







蚂蚁百灵大模型团队近日正式开源了 ring-flash-linear-2.0-128k 模型,该模型特别适用于超长文本下的代码生成、编程任务以及智能 agent 等复杂应用场景。
据悉,该模型采用线性注意力与标准注意力机制相结合的混合架构,在保证高效推理的同时实现了卓越的性能表现。通过融合成熟的 MoE(Mixture of Experts)设计与多项优化技术——包括 1/32 的专家激活比率和 MTP 层结构,Ring-flash-linear 能在仅激活 6.1B 参数的情况下,展现出媲美 40B 全参数密集模型的能力。
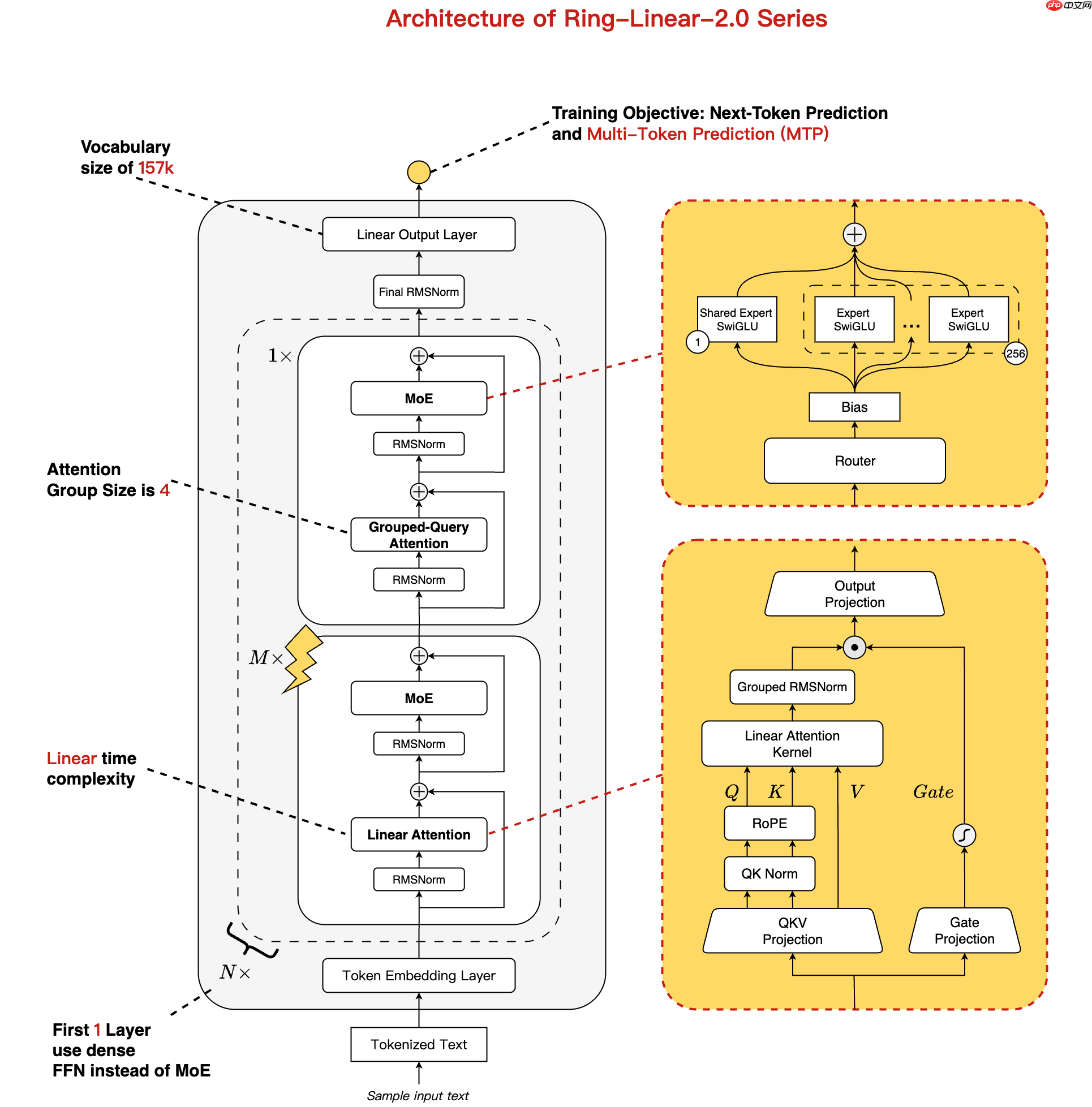
此模型基于 Ling-flash-base-2.0 进行转化,并在额外 1T token 数据上进行了持续训练。结合监督微调(SFT)与强化学习的稳定训练策略,模型在各类高难度推理任务中均达到了当前最优(SOTA)水平。
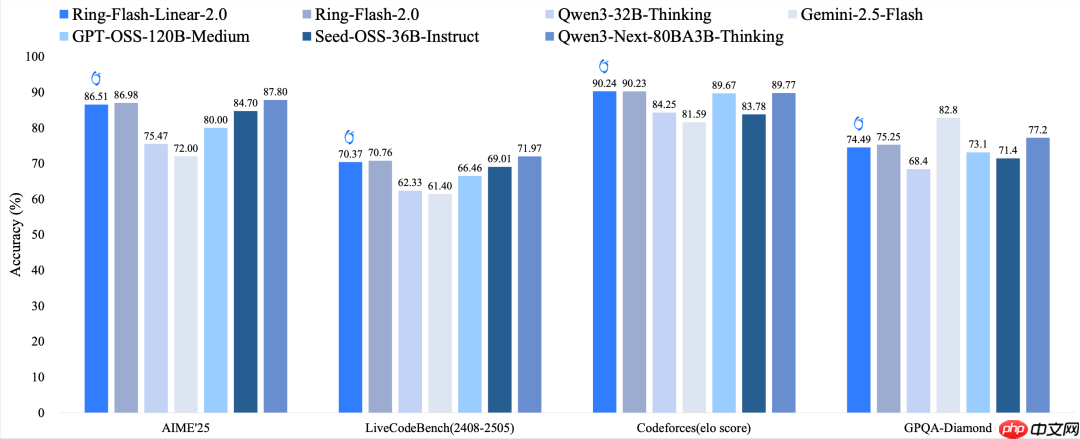

