







文章目录
前言
一、SDS介绍 1.SDS定义 2.柔性数组简介
二、SDS和C语言字符串对比 1.SDS可以以常数时间获取字符串长度 2.SDS可以避免缓冲区溢出 3.减少修改字符串导致的内存重新分配次数 4.SDS是二进制安全的 5.SDS支持部分C函数
三、Redis zmalloc 分析
四、Redis SDS源码剖析 1.获取len和free函数 2.初始化SDS字符串函数 3.SDS内存扩展函数
总结
前言
本文简要介绍了Redis的简单动态字符串(Simple Dynamic String,SDS),并结合SDS分析了Redis的内存分配和释放API。涉及的源码文件包括sds.h、sds.c、zmalloc.h和zmalloc.c。源码可从https://github.com/readywang/Redis3.0下载。
一、SDS介绍 1.SDS定义 SDS全称为简单动态字符串,是Redis用于表示字符串对象的一种数据结构。源码sds.h中定义的sdshdr结构表示简单动态字符串,定义如下:
/* 保存字符串对象的结构 */
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};实际的SDS对象示意图如下:
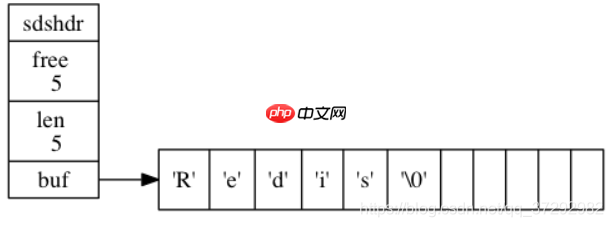
其中,buf是存放字符串的首地址,字符串以空字符(\0)结尾,这与C语言字符串类似。len表示buf中字符串占用的字节数,不包括末尾的空字符,free表示空闲的字节数。整个buf的大小等于len+free+1,其中1代表空字符。
2.柔性数组简介 C语言标准C99中,结构中的最后一个元素可以是未知大小的数组,这种元素称为柔性数组。sdshdr中的buf就是柔性数组。柔性数组的特点如下: 1、结构中的柔性数组成员前面必须至少有一个其他成员。 2、sizeof返回的这种结构大小不包括柔性数组的内存。 3、包含柔性数组成员的结构用malloc()函数进行内存的动态分配。
通过比较以下两个结构体,可以更清楚地理解柔性数组的特点:
struct sdshdrPtr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char *pBuf;
};第一点很容易理解。对于第二点,输出sizeof(sdshdr)的值通常为8,不包括buf占用的内存。而sizeof(sdshdrPtr)的值为12,包括了4字节的pBuf指针大小。这也是柔性数组相较于指针的一大优点:可以节省内存。对于第三点,柔性数组使用时通常根据len属性动态分配内存。例如,分配一个sdshdr对象来存储字符串的代码如下:
char *pStr = "Redis is too easy!"; // 待存储字符串 int len = strlen(pStr); sdshdr *pSds = (sdshdr *)malloc(sizeof(sdshdr) + len + 1); // 预留空字符 pSds->len = len; pSds->free = 0; memcpy(pSds->buf, pStr, len); pSds->buf[len] = '\0';
上述代码展示了如何根据实际存储数据的长度来分配内存,从而有效利用内存空间。不过,这仅是演示使用,实际的sdshdr对象的内存分配更为复杂,后续章节将详细介绍。

二、SDS和C语言字符串对比 C语言中的字符串可以存储ASCII编码的字符,并且每个字符串以空字符结尾。Redis为何不直接使用C语言字符串存储字符串数据,而是定义sdshdr来存储呢?
