







技术背景
在前面一篇博客中我们介绍了一些用python3处理表格数据的方法,其中重点包含了vaex这样一个大规模数据处理的方案。这个数据处理的方案是基于内存映射(memory map)的技术,通过创建内存映射文件来避免在内存中直接加载源数据而导致的大规模内存占用问题,这使得我们可以在本地电脑内存规模并不是很大的条件下对大规模的数据进行处理。在python 3中,存在一个名为mmap的库,可用于直接创建内存映射文件。
用tracemalloc跟踪python程序内存占用
这里我们希望能够对比内存映射技术的实际内存占用,因此我们需要引入一个基于python的内存追踪工具:tracemalloc。我们先举一个简单的例子,即创建一个随机数组,然后观察该数组所占用的内存大小
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)输出结果如下:
[dechin@dechin-manjaro mmap]$ python3 tracem.py [Top 10]tracem.py:8: size=78.2 KiB, count=2, average=39.1 KiB
假如我们是使用top指令来直接检测内存的话,毫无疑问占比内存最高的还是谷歌浏览器:
top - 10:04:08 up 6 days, 15:18, 5 users, load average: 0.23, 0.33, 0.27
任务: 309 total, 1 running, 264 sleeping, 23 stopped, 21 zombie
%Cpu(s): 0.6 us, 0.2 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 39913.6 total, 25450.8 free, 1875.7 used, 12587.1 buff/cache
MiB Swap: 16384.0 total, 16384.0 free, 0.0 used. 36775.8 avail Mem
进程号 USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
286734 dechin 20 0 36.6g 175832 117544 S 4.0 0.4 1:02.32 chromium立即学习“Python免费学习笔记(深入)”;
因此根据进程号来追踪子进程的内存占用才是使用tracemalloc的一个重点,这里我们发现一个10000大小的numpy矢量的内存占用约为39.1 KiB,这其实是符合我们的预期的:
In [3]: 39.1*1024/4
Out[3]: 10009.6
因为这几乎就是10000个float32浮点数的内存占用大小,这表明所有的元素都已经存储在内存中。
用tracemalloc追踪内存变化
