







???根据论文内容,本文的核心贡献点可以归纳为以下几个方面:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

总结: 本文最主要的贡献在于将一个先进的深度学习检测方案(YOLOv7+ConSinGAN)成功地工程化,并落地于实际的工业生产线,系统地解决了从数据准备、模型选型到系统集成的一系列实际问题,具有很高的学术价值和工业应用价值。
博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8、v9、v10、11、v12、v13优化创新,轻松涨点和模型轻量化;2)目标检测、语义分割、OCR、分类等技术孵化,赋能智能制造,工业项目落地经验丰富;

原理介绍

论文:https://arxiv.org/pdf/2510.01914
摘要:传统工业元件的缺陷检测耗时费力,不仅给质检人员带来沉重负担,也使产品质量难以管控。本文针对工业广泛使用的双列直插式封装(DIP)元件,提出一种结合数码相机光学技术与深度学习模型的自动化缺陷检测系统。研究聚焦DIP两大常见缺陷类型:(1)表面缺陷;(2)引脚缺陷。针对缺陷样本图像匮乏给检测任务带来的挑战,采用ConSinGAN生成规模适中的数据集用于训练与测试。我们分别对四种YOLO模型(v3、v4、v7、v9)进行独立测试及ConSinGAN数据增强对比实验。结果表明,采用ConSinGAN增强的YOLOv7模型在检测精度(95.50%)与耗时(285毫秒)上均优于其他版本,且显著超越基于阈值的传统方法。此外,本研究还开发了数据采集与监视控制(SCADA)系统并构建相应传感器架构。该自动化缺陷检测方案可灵活拓展至多类型缺陷检测场景,对缺陷数据不足的情况具有良好适应性。
# =============================================================================# Automated Defect Detection for Mass-Produced Electronic Components# Based on YOLO Object Detection Models - 伪代码实现# =============================================================================import cv2import numpy as npimport torchimport yolov5 # 或其他YOLO版本class ElectronicComponentDefectDetector: def __init__(self, model_path, conf_threshold=0.5, iou_threshold=0.4): """ 初始化缺陷检测器 Args: model_path: 预训练的YOLO模型路径 conf_threshold: 置信度阈值 iou_threshold: IoU阈值用于NMS """ self.model = yolov5.load(model_path) self.model.conf = conf_threshold self.model.iou = iou_threshold self.defect_classes = ['short_circuit', 'open_circuit', 'solder_void', 'component_misalignment', 'crack', 'contamination'] def preprocess_image(self, image_path): """ 图像预处理 """ # 读取图像 image = cv2.imread(image_path) # 转换为RGB image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 图像增强 (可选) enhanced_image = self.image_enhancement(image_rgb) return enhanced_image def image_enhancement(self, image): """ 图像增强以提高检测精度 """ # 直方图均衡化 lab = cv2.cvtColor(image, cv2.COLOR_RGB2LAB) lab[:,:,0] = cv2.equalizeHist(lab[:,:,0]) enhanced = cv2.cvtColor(lab, cv2.COLOR_LAB2RGB) # 高斯模糊去噪 denoised = cv2.GaussianBlur(enhanced, (3,3), 0) return denoised def detect_defects(self, image_path): """ 执行缺陷检测 """ # 1. 图像预处理 processed_image = self.preprocess_image(image_path) # 2. YOLO模型推理 results = self.model(processed_image) # 3. 后处理 detections = results.pandas().xyxy[0] # 获取检测结果 # 4. 分析检测结果 defect_analysis = self.analyze_defects(detections) return detections, defect_analysis def analyze_defects(self, detections): """ 分析缺陷检测结果 """ analysis = { 'total_defects': len(detections), 'defect_types': {}, 'severity_level': 'PASS', 'defect_locations': [] } for _, detection in detections.iterrows(): defect_class = detection['class'] confidence = detection['confidence'] # 统计各类缺陷数量 if defect_class in analysis['defect_types']: analysis['defect_types'][defect_class] += 1 else: analysis['defect_types'][defect_class] = 1 # 记录缺陷位置 bbox = { 'xmin': detection['xmin'], 'ymin': detection['ymin'], 'xmax': detection['xmax'], 'ymax': detection['ymax'] } analysis['defect_locations'].append({ 'class': defect_class, 'confidence': confidence, 'bbox': bbox }) # 根据缺陷数量和类型确定严重程度 if analysis['total_defects'] > 3: analysis['severity_level'] = 'CRITICAL' elif analysis['total_defects'] > 0: analysis['severity_level'] = 'WARNING' return analysis def visualize_results(self, image_path, detections, save_path=None): """ 可视化检测结果 """ image = cv2.imread(image_path) for _, detection in detections.iterrows(): # 绘制边界框 xmin, ymin, xmax, ymax = int(detection['xmin']), int(detection['ymin']), \ int(detection['xmax']), int(detection['ymax']) # 根据缺陷类型选择颜色 color = self.get_defect_color(detection['class']) cv2.rectangle(image, (xmin, ymin), (xmax, ymax), color, 2) # 添加标签 label = f"{detection['name']}: {detection['confidence']:.2f}" cv2.putText(image, label, (xmin, ymin-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) if save_path: cv2.imwrite(save_path, image) return image def get_defect_color(self, defect_class): """ 根据缺陷类型返回对应的颜色 """ color_map = { 'short_circuit': (0, 0, 255), # 红色 - 严重缺陷 'open_circuit': (0, 165, 255), # 橙色 - 严重缺陷 'crack': (0, 255, 255), # 黄色 - 中等缺陷 'solder_void': (255, 255, 0), # 青色 - 轻微缺陷 'component_misalignment': (255, 0, 0), # 蓝色 - 轻微缺陷 'contamination': (128, 0, 128) # 紫色 - 轻微缺陷 } return color_map.get(defect_class, (255, 255, 255))# =============================================================================# 训练过程的伪代码# =============================================================================def train_defect_detection_model(): """ 训练YOLO缺陷检测模型 """ # 1. 