1.SDS可以以常数时间获取字符串长度 C字符串不记录自身的长度信息,因此要获取一个C字符串的长度,程序必须遍历整个字符串,计数每个字符,直到遇到空字符为止,这个操作的复杂度为O(N)。而SDS可以通过直接读取len成员来获取字符串长度,时间复杂度为O(1)。Redis中获取字符串长度的操作非常普遍,因此使用SDS可以有效提高效率。
2.SDS可以避免缓冲区溢出 C语言中常见的字符串操作函数如下:
// 将src字符串拼接到dest字符串末尾,默认要求dest空间足够大 char *strcat(char *dest, const char *src); // 将src字符串赋值给dest字符串,默认要求dest空间足够大 char *strcpy(char *dest, const char *src);
这些函数在执行时,如果dest分配的内存不足,就会发生缓冲区溢出,意外修改其他数据。而使用SDS的API进行拼接、赋值等操作时,API会先检查SDS的空间是否满足修改所需的要求。如果不满足,API会自动将SDS的空间扩展至执行修改所需的大小,然后才执行实际的修改操作。因此,使用SDS既不需要手动修改SDS的空间大小,也不会出现上述的缓冲区溢出问题。
3.减少修改字符串导致的内存重新分配次数 C字符串的底层实现是一个len+1个字符长的数组(额外的一个字符空间用于保存空字符)。因此,每次增长或缩短一个C字符串,程序都需要对保存这个C字符串的数组进行一次内存重新分配操作。如果是字符串长度增加,如上例中的strcat,程序首先要通过realloc分配足够大小的内存,再执行strcat。如果是字符串长度变小,程序就要通过free来释放不用内存。因此,如果字符串长度发生N次变化,则需要进行N次内存分配/释放操作。
SDS则通过空间预分配和惰性空间释放两种优化策略有效减少内存操作次数。空间预分配规则如下: 如果对SDS进行修改后,SDS的长度(即len属性的值)将小于1 MB,那么程序会为SDS分配与len属性同样大小的未使用空间。此时,SDS的len属性的值将和free属性的值相同。例如,如果进行修改后,SDS的len将变成13字节,那么程序也会分配13字节的未使用空间,SDS的buf数组的实际长度将变成13 + 13 + 1 = 27字节(额外的一字节用于保存空字符)。
如果对SDS进行修改后,SDS的长度将大于等于1 MB,那么程序会分配1 MB的未使用空间。例如,如果进行修改后,SDS的len将变成30 MB,那么程序会分配1 MB的未使用空间,SDS的buf数组的实际长度将为30 MB + 1 MB + 1 byte。
分配的未使用空间可以通过free来记录,这样下次如果要增加字符串长度时,先检查free大小能否满足使用,如果满足可以直接使用,不满足再分配,从而有效减少分配次数。
惰性空间释放用于优化SDS的字符串缩短操作:当SDS的API需要缩短SDS保存的字符串时,程序并不立即使用内存重新分配来回收缩短后多出来的字节,而是使用free属性将这些字节的数量记录起来,并等待将来使用。与此同时,SDS也提供了相应的API,让我们在有需要时,真正地释放SDS里面的未使用空间,因此不用担心惰性空间释放策略会造成内存浪费。
4.SDS是二进制安全的 C字符串只支持ASCII字符,并且中间不能存在空格。而SDS可以存储二进制数据,通过len属性来判断是否到达末尾。
5.SDS支持部分C函数 SDS中的buf之所以以空字符结尾,就是为了支持部分C函数,如下所示:
// 通过C语言API直接对比buf和C字符串 strcasecmp(sds->buf, "hello world");
三、Redis zmalloc 分析 Redis进行内存分配和释放时,并不只是简单地使用malloc/free等C函数,而是在此基础上进行了封装。在介绍封装的API之前,先看一下Redis在zmalloc.h文件中定义的一些全局变量。
/* 使用的内存字节数 */ static size_t used_memory = 0; /* 是否是线程安全情况 0=安全 1=不安全 */ static int zmalloc_thread_safe = 0; /* 更新used_memory时用到的互斥锁 */ pthread_mutex_t used_memory_mutex = PTHREAD_MUTEX_INITIALIZER;
可以看到,Redis通过used_memory记录了它使用内存的字节数,每次分配或释放内存时都会更新used_memory,更新时使用的宏定义如下所示。
/* 非线程安全条件下zmalloc分配内存时更新使用内存字节数 */
#define update_zmalloc_stat_add(__n) do { \
pthread_mutex_lock(&used_memory_mutex); \
used_memory += (__n); \
pthread_mutex_unlock(&used_memory_mutex); \
} while(0)
#define update_zmalloc_stat_sub(__n) do { \
pthread_mutex_lock(&used_memory_mutex); \
used_memory -= (__n); \
pthread_mutex_unlock(&used_memory_mutex); \
} while(0)
/* zmalloc和zcalloc分配内存以后更新使用内存字节数 */
#define update_zmalloc_stat_alloc(__n) do { \
size_t _n = (__n); \
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); \
if (zmalloc_thread_safe) { \
update_zmalloc_stat_add(_n); \
} else { \
used_memory += _n; \
} \
} while(0)
#define update_zmalloc_stat_free(__n) do { \
size_t _n = (__n); \
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); \
if (zmalloc_thread_safe) { \
update_zmalloc_stat_sub(_n); \
} else { \
used_memory -= _n; \
} \
