








<code class="javascript">作者:dominic masters翻译:王可汗校对:欧阳锦本文约3300字,建议阅读5分钟本文为大家介绍了提升effcientnet效率和性能的三个策略。</code>
在实践中有更好性能的efficientnet
在我们的新论文“Making EfficientNet More Efficient: Exploring Batch-Independent Normalization, Group Convolutions and Reduced Resolution Training”中,
我们采用了最先进的模型EfficientNet[1],该模型在理论上优化成为高效模型并研究了三种方法,使其在IPU上的实践中更高效。例如,添加分组卷积,已经被证明在IPU上表现良好,在理论计算成本最小的情况下,实际训练吞吐量实现了3倍提升。
结合调研的所有三种方法,我们在训练吞吐量上达到了7倍的提高,在IPU上的推理达到了3.6倍的提高,以达到相当的验证准确性。
模型训练的理论成本(通常以FLOPs来衡量)很容易计算,而且与所使用的硬件和软件堆栈无关。这些特征使它成为一种吸引人的复杂性度量,成为寻找更有效的深度学习模型的关键驱动因素。
然而,在现实中,这种训练成本的理论衡量和实践成本之间存在着显著的差异。这是因为一个简单的FLOP计数没有考虑许多其他重要的因素,比如计算结构和数据移动。
分组卷积的引入我们研究的第一种方法是如何提高与深度卷积相关的性能(换句话说,组大小为1的组卷积)。EfficientNet将深度卷积用于所有空间卷积操作。它们以其FLOP和参数量中的效率而闻名,因此已经成功地应用于许多最先进的卷积神经网络(CNNs)。然而,在实践中,EfficientNet在加速方面遇到了若干挑战。
例如,由于每个空间核都需要独立考虑,因此,通常由向量乘积型硬件加速的点积操作的长度是有限的。这意味着硬件不能总是被充分利用,导致“浪费”了周期。
深度卷积(Depthwise convolutions)也有非常低的计算效率,因为它们需要大量的数据传输,相对于执行的FLOPs的数量,这意味着内存访问速度是一个重要的因素。虽然这可能会限制替代硬件上的吞吐量,但IPU的处理器中内存架构提供了高带宽的内存访问,这可以显著提高像这样的低计算效率操作的性能。
最后,深度卷积被发现是最有效的,当它们被夹在两个逐点(pointwise)的“投影”(projection)卷积之间,形成一个MBConv块。这些逐点卷积通过围绕空间深度卷积的“扩展因子”6增加或减少激活的维数。虽然这种扩展可以带来良好的任务性能,但它也会创建非常大的激活张量,这可能会主导内存需求,并最终限制可使用的最大批处理大小。
为了解决这三个问题,我们对MBConv块做了一个简单但重要的修改。我们将卷积的组大小从1增加到16;这将带来更好的IPU硬件利用率。然后,为了补偿FLOPs和参数的增加,并解决内存问题,我们将扩展因子降低到4。这将带来一个更高效的内存和计算紧凑的EfficientNet版本,我们称之为G16-EfficientNet。
