







在本文中,我将深入探讨 javascript 中一个基本概念——执行上下文。通过阅读这篇文章,你将能够清楚地理解 js 解释器的工作原理,为什么可以在某些函数和变量声明之前使用它们,以及它们的取值是如何决定的。
什么是执行上下文(Execution Context)?当 JavaScript 代码运行时,它所在的执行环境非常重要,通常分为以下几种:
- 全局代码(Global code)——默认环境,代码首次执行的地方。
- 函数代码(Function code)——当代码执行进入函数体时。
- Eval 代码(Eval code)——在 eval 函数内部执行的文本。
网上有很多关于作用域的文章,本文的目的是让你更轻松地理解这些概念。让我们想象执行上下文这个术语就是当前代码的执行环境/作用域。废话不多说,让我们来看一个代码在全局和函数/局部上下文中执行的例子。
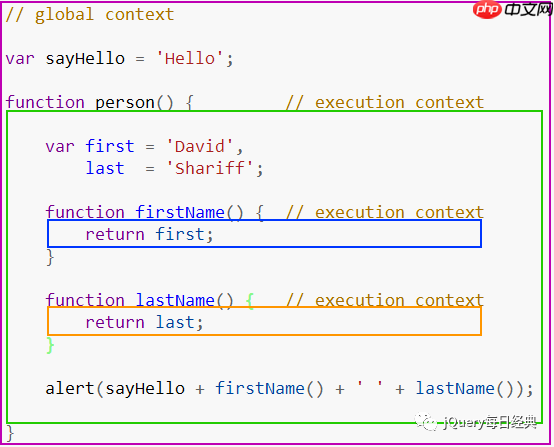 这里没有什么特别之处,我们有一个
这里没有什么特别之处,我们有一个全局上下文(用紫色边框标注)和三个不同的函数上下文(分别用绿色、蓝色、橙色边框标注)。只有一个全局上下文,并且可以被程序中的其他上下文访问。
你可以有多个函数上下文,每次函数调用都会创建一个新的上下文,并创建一个局部作用域,作用域内部声明的任何东西都不能被当前函数作用域外部访问。在上面的例子中,函数可以访问到当前上下文外部声明的变量,反之则不行。这是为什么呢?这些代码是如何执行的?
立即学习“Java免费学习笔记(深入)”;
执行上下文栈(Execution Context Stack)在浏览器中的 JavaScript 解释器是单线程的。这意味着在浏览器中一次只会发生一件事,其他行为或事件会在所谓的执行栈中排队等待。下面的图标是单线程栈的一个抽象表示:
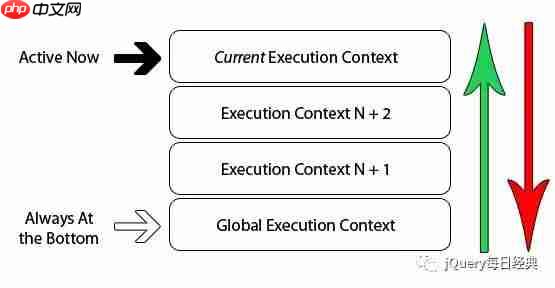 我们已经知道,浏览器第一次加载脚本时,它会默认进入
我们已经知道,浏览器第一次加载脚本时,它会默认进入全局执行上下文。如果你在全局环境中调用了一个函数,程序序列流会进入被调用的函数中,创建一个新的执行上下文并将其压入执行栈中。
如果你在当前函数中又调用了另一个函数,也会发生同样的事情。代码的执行流进入内部函数,这将创建一个新的执行上下文,它被压入现有栈的顶部。浏览器始终会执行当前栈顶的执行上下文。一旦函数在当前执行上下文中执行完毕,它会被从栈顶弹出,然后将控制权移交给当前栈的下一个上下文。下面的代码展示了一个递归函数以及程序的执行上下文:
(function foo(i) {
if (i === 3) {
return;
} else {
foo(++i);
}
}(0)); 这段代码会调用自身三次,每次将
这段代码会调用自身三次,每次将 i 的值增加 1。每次函数 foo 被调用时,都会创建一个新的执行上下文。一旦上下文执行完毕,它就会从栈中弹出并将控制权返回给下一个上下文,直到全局上下文再次被访问。
关于执行上下文,有五个要点需要记住:
- 单线程。
- 同步执行。
- 只有一个全局上下文。
- 可以有无数个函数上下文。
- 每个函数调用都会创建一个新的
执行上下文,即使是递归调用。
执行上下文的细节现在我们已经知道每个函数调用都会创建一个新的执行上下文。然而,在 JavaScript 解释器内部,每个执行上下文的调用会经历两个阶段:

AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。它不是新的编程语言,而是一种使用现有标准的新方法,最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容,不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。《php中级教程之ajax技术》带你快速
- 创建阶段(当函数被调用,但内部代码尚未开始执行):
- 创建作用域链。
- 创建变量、函数和参数。
- 决定
"this"的值。
- 激活/代码执行阶段:
- 赋值,寻找函数引用以及解释/执行代码。
我们可以用一个具有三个属性的概念性对象来代表执行上下文:
executionContextObj = {
'scopeChain': { /* 变量对象 + 所有父级执行上下文中的变量对象 */ },
'variableObject': { /* 函数参数/参数,内部变量以及函数声明 */ },
