







FastMTP是什么
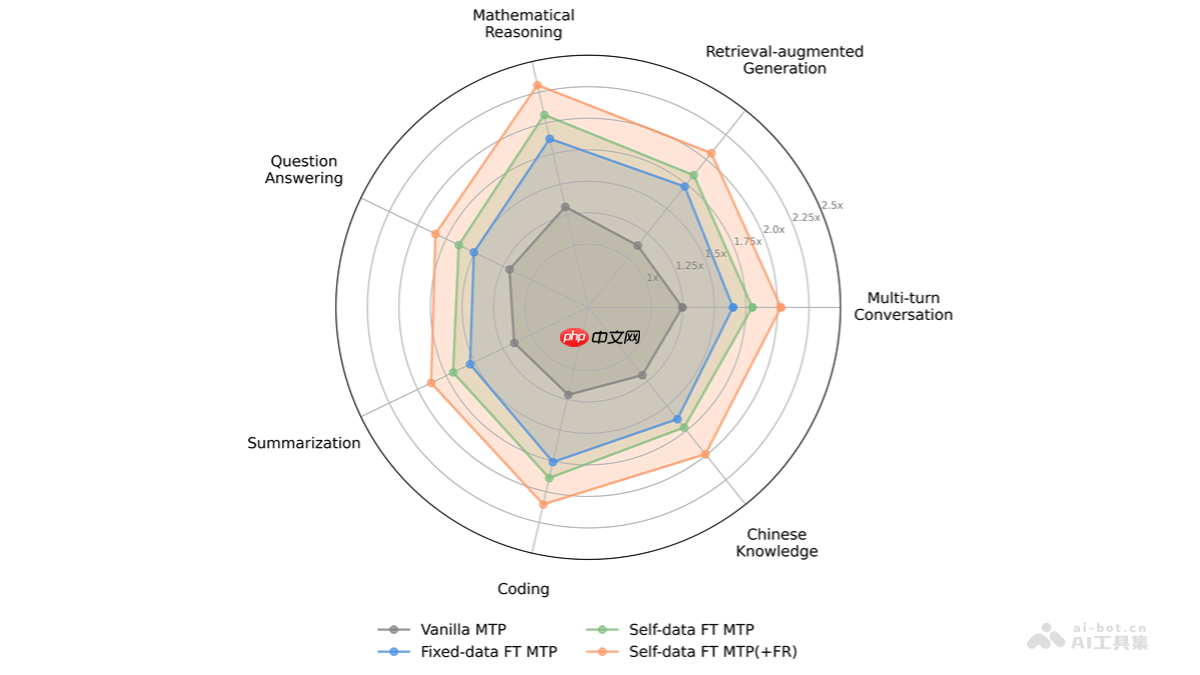
fastmtp 是腾讯自主研发的大语言模型(llm)推理加速技术,通过革新多标记预测(mtp)机制,采用共享权重的单一mtp头替代传统多个独立模块,融合语言感知词汇压缩与自蒸馏训练策略,显著提升llm推理效率。该技术在不牺牲输出质量的前提下,平均实现2.03倍的推理速度提升。fastmtp无需修改主干模型结构,具备良好的可集成性,适用于数学推导、代码生成等结构化生成任务,为大模型的高效部署提供了切实可行的技术路径。

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
FastMTP的主要功能
- 大幅提升推理速度:通过优化MTP架构,FastMTP可在保持生成质量不变的基础上,将大语言模型的推理性能平均提升2.03倍,有效缩短内容生成延迟,增强系统实时响应能力。
- 输出质量零损失:加速过程中,生成结果在准确性、连贯性和逻辑性方面与标准自回归方式完全一致,确保用户体验不受影响。
- 无缝集成现有框架:无需改动原始模型结构,仅需微调一个轻量级MTP模块,即可兼容主流推理引擎(如SGLang),便于快速落地和规模化应用。
- 减少资源开销:利用共享参数的单MTP头设计,大幅降低内存占用;结合语言感知的词汇剪枝策略,减少冗余计算,使大模型更易于在消费级GPU上高效运行,节约硬件成本。
FastMTP的技术原理
- 投机解码机制(Speculative Decoding):采用“草稿-验证”双阶段范式,由轻量草稿模块并行预测多个候选token,再由主模型批量验证,实现吞吐量提升。
- 统一共享MTP头:摒弃传统多头独立预测结构,使用一个共享权重的MTP头递归生成多个后续标记,减少参数冗余,增强长程依赖建模能力,提高草稿命中率。
- 自蒸馏训练策略:以主模型自身生成的高质量数据作为监督信号,训练MTP头学习其输出分布,结合指数衰减加权的交叉熵损失函数,优先保证高置信度token的生成一致性。
- 语境感知词汇压缩:在草稿阶段根据输入动态识别语言类型,仅计算高频词表内的logits,大幅降低计算负担;验证阶段仍使用完整词表,保障最终输出完整性。
FastMTP的项目地址
- GitHub仓库:https://www.php.cn/link/08c48adc90c8525f8ca1f8d727b5780c
- HuggingFace模型库:https://www.php.cn/link/12b2fce48d921b502cb67aaf23df662f
- 技术论文:https://www.php.cn/link/08c48adc90c8525f8ca1f8d727b5780c/blob/main/FastMTP\_technical\_report.pdf
FastMTP的应用场景
- 数学问题求解:在复杂数学推理任务中,快速生成详细的解题步骤,显著缩短响应时间,提升教育类AI工具的实用性。
- 程序代码生成:助力编程助手高效输出准确代码片段,加快开发流程,提升开发者生产力。
- 长文本摘要生成:针对新闻、报告等长文档,迅速提取核心信息,生成简洁精准的摘要,提升信息获取效率。
- 多轮对话系统:应用于智能客服或聊天机器人,实现低延迟回复,增强交互自然度与用户满意度。




























