举个例子,MMS 在语音转文本时可能错误转录选定的词或短语。这可能导致输出结果中出现冒犯性和 / 或不准确的语言。研究者强调了与 AI 社区合作共同进行负责任开发的重要性。
用单个模型支持千言万语的价值
世界上有许多语言濒临灭绝,而当前的语音识别和语音生成技术的局限性只会进一步加速这一趋势。研究者在博客中设想:也许技术能鼓励人们留存自己的语言,因为有了好的技术后,他们完全可以使用自己喜欢的语言来获取信息和使用技术。
他们相信 MMS 项目是朝这个方向迈出的重要一步。他们还表示这个项目还将继续开发,未来还将支持更多语言,甚至还会解决方言和口音的难题。




























