







☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
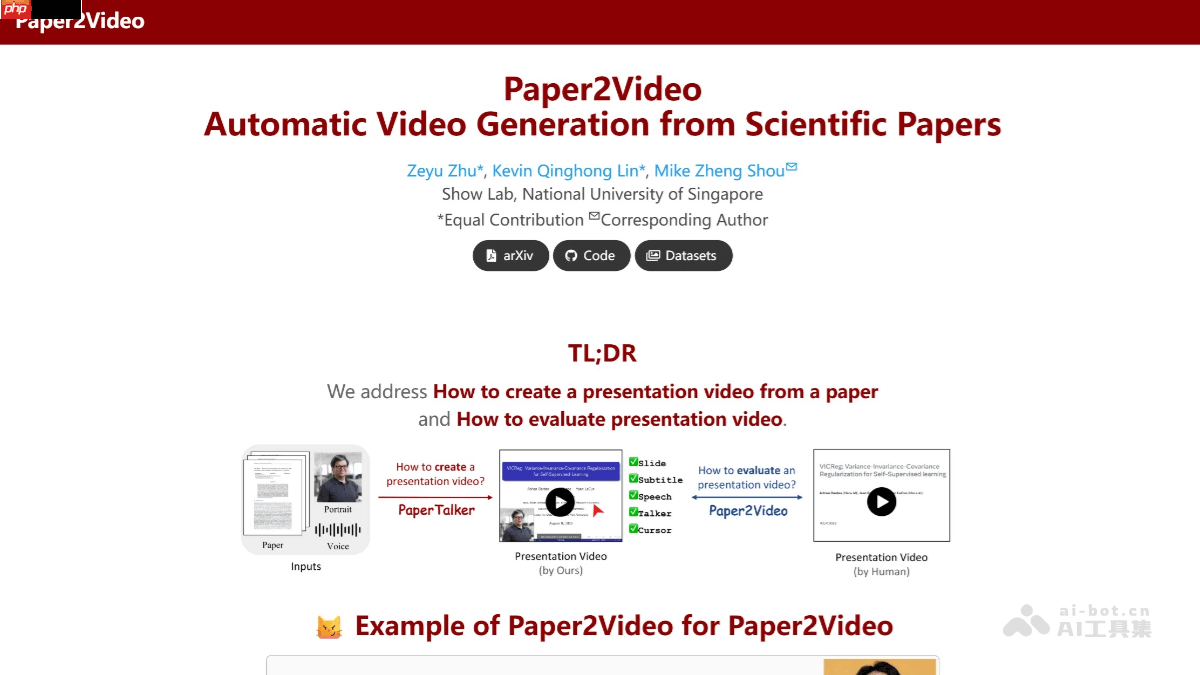
Paper2Video 是由新加坡国立大学 Show Lab 推出的一项创新技术,能够将学术论文自动转化为完整的演示视频。该系统基于名为 PaperTalker 的多智能体框架,整合了幻灯片、语音、字幕与虚拟演讲者头像的生成能力,输出包含讲解语音、同步字幕、动态光标和拟真人物形象的高质量学术视频。整个框架由四个核心模块构成:幻灯片构建器负责内容排版,字幕构建器生成讲解文本,光标构建器模拟指向操作,演讲者构建器合成个性化虚拟形象。此外,项目还发布了首个专注于学术视频演示的高质量基准数据集,涵盖101篇论文及其作者真实演讲视频和配套幻灯片。为评估视频质量,团队提出了四项新颖指标——Meta Similarity、PresentArena、PresentQuiz 和 IP Memory,分别用于衡量内容一致性、理解难度、贡献突出性以及影响力提升效果。
主要功能
- 自动化视频制作:从输入论文到输出完整讲解视频,实现端到端自动化,帮助用户快速将复杂研究成果可视化。
- 多模块协同框架:通过 PaperTalker 集成幻灯片设计、讲稿撰写、光标引导、语音合成与人脸动画生成,确保各元素协调统一。
- 权威基准支持:提供公开可用的数据集,包含真实作者演讲视频与对应材料,推动相关领域研究发展。
- 专业评估体系:引入四种定制化评测标准,全面分析视频在信息传递、可理解性、重点强调和传播潜力方面的表现。
- 开放工具包:项目开源全部代码并附带详尽文档,便于研究者复现结果或开发衍生应用。
技术实现机制
- 智能幻灯片构建:从论文 LaTeX 源码提取结构化内容,生成 Beamer 幻灯片初稿,并采用“树搜索+视觉语言模型评判”的策略进行布局优化,筛选出视觉效果最佳的版本。
- 精准字幕与时序控制:自动生成与每页幻灯片匹配的解说词,并规划光标运动路径,确保语音、文字与鼠标动作在时间轴上精确同步,增强观众注意力引导。
- 个性化演讲者合成:仅需一张作者照片和简短音频样本,即可利用 TTS 技术生成语音,并结合说话人面部动画模型,创建口型同步、表情自然的虚拟讲解人。
- 高效并行架构:将整体视频生成流程按幻灯片分块处理,各部分并行运行,显著提升生成速度,缩短等待时间。
项目资源链接

- 官方网站:https://www.php.cn/link/290f3bc899e6c7f69fff513048513324
- GitHub 仓库:https://www.php.cn/link/19ddc61af8f213d2c43c17204efab297
- 论文预印本(arXiv):https://www.php.cn/link/fa4c202fbc0421c1d4e317cbbbcac5a2
典型应用场景
- 学术会议展示:协助研究人员高效制作符合规范的演讲视频,减少准备负担,提高展示专业度。
- 在线教学内容创作:助力教师将前沿论文转化为易于理解的教学视频,丰富课程资源形式。
- 科研成果社交传播:让艰深的研究工作以直观视频形式登陆 YouTube、Twitter 等平台,扩大公众影响力。
- 内部汇报与答辩:支持团队快速生成项目进展或论文答辩所需的讲解视频。
- 科研品牌建设:为高校、实验室及独立学者提供现代化成果发布方式,提升学术可见度与社会认知。




























