







在尝试运行huggingface上发布的deepseek v2时,我遇到了几个问题,这里提供了一些解决方案。huggingface提供的deepseek v2开源仓库链接为:https://www.php.cn/link/47ea4fca48eeb134e38df837a620c2c9
0x0. 背景
尝试启动HuggingFace上的DeepSeek V2时,我遇到了一些障碍。这里分享解决这些问题的具体方法。
0x1. 报错1: KeyError: 'sdpa'
这个问题在社区中也有其他人反馈过,具体讨论见:https://www.php.cn/link/47ea4fca48eeb134e38df837a620c2c9/discussions/3
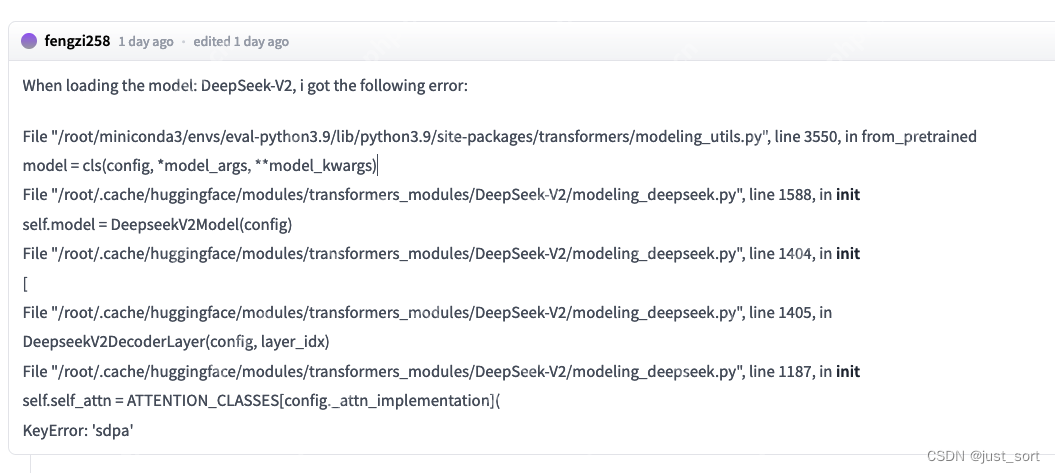
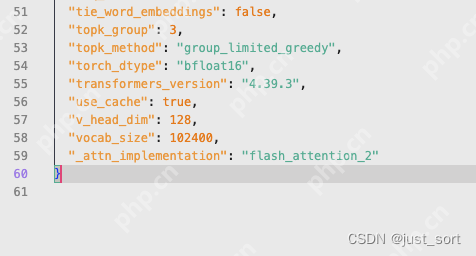
解决方法非常简单,只需在工程的config.json文件末尾添加一行"_attn_implementation": "flash_attention_2"即可:
0x2. 报错2: 初始化阶段卡死
我已经向accelerate项目提交了一个pull request来解决这个问题,具体见:https://www.php.cn/link/714aeac233808ffb2b01e3910edff2bc
在使用transformers库进行deepseek-v2模型推理时:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
<p>model_name = "deepseek-ai/DeepSeek-V2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)</p><h1><code>max_memory should be set based on your devices</h1><p>max_memory = {i: "75GB" for i in range(8)}</p><div class="aritcle_card flexRow">
<div class="artcardd flexRow">
<a class="aritcle_card_img" href="/ai/797" title="有道智云AI开放平台"><img
src="https://img.php.cn/upload/ai_manual/000/000/000/175679968792605.jpg" alt="有道智云AI开放平台" onerror="this.onerror='';this.src='/static/lhimages/moren/morentu.png'" ></a>
<div class="aritcle_card_info flexColumn">
<a href="/ai/797" title="有道智云AI开放平台">有道智云AI开放平台</a>
<p>有道智云AI开放平台</p>
</div>
<a href="/ai/797" title="有道智云AI开放平台" class="aritcle_card_btn flexRow flexcenter"><b></b><span>下载</span> </a>
</div>
</div><h1><code>device_map</code> cannot be set to <code>auto</code></h1><p>model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id</p><p>text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)</code>我发现程序卡住了...
解决
根据堆栈信息,程序卡在了这里(https://www.php.cn/link/f0f68749983c98403d5954cd5e0b7b30)。

对于DeepSeek V2,module_sizes的长度为68185,而这里的代码复杂度为O(N^2)(其中N = module_sizes),需要非常长的时间来执行,给人一种卡住的错觉。这个PR优化了代码,使其复杂度变为O(N),从而可以快速到达加载大模型的阶段。在一台8xA800机器上,经过这种优化后,推理结果也是正常的。
0x3. 单节点A800推理需要限制一下输出长度
由于模型的参数量有236B,用bf16来存储,单节点8卡A800每张卡都已经占用了大约60G,如果输出长度太长,用HuggingFace直接推理的话KV Cache就顶不住了。如果你想在单节点跑通并且做一些调试的话,输入的prompt设短一点,然后max_new_tokens可以设置为64。实测是可以正常跑通的。我跑通的脚本为:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig</p><p>model_name = "/mnt/data/zhaoliang/models/DeepSeek-V2/"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)</p><h1><code>max_memory should be set based on your devices</h1><p>max_memory = {i: "75GB" for i in range(8)}
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="auto", torch_dtype=torch.bfloat16, max_memory=max_memory)
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id</p><p>text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=64)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)</code>
0x4. VLLM
如果想在单节点8卡A100/A800上加速推理并且输出更长长度的文本,目前可以使用vllm的实现,具体见这个PR:https://www.php.cn/link/9826ee8eb827f4adacdb88e615550686



