'this': {}
}活动对象/变量对象(AO/VO)这个executionContextObj对象在函数调用时创建,但在函数真正执行之前。这就是我们所说的第 1 阶段创建阶段。在这个阶段,解释器通过扫描传入函数的参数、局部函数声明和局部变量声明来创建executionContextObj对象。这个扫描的结果就变成了executionContextObj中的variableObject对象。
这是解释器执行代码时的伪概述:
- 寻找调用函数的代码。
- 在执行
函数代码之前,创建执行上下文。 - 进入创建阶段:
- 初始化
作用域链。 - 创建
变量对象:创建参数对象,检查参数的上下文,初始化其名称和值并创建一个引用拷贝。 - 扫描上下文中的函数声明:对于每个被发现的函数,在
变量对象中创建一个与函数名同名的属性,这是函数在内存中的引用。如果函数名已经存在,引用值将会被覆盖。 - 扫描上下文中的变量声明:对于每个被发现的变量声明,在
变量对象中创建一个同名属性并初始化值为 undefined。如果变量名在变量对象中已经存在,什么都不做,继续扫描。 - 确定上下文中的
"this"。
- 初始化
- 激活/代码执行阶段:
- 执行/在上下文中解释函数代码,并在代码逐行执行时给变量赋值。
让我们来看一个例子:
function foo(i) {
var a = 'hello';
var b = function privateB() {
};
function c() {
}
}
foo(22);在调用foo(22)时,创建阶段看起来像是这样:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: undefined,
b: undefined
},
this: { ... }
}你可以发现,创建阶段负责定义属性名,而不是给它们赋值,不过参数除外。一旦创建阶段完成之后,执行流就会进入函数中。在函数执行完之后,激活/代码执行阶段看起来像是这样:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: 'hello',
b: pointer to function privateB()
},
this: { ... }
}关于提升(Hoisting)网上有很多关于 JS 中提升这个术语的信息,用来解释变量和函数声明被“提升”到它们的函数作用域顶部的机制。然而,这些都没有详细解释为什么会发生这样的事情。用你刚刚学到的新知识,关于解释器如何创建活动对象,很容易就能理解。看下面的这个例子:
(function() {
console.log(typeof foo); // function pointer
console.log(typeof bar); // undefined
var foo = 'hello',
bar = function() {
return 'world';
};
function foo() {
return 'hello';
}
}());这些问题我们现在能回答了:
- 为什么在 foo 声明之前我们就能访问它?遵循
创建阶段,我们知道在激活/代码执行阶段之前,变量就被创建了。所以当函数被执行时,foo已经在活动对象中定义了。 - Foo 被声明了两次,为什么最后它显示为
function而不是undefined或string?虽然foo被声明了两次,但从创建阶段我们知道函数在变量之前被创建在活动对象中,并且如果属性名已经存在于活动对象中,重复声明会被忽略。因此function foo()的引用首先在活动对象中创建,而当解释器遇到var foo,我们发现foo属性名已经存在,所以解释器什么都不做继续运行。 - 为什么 bar 是 undefined?
bar实际上是一个被赋值为函数的变量,我们知道变量在创建阶段创建,但它们被初始化为 undefined。
总结希望现在你已经理解了 JavaScript 解释器是如何执行你的代码。理解执行上下文和调用栈能够让你清楚地知道为什么你的代码执行时得到的结果与你预期的不一样。
你认为了解 JS 解释器的内部工作原理是多余的,还是对你的 JavaScript 知识非常有帮助?了解执行上下文的阶段能帮助你编写更好的 JavaScript 代码吗?
注:有些人曾问我关于闭包、回调函数、定时器等相关问题,我会在下一篇文章中阐述,阅读作用域链了解更多与执行上下文有关的内容。




