数据准备 dataset_config = { 'train': 'dataset/train/images', 'val': 'dataset/val/images', 'test': 'dataset/test/images', 'nc': 6, # 缺陷类别数量 'names': ['short_circuit', 'open_circuit', 'solder_void', 'component_misalignment', 'crack', 'contamination'] } # 2. 模型配置 model_config = { 'model_type': 'yolov5s', # 可选择yolov5n, yolov5s, yolov5m, yolov5l, yolov5x 'img_size': 640, 'batch_size': 16, 'epochs': 100, 'learning_rate': 0.01, 'optimizer': 'SGD', 'momentum': 0.937, 'weight_decay': 0.0005 } # 3. 数据增强配置 augmentation_config = { 'hsv_h': 0.015, # 色调增强 'hsv_s': 0.7, # 饱和度增强 'hsv_v': 0.4, # 明度增强 'rotate': 10, # 旋转角度 'translate': 0.1, # 平移 'scale': 0.5, # 缩放 'shear': 0.0, # 剪切 'flipud': 0.0, # 上下翻转 'fliplr': 0.5, # 左右翻转 'mosaic': 1.0, # Mosaic数据增强 'mixup': 0.0 # Mixup数据增强 } # 4. 训练过程 for epoch in range(model_config['epochs']): # 训练阶段 model.train() for batch_idx, (images, targets) in enumerate(train_loader): # 前向传播 predictions = model(images) # 计算损失 loss = compute_loss(predictions, targets) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() # 记录训练指标 log_training_metrics(loss, batch_idx) # 验证阶段 model.eval() with torch.no_grad(): for images, targets in val_loader: predictions = model(images) # 计算验证指标 calculate_validation_metrics(predictions, targets) # 保存最佳模型 if is_best_model(current_metrics): save_checkpoint(model, epoch, current_metrics)# =============================================================================# 主程序# =============================================================================def main(): """ 主执行函数 """ # 初始化缺陷检测器 detector = ElectronicComponentDefectDetector( model_path='best_defect_detection_model.pt', conf_threshold=0.6, iou_threshold=0.45 ) # 批量处理电子组件图像 component_images = [ 'production_batch_001/component_001.jpg', 'production_batch_001/component_002.jpg', # ... 更多图像 ] results = [] for image_path in component_images: # 执行缺陷检测 detections, analysis = detector.detect_defects(image_path) # 可视化结果 result_image = detector.visualize_results( image_path, detections, save_path=f'results/{os.path.basename(image_path)}' ) # 保存检测结果 results.append({ 'image_path': image_path, 'analysis': analysis, 'defect_count': analysis['total_defects'], 'severity': analysis['severity_level'] }) # 打印检测结果 print(f"图像: {image_path}") print(f"缺陷数量: {analysis['total_defects']}") print(f"严重程度: {analysis['severity_level']}") print("---") # 生成检测报告 generate_inspection_report(results)def generate_inspection_report(results): """ 生成质量检测报告 """ total_components = len(results) defective_components = sum(1 for r in results if r['defect_count'] > 0) yield_rate = (total_components - defective_components) / total_components * 100 print(f"=== 质量检测报告 ===") print(f"总检测数量: {total_components}") print(f"缺陷产品数量: {defective_components}") print(f"良率: {yield_rate:.2f}%") # 统计各类缺陷 defect_statistics = {} for result in results: for defect_type, count in result['analysis']['defect_types'].items(): if defect_type in defect_statistics: defect_statistics[defect_type] += count else: defect_statistics[defect_type] = count print("缺陷类型统计:") for defect_type, count in defect_statistics.items(): print(f" {defect_type}: {count}")if __name__ == "__main__": main()1.介绍
据我们所知,本研究是首个探索基于深度学习的自动化DIP图像检测的工作。针对这种六边形元件的各检测面,我们提出了相应的质量控制缺陷检测方法。该系统并非独立运行,而是与自动化制造产线流程集成。因此,必须考虑前道工序的产出节拍,确保检测在指定时间框架内完成。
另一方面,自动化图像处理的主要挑战在于缺陷产品样本的稀缺。为扩充有限样本量,我们采用名为ConSinGAN的生成对抗网络模型[47][48]进行数据增强。ConSinGAN仅需单张图像即可构建模型,并能有效模拟生成图像中的缺陷特征,极大促进了检测模型的训练过程。而其他GAN变体(如DCGAN[49]或WGAN[50])则需要更多训练图像。本文的主要贡献如下:
• 基于YOLO模型设计缺陷DIP检测系统,提升检测质量; • 采用ConSinGAN生成DIP图像数据,增强YOLO模型训练效果; • 搭建实体产线及SCADA界面,验证方案在实际应用中的有效性; • 通过精度与检测时间指标,对比评估不同YOLO版本性能; • 相较于基于阈值的检测方法,采用ConSinGAN的YOLO模型将检测耗时降低909-948毫秒,其中YOLOv7+ConSinGAN方案达到95.50%的准确率; • 区别于既往研究仅关注检测模型,本方案在实践自动化机制中实现检测功能,并将检测时间纳入性能衡量指标。
本文后续章节安排如下:第二章阐述自动化缺陷检测系统架构、DIP缺陷类型及用于基线对比的阈值图像检测法;第三章详述数据预处理、YOLO模型及性能指标;第四章对比阈值检测法、基于深度学习的YOLOv3/v4/v7/v9模型及结合ConSinGAN方案在DIP缺陷检测中的仿真结果;第五章总结结论并展望未来工作。
2.自动化缺陷检测系统
该系统架构如图1所示,包含三个组成部分:1) 控制系统:由个人计算机(PC)与可编程逻辑控制器(PLC)设备构成。PC负责与成像设备交互并建立数据采集与监视控制(SCADA)系统,实现深度学习模型集成与数据分析功能。PLC则用于连接机械装备,控制各类执行动作,发送动作完成信号,并提供二次确认计数。2) 成像设备:包括工业相机、远心镜头及多种光源设备。成像设备通过以太网电缆(RJ45)与PC进行数据交互与传输。3) 机械装备:通过PLC人机界面进行控制,包含气动夹具、电磁推杆与电磁阀等执行机构。