} while(0)可以看到,update_zmalloc_stat_alloc负责在分配内存后增加used_memory的值,update_zmalloc_stat_free负责在释放内存后减少used_memory的值,输入参数_n即为新增或减少的内存。在这两个宏定义内部,又分为了线程安全和不安全两种情况,不安全时需要通过线程锁进行互斥访问。其中比较难理解的代码是以下这一行:
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1));
它的主要作用是如果分配或释放的内存_n不是long类型字节数的整数倍,则将其向上调整为sizeof(long)的整数倍,最终保证used_memory是sizeof(long)的整数倍。
在了解这些后,我们介绍一下最终的内存分配和释放函数。为了在释放内存时可以知道这块内存的大小以更新used_memory,在分配内存时额外分配了sizeof(size_t)大小的空间,并用它来记录分配的内存大小。具体API如下所示:
#define PREFIX_SIZE (sizeof(size_t))
/* zmalloc:分配内存,分配时多分配PREFIX_SIZE用于记录当前分配的内存所占字节数 */
void *zmalloc(size_t size) {
void *ptr = malloc(size+PREFIX_SIZE);
if (!ptr) zmalloc_oom_handler(size);
#ifdef HAVE_MALLOC_SIZE
update_zmalloc_stat_alloc(zmalloc_size(ptr));
return ptr;
#else
*((size_t*)ptr) = size;
update_zmalloc_stat_alloc(size+PREFIX_SIZE);
return (char*)ptr+PREFIX_SIZE;
#endif
}
/* 释放malloc分配的空间,更新内存使用字节数 */
void zfree(void *ptr) {
#ifndef HAVE_MALLOC_SIZE
void *realptr;
size_t oldsize;
#endif
if (ptr == NULL) return;
#ifdef HAVE_MALLOC_SIZE
update_zmalloc_stat_free(zmalloc_size(ptr));
free(ptr);
#else
realptr = (char*)ptr-PREFIX_SIZE;
oldsize = *((size_t*)realptr);
update_zmalloc_stat_free(oldsize+PREFIX_SIZE);
free(realptr);
#endif
}四、Redis SDS源码剖析 前面介绍了很多内容,现在进入SDS源码剖析的重点部分,主要涉及sds.h和sds.c两个文件。和SDS相关的API有很多,这里只能挑选几个进行剖析,其余的需要大家自己阅读源码。
1.获取len和free函数 SDS可以在常数时间内获取len和free属性,代码如下:
/* 类型别名,用于指向 sdshdr 的 buf 属性 */
typedef char *sds;
/* 返回 sds 实际保存的字符串的长度 */
/* T = O(1) */
static inline size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
/* 返回 sds 可用空间的长度 */
/* T = O(1) */
static inline size_t sdsavail(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->free;
}可以看到,Redis定义了sds作为char*的别名,指向sdshdr的buf属性。根据传入的sds参数可以很容易获取到sdshdr中的len和free属性。
2.初始化SDS字符串函数 可以根据传入的C字符串来构造一个SDS字符串,代码如下:
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
// 根据是否有初始化内容,选择适当的内存分配方式
// T = O(N)
if (init) {
// zmalloc 不初始化所分配的内存
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
// zcalloc 将分配的内存全部初始化为 0
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
// 内存分配失败,返回
if (sh == NULL) return NULL;
// 设置初始化长度
sh->len = initlen;
// 新 sds 不预留任何空间
sh->free = 0;
// 如果有指定初始化内容,将它们复制到 sdshdr 的 buf 中
// T = O(N)
if (initlen && init)
memcpy(sh->buf, init, initlen);
// 以 \0 结尾
sh->buf[initlen] = '\0';
// 返回 buf 部分,而不是整个 sdshdr
return (char*)sh->buf;
}3.SDS内存扩展函数 这个函数是对SDS中buf的长度进行扩展,确保在函数执行之后,buf至少会有addlen + 1长度的空余空间,便于其他函数调用。代码如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh;
// 获取 s 目前的空余空间长度
size_t free = sdsavail(s);
size_t len, newlen;
// s 目前的空余空间已经足够,无须再进行扩展,直接返回
if (free >= addlen) return s;
// 获取 s 目前已占用空间的长度
len = sdslen(s);
sh = (void*) (s-(sizeof(struct sdshdr)));
// s 最少需要的长度
newlen = (len+addlen);
// 根据新长度,为 s 分配新空间所需的大小
if (newlen free = newlen - len;
// 返回 sds
return newsh->buf;
}总结 本文主要介绍了Redis中SDS字符串的实现原理,很多内容在《Redis设计与实现》一书中已经讲得很详细了,我只是个小白搬运工,敬请批评指正。




