在上面一个章节中我们介绍了snapshot内存快照的使用方法,那么我们很容易可以想到,通过“拍摄”两张内存快照,然后对比一下快照中的变化,不就可以得到内存变化的大小么?接下来做一个简单尝试:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)执行结果如下:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[Top 10 differences]
comp_tracem.py:9: size=78.2 KiB (+78.2 KiB), count=2 (+2), average=39.1 KiB
可以看到这个快照前后的平均内存大小差异就是在39.1 KiB,假如我们把矢量的维度改为1000000:
length=1000000
再执行一遍看看效果:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[Top 10 differences]
comp_tracem.py:9: size=7813 KiB (+7813 KiB), count=2 (+2), average=3906 KiB
我们发现结果是3906,相当于被放大了100倍,是比较符合预期的。当然如果我们仔细去算一下:
In [4]: 3906*1024/4
Out[4]: 999936.0
我们发现这里面并不完全是float32的类型,相比于完全的float32类型缺失了一部分内存大小,这里怀疑是否是中间产生了一些0,被自动的压缩了大小?不过这个问题并不是我们所要重点关注的,我们继续向下测试内存的变化曲线。
内存占用曲线
延续前面两个章节的内容,我们主要测试一下不同维度的随机数组所需要占用的内存空间,在上述代码模块的基础上增加了一个for循环:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')画出来的效果图如下所示:
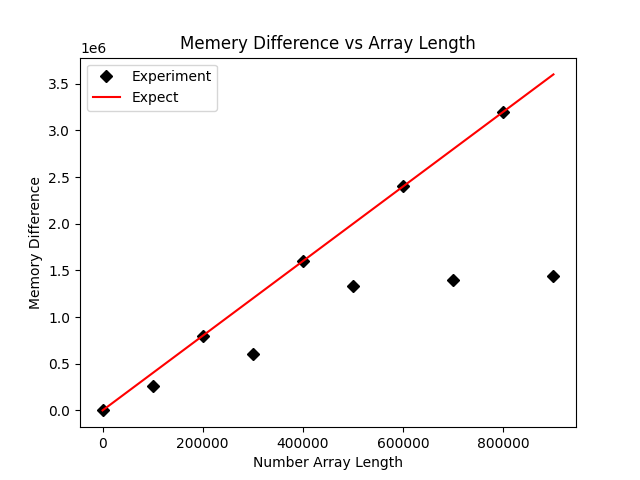

这里我们又发现,虽然大部分情况下是符合内存占用预期的,但有很多个点比预期占用的要少,我们怀疑是因为存在0元素,因此稍微修改了一下代码,在原代码的基础上增加了一个操作来尽可能的避免0的出现:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')经过更新后,得到的结果图如下所示:
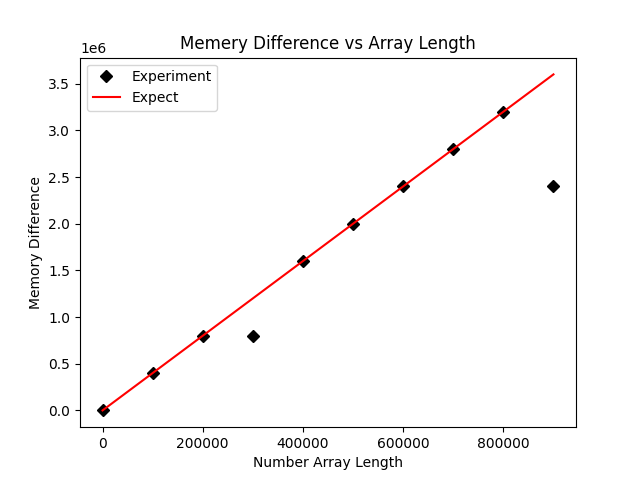
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
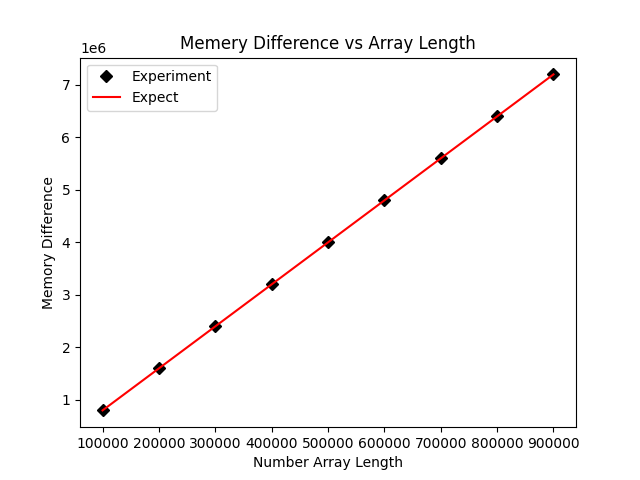
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
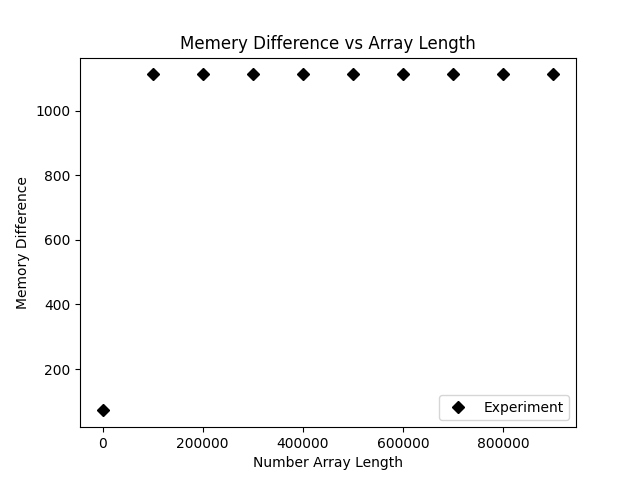
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。





