虽然这些改变主要是由于吞吐量的提高,但我们也发现,在所有模型大小上,它们使我们能够实现比普通的组大小为1 (G1-EfficientNet)基线模型更高的ImageNet验证精度。这一修改导致了实际效率的显著提高。
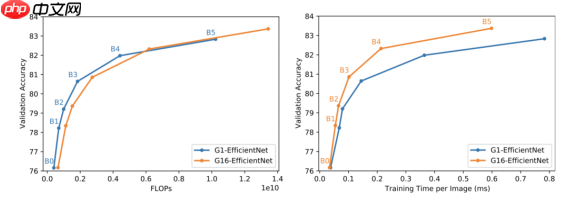
G1-EfficientNet(基线)与G16(我们的)的理论(左)和实际(右)效率的比较。
代理归一化激活对卷积和矩阵乘法运算的输出进行归一化已经成为现代CNN的一个基本操作,其中批处理归一化(Batch Normalization)是用于此目的的最常见的形式方法。然而,批处理归一化引入的批大小限制是一个众所周知的问题,它引发了一系列独立于批的替代方法的创新。虽然许多方法在ResNet模型中工作得很好,但我们发现它们都没有达到与EfficientNet的批处理归一化相同的性能。
为了解决批处理归一化替代方法的缺乏问题,我们利用了在最近的一篇论文中介绍的新的批无关的归一化方法——代理归一化(Proxy Normalization)。这种方法建立在已经成功的组(和层)归一化方法的基础上。
组归一化和层归一化受到一个问题的影响,即激活可能成为通道上的非归一化。随着深度的增加,这个问题变得更糟,因为非归一化在每个层面都凸显出来。虽然这个问题可以通过简单地减少组归一化中的组大小来避免,但是,这种组大小的减少将改变表达性并降低性能。
代理归一化提供了一个更好的解决方案,它保留了表达性,同时抵消了两个主要的非归一化来源:仿射变换和激活功能,遵循组归一化或层归一化。具体来说,通过将群范数或层范数的输出同化为一个高斯“代理”变量,并对这个代理变量应用相同的仿射变换和相同的激活函数来抵消非归一化。然后使用非归一化代理变量的统计数据来纠正真实激活中的预期分布偏移。
代理归一化允许我们将组大小最大化(即使用层归一化),即使不存在通道非归一化问题,代理归一化仍然保持了表达能力。
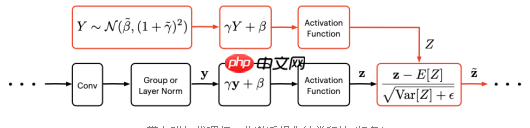
带有附加代理归一化激活操作的卷积块(红色)。
相关论文[2]详细探讨了这种新的归一化技术。
重要的是,这种方法并没有模仿批归一化的任何隐含的正则特征。由于这个原因,在这个工作中需要额外的正则化,我们使用混合和剪切混合的组合。在比较层归一化+代理归一化(LN+PN)与两个批归一化 (BN)基线模型在标准预处理和AutoAugment (AA)下的性能时,我们发现LN+PN在整个模型尺寸范围内都匹配或超过了BN的标准预处理性能。此外,LN+PN几乎和在AA上的BN一样好,尽管AA需要昂贵的训练增广参数的过程。
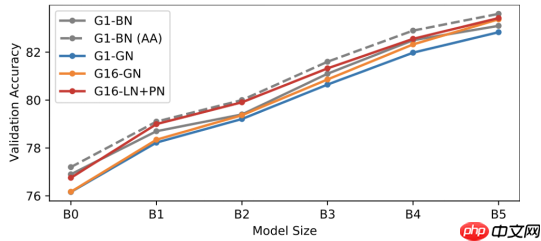
对不同规模的EfficientNet的不同归一化方法进行比较。
降低分辨率训练Touvron等人(2020)[3]表明,通过使用比最初训练更大的图像对最后几层进行训练,然后进行微调可以获得显著的精度增益。由于这个微调阶段的成本非常低,因此很明显,这将实现一些实际的训练效率效益。这提出了一些更有趣的研究问题。如何选择训练方案以使效率最大化?考虑到较大的图像测试速度较慢,这如何影响推理效率?
