







这篇文章主要介绍了c#基于正则表达式抓取a标签链接和innerhtml的方法,结合实例形式分析了c#使用正则表达式进行页面元素的匹配与抓取相关操作技巧,需要的朋友可以参考下
本文实例讲述了C#基于正则表达式抓取a标签链接和innerhtml的方法。分享给大家供大家参考,具体如下:
//读取网页html
string text = File.ReadAllText(Environment.CurrentDirectory + "//test.txt", Encoding.GetEncoding("gb2312"));
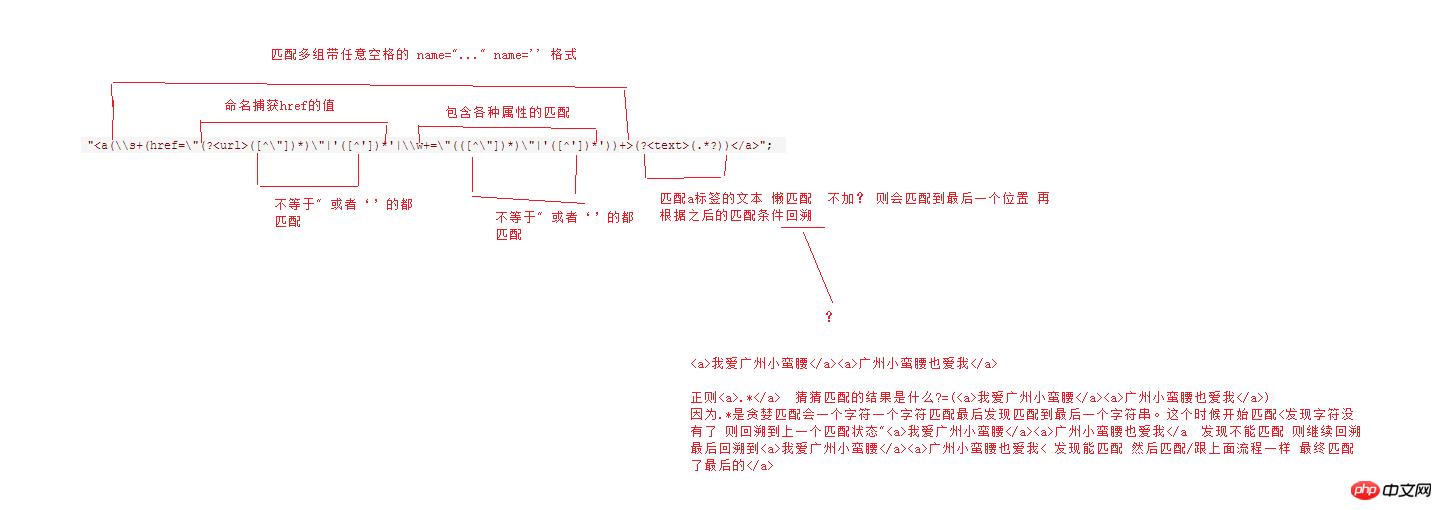
string prttern = "<a(\s+(href="(?<url>([^"])*)"|'([^'])*'|\w+="(([^"])*)"|'([^'])*'))+>(?<text>(.*?))</a>";
var maths = Regex.Matches(text, prttern);
//抓取出来写入的文件
using (FileStream w = new FileStream(Environment.CurrentDirectory + "//wirter.txt", FileMode.Create))
{
for (int i = 0; i < maths.Count; i++)
{
byte[] bs = Encoding.UTF8.GetBytes(string.Format("链接地址:{0}, innerhtml:{1}", maths[i].Groups["url"].Value,
maths[i].Groups["text"].Value) + "
");
w.Write(bs, 0, bs.Length);
Console.WriteLine();
}
}
Console.ReadKey();图解正则

朋友需要截取img标签的src 和data-url 跟上面差不多。。顺便附上
立即学习“前端免费学习笔记(深入)”;
string text =File.ReadAllText(Environment.CurrentDirectory + "//test.txt", Encoding.GetEncoding("gb2312"));
string prttern = "<img(\s*(src="(?<src>[^"]*?)"|data-url="(?<dataurl>[^"]*?)"|[-\w]+="[^"]*?"))*\s*/>";
var maths = Regex.Matches(text, prttern);
//抓取出来写入的文件
using (FileStream w = new FileStream(Environment.CurrentDirectory + "//wirter.txt", FileMode.Create))
{
for (int i = 0; i < maths.Count; i++)
{
byte[] bs = Encoding.UTF8.GetBytes(string.Format("图片src:{0}, 图片data-url:{1}", maths[i].Groups["src"].Value,
maths[i].Groups["dataurl"].Value) + "
");
w.Write(bs, 0, bs.Length);
Console.WriteLine();
}
} 




