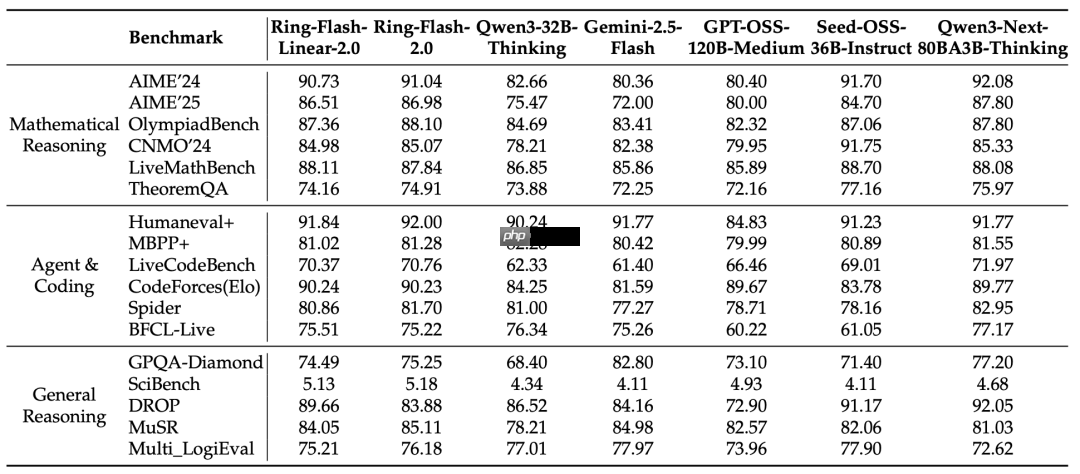
在多项基准测试中,Ring-flash-linear-2.0-128k 不仅表现优于众多现有的开源 MoE 和 Dense 模型,还能与使用标准注意力的 Ring-flash-2.0 模型相匹敌。模型原生支持长达 128K 的上下文长度,并可通过 YaRN 技术扩展至 512K,显著提升了对极长输入输出序列的处理速度与准确性。
Huggingface: https://www.php.cn/link/b78f81d5bdfed3168c472b237f37b43a Modelscope: https://www.php.cn/link/c5fb163f824e9eeed5086689a8a905d9 GitHub linghe 算子库: https://www.php.cn/link/af8e3c349612f1af5aa0509b16bae3cc





