为了研究这些问题,我们比较了两种不同分辨率下的训练,一种是“原生”分辨率(如最初的EfficientNet工作中定义的),另一种是大约一半的像素数。然后我们对各种尺寸的图像进行微调和测试。这使我们能够研究训练分辨率对效率的直接影响,并确定帕累托最优组合,以实现训练和推理的最佳速度-精度折衷。
在比较训练效率时,我们考虑了两种测试场景:在“原生”分辨率上进行测试,或者选择“最佳”分辨率,以在整个分辨率范围内最大化验证精度。
当测试在“原生”分辨率,我们看到训练一半大小的图像产生相当大的理论和实际效率的提高。值得注意的是,对于给定的模型大小,我们发现在一半分辨率下的训练和在“原生”分辨率下的微调甚至比在“原生”分辨率下的训练、微调和测试产生更高的最终精度。这一结论表明,对于ImageNet训练,我们应该始终以比训练时更高的分辨率进行测试。我们现在希望了解这是否也适用于其他领域。
如果我们接下来允许自己在“最佳”图像分辨率进行测试,我们会看到在原生分辨率下的训练在最终精度上有显著的提高,缩小了帕累托前沿的差距。
然而,应该注意到,为了实现这一点,“原生”训练方案的“最佳”测试分辨率最终要比使用一半训练分辨率情况的测试分辨率大得多。这意味着在推理时间它们会更久。

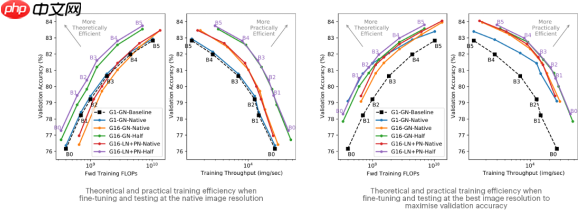
这些结果突出了三种改进对训练效率的改善:
(i)组卷积[G16(我们的研究)vs G1];
(ii)代理归一化激活[LN+PN (我们的) vs GN];
(iii)一半分辨率训练[half(我们的) vs Native]。
注意,基线结果没有进行微调,使用的是原生图像分辨率。
通过比较推理本身的效率,我们可以看到,在一半分辨率下的训练在整个精度范围内产生帕累托最优效率。这是一个显著的结果,因为在推理中根本没有直接的FLOP优势。此外,沿半分辨率推理效率Pareto前沿的点仍然是训练吞吐量的最优点。
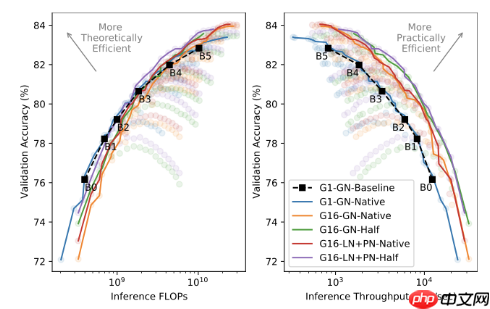
理论和实践推理效率。在所有的分辨率上测试;线条突出了帕累托锋面。
在所有模型的效率中,具有代理归一化的模型的表现与具有组归一化的模型相当或略好。这源于精确度的提高,而吞吐量的成本仅为~10%。然而,重要的是,具有代理归一化的模型在整个帕累托前沿使用更少的参数,突出了代理归一化在模型大小方面的效率方面的额外好处。
如何让EfficientNet更高效在进行这项研究时,我们看到了对EfficientNet模型的几个改进,以提高训练和推理的整体效率。
通过在MBConv块中添加组卷积和降低扩展率,我们提高了空间卷积的IPU硬件利用率,降低了内存消耗。通过使用一半分辨率的图像进行训练,我们减少了训练时间,并显著地取得了较好的最终精度。通过利用新的归一化方法——代理归一化,我们在不依赖批处理信息的情况下匹配了批归一化的性能。据我们所知,这是EfficientNet实现这一目标的第一种方法。综合使用这些方法,我们在IPU上的实际训练效率提高了7倍,实际推理效率提高了3.6倍。这些结果表明,当使用适合处理组卷积(如IPU)的硬件时,EfficientNet可以提供训练和推理效率,使其超越理论,面向实际的、真实的应用。
请阅读我们的论文。
https://arxiv.org/abs/2106.03640
References[1] M. Tan, Q. V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2019), arXiv 2019
[2] A. Labatie, D. Masters, Z. Eaton-Rosen, C. Luschi, Proxy-Normalizing Activations to Match Batch Normalization while Removing Batch Dependence (2021), arXiv 2021
[3] H. Touvron, A. Vedaldi, M. Douze, H. Jégou, Fixing the train-test resolution discrepancy: FixEfficientNet (2020), NeurIPS 2019
原文标题:
How we made EfficientNet more efficient
原文链接:
https://towardsdatascience.com/how-we-made-efficientnet-more-efficient-61e1bf3f84b3
编辑:王菁
校对:林亦霖
译者简介

王可汗,清华大学机械工程系直博生在读。曾经有着物理专业的知识背景,研究生期间对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与机械工程、计算物理碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。


























