







qwen3-vl cookbooks 是阿里巴巴推出的一套面向 qwen3-vl 多模态大模型的实战指南合集,旨在帮助开发者和研究人员快速上手并高效应用该模型。这套 cookbooks 系统性地整理了 qwen3-vl 在多种视觉-语言任务中的使用方法,涵盖从基础操作到复杂场景的完整示例,内容详实、结构清晰。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
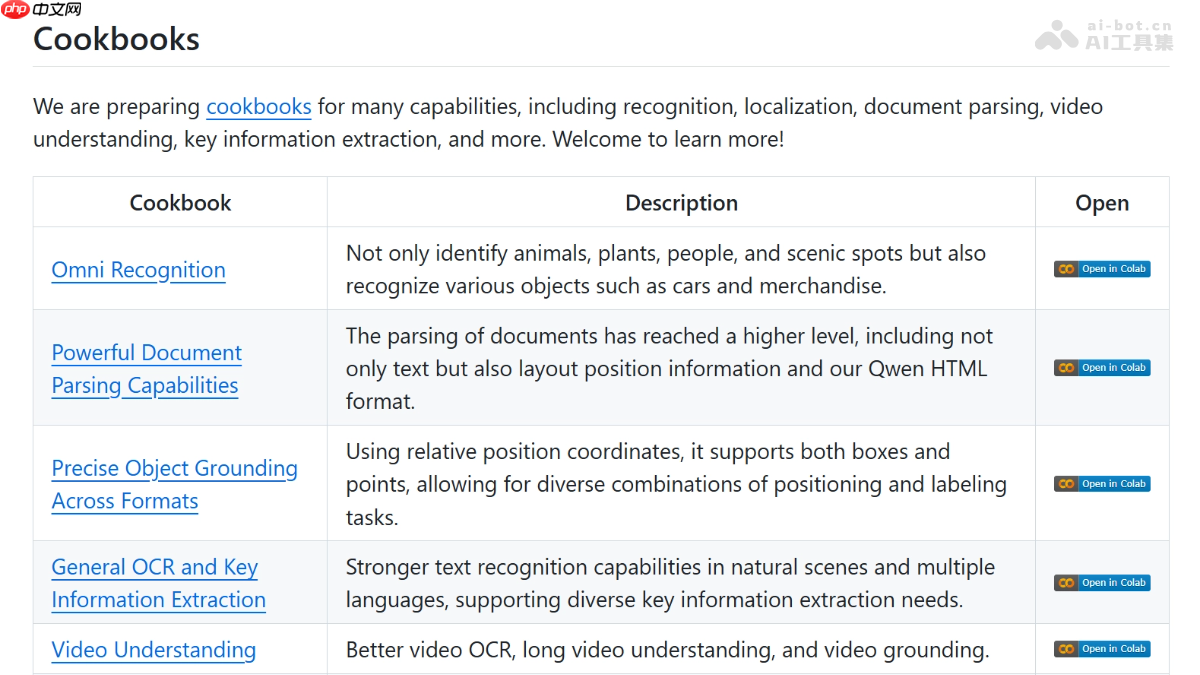
通过丰富的代码片段、可复用的脚本以及详细的步骤说明,用户可以轻松掌握如何调用 Qwen3-VL 实现图像理解、文档处理、视频分析等多模态任务,充分发挥其强大的跨模态推理能力。

Qwen3-VL Cookbooks的核心功能
- 提供详尽的操作指导:每个案例均配有清晰流程,帮助用户快速入门并实现功能验证。
- 覆盖主流多模态任务:展示如何融合图像、视频与文本数据完成实际任务,提升交互式应用开发效率。
- 优化使用实践路径:提供经过验证的高效处理流程与最佳编码实践,加速模型集成与部署。
- 适配多样化应用场景:支持从识别到控制、从静态图像到动态视频的广泛用途。
- 性能调优建议:针对不同硬件环境和任务需求,给出推理加速与资源优化策略。
主要涵盖的技术能力
- 全类型物体识别(Omni Recognition):精准识别图片中的动植物、人物、地标及商品等丰富类别。
- 强大文档解析能力(Document Parsing):提取文档中文字内容及其排版结构,支持输出为 Qwen HTML 格式。
- 跨格式目标精确定位(Precise Object Grounding):支持以坐标框或关键点形式标注图像中的指定对象。
- 多语言OCR与信息抽取(General OCR & KIE):具备32种语言识别能力,适应低光照、模糊、倾斜等复杂文本场景。
- 视频内容理解(Video Understanding):实现视频帧级OCR、动作分析与长视频语义建模。
- 移动端操作代理(Mobile Agent):基于视觉感知实现手机界面导航与自动化操作。
- 计算机操作代理(Computer-Use Agent):通过屏幕理解辅助完成网页点击、表单填写等桌面任务。
- 三维空间定位(3D Grounding):为室内外场景中的物体生成精确的3D边界框。
- 图像增强思考(Thinking with Images):结合缩放、区域搜索等工具深化对图像细节的理解与推理。
- 多模态编程生成(MultiModal Coding):根据视觉输入自动生成前端代码(HTML/CSS/JS)。
- 长文档深度理解(Long Document Understanding):支持对超长图文混排文档进行语义连贯性解析。
- 空间关系推理(Spatial Understanding):理解图像中物体之间的相对位置与空间布局。
项目开源地址
典型应用场景
- 智能安防领域:利用物体识别技术实时检测监控画面中的异常行为或可疑物品,提升预警响应速度。
- 金融合同处理:通过文档解析自动提取贷款协议、保单等文件的关键条款,大幅缩短人工审核周期。
- 自动驾驶感知系统:借助精确目标定位识别交通标志、行人及障碍物,增强环境感知准确性。
- 跨国客服系统:运用多语言OCR快速解析用户上传的外文证件或发票,实现信息自动录入。
- 在线教育平台:基于视频理解为教学视频生成时间轴字幕与知识点摘要,提升学习体验。




























