







一. 前言
在前面的几篇文章中我介绍了如何通过Python分析源代码来爬取博客、维基百科InfoBox和图片,其文章链接如下:
[python学习] 简单爬取维基百科程序语言消息盒
[Python学习] 简单网络爬虫抓取博客文章及思想介绍
[python学习] 简单爬取图片网站图库中图片
其中核心代码如下:
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=).*?(?= )'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'(.*?)'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个url 输出结果如下:
>>> CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台 登录 >>>
图片下载的核心代码如下:
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename) 但是上面这种分析HTML来爬取网站内容的方法存在很多弊端,譬如:
1.正则表达式被HTML源码所约束,而不是取决于更抽象的结构;网页结构中很小的改动可能会导致程序的中断。
2.程序需要根据实际HTML源码分析内容,可能会遇到字符实体如&之类的HTML特性,需要指定处理如、图标超链接、下标等不同内容。
3.正则表达式并不是完全可读的,更复杂的HTML代码和查询表达式会变得很乱。
正如《Python基础教程(第2版)》采用两种解决方案:第一个是使用Tidy(Python库)的程序和XHTML解析;第二个是使用BeautifulSoup库。
立即学习“Python免费学习笔记(深入)”;
二. 安装及介绍Beautiful Soup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
正如书中所说“那些糟糕的网页不是你写的,你只是试图从中获得一些数据。现在你不用关心HTML是什么样子的,解析器帮你实现”。
下载地址:
http://www.php.cn/
http://www.php.cn/
安装过程如下图所示:python setup.py install

具体使用方法建议参照中文:
http://www.php.cn/
其中BeautifulSoup的用法简单讲解下,使用“爱丽丝梦游仙境”的官方例子:
#!/usr/bin/python # -*- coding: utf-8 -*- from bs4 import BeautifulSoup html_doc = """The Dormouse's story The Dormouse's story
Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well.
...
""" #获取BeautifulSoup对象并按标准缩进格式输出 soup = BeautifulSoup(html_doc) print(soup.prettify())
输出内容按照标准的缩进格式的结构输出如下:
The Dormouse's story The Dormouse's story
Once upon a time there were three little sisters; and their names were Elsie , Lacie and Tillie ; and they lived at the bottom of a well.
...
下面是BeautifulSoup库简单快速入门介绍:(参考:官方文档)
'''获取title值''' print soup.title #The Dormouse's story print soup.title.name # title print unicode(soup.title.string) # The Dormouse's story '''获取值''' print soup.p #
The Dormouse's story
print soup.a # Elsie '''从文档中找到的所有标签链接''' print soup.find_all('a') # [Elsie, # Lacie, # Tillie] for link in soup.find_all('a'): print(link.get('href')) # http://www.php.cn/ # http://www.php.cn/ # http://www.php.cn/ print soup.find(id='link3') # Tillie
如果想获取文章中所有文字内容,代码如下:
'''从文档中获取所有文字内容''' print soup.get_text() # The Dormouse's story # # The Dormouse's story # # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # # ...
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。

其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
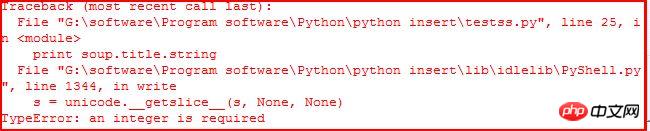
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python # -*- coding: utf-8 -*- from bs4 import BeautifulSoup html = """The Dormouse's story The Dormouse's story
""" soup = BeautifulSoup(html) tag = soup.p print tag #The Dormouse's story
print type(tag) #print tag.name # p 标签名字 print tag['class'] # [u'title'] print tag.attrs # {u'class': [u'title'], u'id': u'start'}
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。

print unicode(tag.string) # The Dormouse's story print type(tag.string) #tag.string.replace_with("No longer bold") print tag # No longer bold
这是获取“ The Dormouse's story
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "" soup = BeautifulSoup(markup) comment = soup.b.string print type(comment) #print unicode(comment) # Hey, buddy. Want to buy a used parser?
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
通过tag的 .children 生成器,可以对tag的子节点进行循环:
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是
兄弟节点:因为标签和
在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为标签在同级节点中是第一个。同理
介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。
(By:Eastmount 2015-3-25 下午6点
http://www.php.cn/)





