A. 自动化机械结构
本系统设计用于检测工件的全部六个表面。每个检测面均在不同位置配备多组自动光学检测(AOI)单元,以最大限度减少不同表面受各类光源的干扰影响。图2展示了该系统的三维架构示意图,清晰呈现了AOI单元的布设方位以及实验夹具的设计方案。该设计通过不同角度的镜头与光源定位,实现了对矩形工件长边与短边的全面检测。
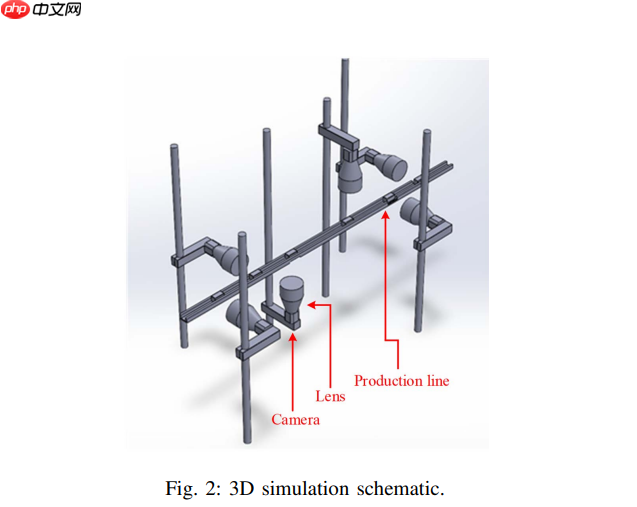
检测过程中,DIP元件在生产线上采用倒置安装方式。因此,顶部检测采用由下往上的图像采集方式,底部检测则采用由上往下的图像采集方式。DIP元件的正面与背面检测则通过左右两侧的两组相机完成。通过设备旋转机构实现侧边成像,使得两侧相机能够捕捉各个侧面的图像。其中,较长边对应DIP元件的上、下、前、后四个面,较短边对应左右两个侧面。为全面检测矩形DIP的长短边,实验需要配置两组具有特定景深参数的相机与镜头:长边检测相机采用小景深配置,短边检测相机采用大景深配置。具体相机镜头参数详见表二与表三。

B. DIP缺陷类型
正常DIP开关如图3所示。DIP元件缺陷主要分为两大类:表面缺陷与引脚缺陷。表面缺陷包含三种具体类型:表面溢料、表面划痕与表面污染。此外,引脚错位也是一种典型缺陷。上述四类缺陷DIP的示例如图4所示。

各类缺陷特征的像素尺寸范围为:图4(a)约100-300像素,图4(b)约100-500像素,图4(c)约100-300像素,图4(d)每个引脚约220-250像素。为增强特征对比度,图4(a)-(d)中的图像可采用RGB通道差值处理(如R通道减G通道,G通道减B通道)以强化图像特征。

C. 基于阈值的图像检测
为建立基线对比基准,我们引入基于阈值的图像检测方法。该方法首先使用预设阈值对原始图像进行二值化分类以获取特征图像。特征提取通过以下公式实现:

其中?(?, ?)表示基于二值决策的特征图像像素,?(?, ?)为原始图像像素,MinGray为最小阈值,MaxGray为最大阈值。
由于各相机对应的光照强度随DIP表面六个检测面的不同而变化,因此阈值参数MinGray与MaxGray需可调节。DIP各表面是否缺陷的判断依据为:

其中??(?)表示基于阈值的检测结果,? ?为预设阈值,?代表特征图像,?(·)为特征提取的输出图像。缺陷DIP的特征示例如图5所示。

3.基于深度学习的YOLO模型与ConSinGAN
图6展示了所提出检测方案的工作流程。为优选最佳YOLO版本,我们从准确率、浮点运算量(FLOPs)和参数量三个维度对比了不同YOLO版本。为提升YOLO模型精度,我们在数据预处理阶段采用ConSinGAN[48]进行数据集增强。该模型通过旋转、平移、翻转、缩放、高斯噪声等方式对原始图像进行数据增强。

A. 数据预处理
数据增强:如图7所示,我们采用多种技术增强缺陷DIP图像数据集:翻转、镜像、亮度调节、中值滤波、噪声添加和高斯模糊。数据增强对优化模型训练效果和提升特征区分度具有关键作用。

该模型采用多阶段、多分辨率训练策略:首阶段使用最低分辨率(如25×25像素),后续阶段逐步增加神经网络层数与图像分辨率。每个训练阶段会冻结之前所有阶段的网络层,仅训练当前新增层。与传统GAN不同,该模型采用多生成器架构,阶段数增加对应生成器数量增加。传统GAN将特征图在生成器阶段间传递,这会负面影响学习性能。ConSinGAN通过限制单阶段训练避免阶段间相互干扰。若采用端到端训练所有阶段,会导致单图像场景下的过拟合与网络崩溃。这意味着感受野与生成图像尺寸的关系随阶段数增加而减弱——高分辨率下判别器关注图像纹理,低分辨率下关注全局布局。
在阶段?中,ConSinGAN通过优化对抗损失与重构损失之和进行训练,并将判别器初始化为前一阶段?−1的权重:

其中L???(??,??)为与WGAN[50]相同的对抗损失,重构损失????(??)用于提升训练稳定性(实验中?设为10):


在阶段?的给定分辨率下,我们将下采样版本?0输入生成器??(?0)。
B. YOLO目标检测系列模型
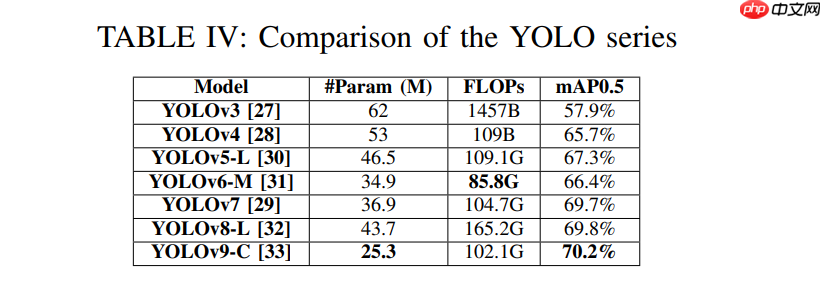
YOLO作为基于深度学习的目标检测算法,相较传统算法能在单一神经网络中快速完成目标检测与分类。其架构为包含多个卷积层和全连接层的卷积神经网络(CNN),将图像分割为S×S网格后检测各网格中多个目标。不同YOLO版本的筛选标准基于其浮点运算量(FLOPs)和平均精度(mAP)。表IV对比了YOLO v3至v9的性能指标,最终选择YOLOv7[29]作为DIP检测模型。实验中同时对比了YOLOv3[27]、YOLOv4[28]及最新YOLOv9[33]。由表VI可知,YOLOv7在精度上略胜YOLOv9但速度稍慢。YOLOv5[30]和YOLOv6[31]在FLOPs指标上与YOLOv7相近,但mAP较低。YOLOv8的FLOPs比YOLOv7高63%而mAP仅提升0.1%,因此未纳入主实验。
各对比模型的升级要点如下:
YOLOv3[27]:最重要改进是引入多尺度特征提取(特征金字塔网络FPN),并用二元交叉熵损失函数取代YOLOv2[53]的均方误差。采用Darknet-53替代YOLOv2的darknet-19,在提升深度与精度的同时牺牲了检测速度。 YOLOv4[28]:首先采用CSPDarknet53作为主干网络,实现轻量化且保持高精度;其次在颈部网络引入空间金字塔池化(SPP)[54]与路径聚合网络[55]以融合多尺度特征图;最后使用完整交并比(CIoU)损失函数提升检测框精度。 YOLOv7[29]:由H.-Y. M. Liao等人基于v4重构主干网络。与v5/v6不同,v7未在ImageNet上进行预训练。其新架构在精度与速度方面均有提升,架构如图9所示。
YOLOv7采用扩展高效层聚合网络(E-ELAN),通过扩展、混洗和合并操作使网络学习更丰富特征而不破坏梯度路径。检测头部分延续YOLOR[56]结构,其中:
CBS模块包含卷积层、批归一化(BN)和Mish激活函数[57] SPPCSPC作为头部首模块,接收主干网E-ELAN的输入,其采用带SPP块的跨阶段部分网络(CSPNet)替代YOLOv5[30]的密集块 CBM模块包含卷积层、批归一化和SiLU激活函数 REP模块代表RepVGG MP-1与MP-2的区别在于块内输出尺寸 E-ELAN与ELAN-W的区别在于块内输出尺寸主要改进包括: • 在重参数化卷积(RepConv)中,恒等连接会干扰ResNet的残差连接和DenseNet的拼接连接。而RepConv需保留能为不同特征图提供梯度多样性的特征。因此提出新型重参数化方法[58]替代恒等连接,针对ResNet设计的重参数化卷积称为RepConvN(无恒等连接的RepConv)。由于图10(a)的PlainNet本身无残差/拼接特性,可直接应用图10(b)的RepConv;而图10(c)的ResNet本身具有残差特性,使用图10(d)的RepConv会导致精度下降。故YOLOv7采用RepConvN设计网络。 • 通过辅助机制训练浅层权重以提升精度,并引入由粗到细的动态标签分配策略。最终输出头称为主导头,辅助训练头称为辅助头(结构如图11)。


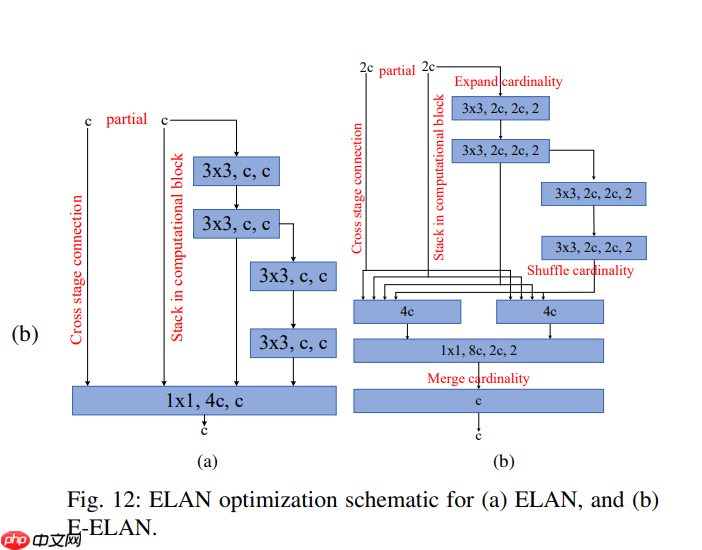
• 通过优化ELAN(图12(a)控制梯度路径长度,使深层网络有效学习。但堆叠更多CNN层会破坏稳定性,因此提出E-ELAN(图12(b)在保持梯度路径的同时,通过基数扩展/混洗/合并持续提升学习性能。
所提模型包含ConSinGAN数据增强和YOLO模型训练两部分。YOLO模型的局限性包括: • 计算能力:受硬件限制可能需采用轻量级模型而牺牲精度 • 训练成本:为实现精确检测需要大量标注数据,数据收集与标注耗时费力的数据收集与标注耗时费力 • 外部因素:图像中存在的额外障碍物或光照变化会降低检测精度 • 缺陷特征尺寸:若缺陷特征过小,单阶段检测效果逊于多阶段检测
4. 实验结果
本实验共涉及九种模型,具体包括:1) 基于阈值的检测方法;2) YOLOv3;3) YOLOv4;4) YOLOv7;5) YOLOv9;6) YOLOv3+ConSinGAN;7) YOLOv4+ConSinGAN;8) YOLOv7+ConSinGAN;9) YOLOv9+ConSinGAN。各模型超参数设置如下:
基于阈值的检测:根据公式(4),? ?设定为固定值100 各YOLO模型(含ConSinGAN组合):批尺寸=32,图像尺寸=416×416,学习率=0.001,最大批次数=10000生成对抗网络ConSinGAN的超参数设置为:学习率=0.1,训练阶段数=10,原始图像使用第二章所述的工业相机采集。原始图像总量为672张,从中选取具有显著缺陷特征的图像进行增强,最终生成图像总量达3,183张。
A. DIP图像数据集
ConSinGAN数据增强:初期尝试使用GAN和DCGAN进行数据增强,但因缺陷样本数量有限导致训练效果不佳。最终采用ConSinGAN,该模型能够基于少量图像生成相似图像实现有效增强。原始图像如图13所示,增强结果如图14所示。生成数据集中各检测面的缺陷DIP数量分布如表V所示。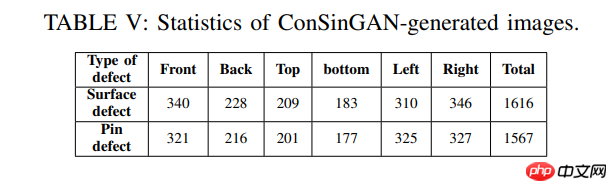


B. YOLO模型性能对比(含/不含ConSinGAN)
针对生成的图像数据各检测面分别训练YOLO模型。将3,183张图像划分为两类缺陷:表面缺陷(含溢料、划痕、污染)与引脚缺陷(引脚错位)。通过对比各模型在ConSinGAN增强数据集上的表现筛选最优模型。训练集占数据集80%(2,547张),验证集占10%(318张),测试集占10%(318张)。数据集中两类缺陷占比分别为:表面缺陷50.7%,引脚错位49.3%。
表VI展示了各YOLO模型结合ConSinGAN在mAP、精确率(???)、召回率(???)、?1分数、假正率(???)和真负率(???)方面的性能表现。实验结果表明:
采用ConSinGAN增强的YOLOv3/v4/v7/v9模型因数据扩增在精度指标上均优于未增强版本; YOLOv7+ConSinGAN组合在精度指标上表现最为突出(mAP0.5=95.5%),优于最新版YOLOv9+ConSinGAN; YOLOv9+ConSinGAN在检测速度上略胜于YOLOv7+ConSinGAN,但各模型检测时间均在300毫秒左右。
因此最终选择YOLOv7模型部署至SCADA界面(如图15所示)。需说明的是,ConSinGAN仅用于数据集增强,不影响YOLO模型复杂度。

C. 阈值检测法性能分析
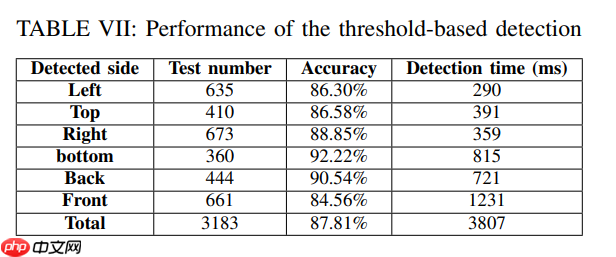
作为基线对比,表VII展示了阈值检测法在DIP各检测面的图像数量、准确率及检测时间。每个工件需完成六面检测,图像数量与YOLO实验保持一致,阈值设定为0.5。准确率计算公式如下:
? = (?? − ?)/?? × 100% (公式12)
其中?表示准确率,??为检测总数,?为误检数量。
表VII显示六面检测的平均准确率为87.81%,总检测时间为3.807秒(该时间取决于耗时最长的工站)。相比阈值法,提出的YOLOv7+ConSinGAN方案将准确率提升至95.5%。
D. 检测速度对比
图16显示各YOLO模型的检测速度显著优于阈值系统。阈值法需针对DIP六面图像分别调整参数,而YOLO模型仅需单一设置即可处理六面图像输入。这种差异使得YOLO模型无需针对不同检测面调整参数即可获得精确结果,从而形成性能优势。实验证明采用YOLOv7+ConSinGAN方案替代阈值图像处理法具有显著可行性。

5.结论
本文致力于建立用于DIP缺陷检测的自动光学检测系统,以提升产品质量并节约人力成本。通过SCADA界面集成图像检测与自动化机械硬件,实现了大批量DIP元件检测。在图像检测模型方面,我们对比了基于阈值的检测方法与基于深度学习的YOLO模型。虽然阈值检测法在准确率上优于基础版YOLO模型,但其耗时较长的缺陷促使我们采用ConSinGAN增强YOLO训练数据集以提升精度。实验表明,采用ConSinGAN的YOLOv7模型实现了95.5%的准确率,显著优于阈值检测法的87.81%。各YOLO变体的检测时间介于285-322毫秒之间,远低于阈值检测法的1231毫秒。综上所述,ConSinGAN在保持优异检测速度的同时,有效提升了YOLO模型的检测精度。未来工作重点包括:
• 应用新兴模型架构以优化检测网络性能 • 拓展自动化检测系统的工件适配种类,如旋转式DIP与表面贴装器件等大规模生产的电子元件 • 扩展SCADA系统覆盖更多产线,推进智能工厂与人工智能物联网融合建设


























