







在大型语言模型中了解注意力:初学者指南
>您是否曾经想过chatgpt或其他ai模型如何能够很好地理解和响应您的消息?秘密在于一种称为注意的机制 - 一种关键组成部分,可帮助这些模型理解单词之间的关系并产生有意义的响应。让我们简单地将其分解!
>什么是关注?
注意力如何工作?
>注意机制就像聚光灯一样工作,在处理句子中的每个单词时,可以专注于不同的单词。这是一个简单的故障:
对于每个单词,模型计算了其他单词与之相关的重要性。
- >
然后,它使用这些重要性得分来创建所有单词的加权组合。
- 这有助于模型理解上下文和单词之间的关系。
- 让我们以一个示例来想象一下:
在此图中,“ it”一词正在关注句子中的所有其他单词。箭头的厚度可以代表注意力重量。该模型可能会为“ CAT”和“ MAT”分配更高的注意力,以确定哪个“它”是指的。
多头注意:从不同角度看事物
在现代语言模型中,我们不仅使用一种注意机制 - 我们并行使用几种!这称为多头关注。每个“头”都可以专注于单词之间的不同类型的关系。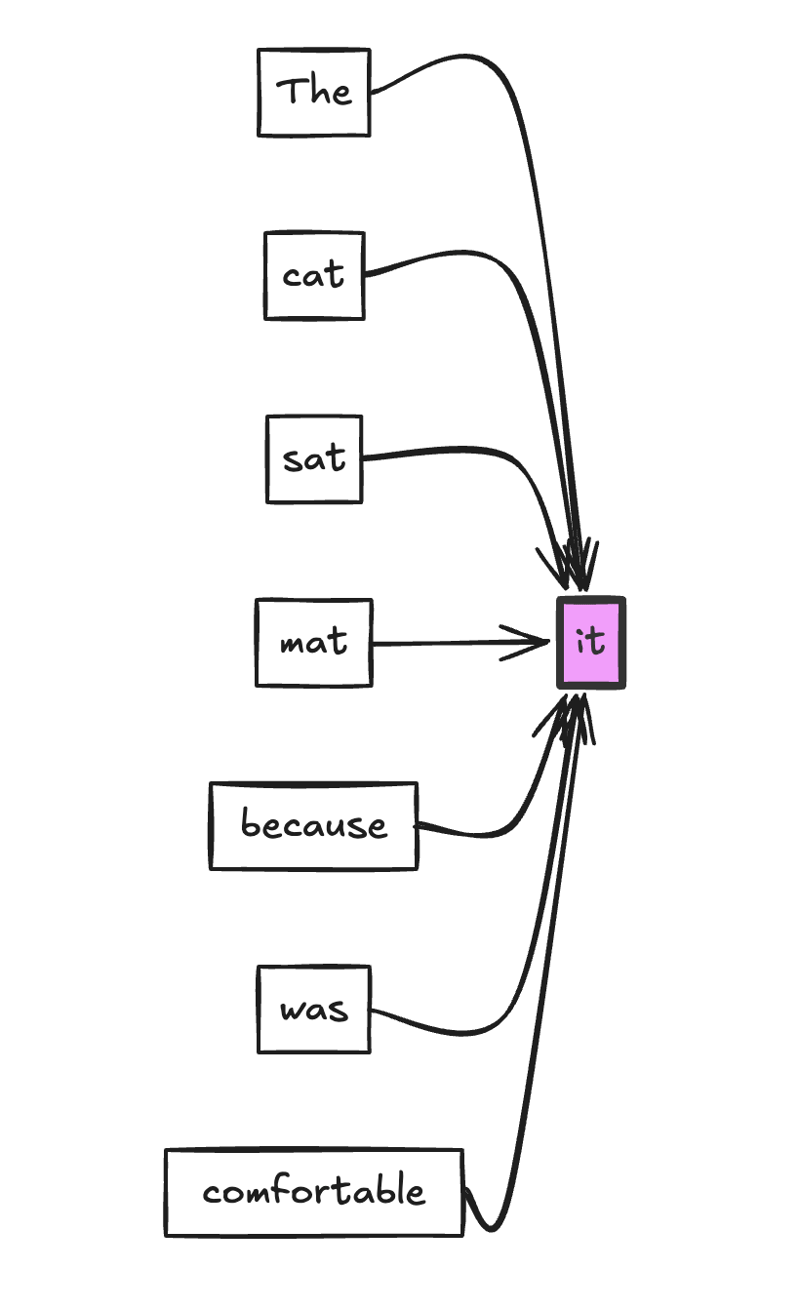
头1可以专注于主题 - 动力关系(厨师 - 准备)
>
头2可能会参加形容词 - 名词对(美味 - 餐)>
头3可以看更广泛的环境(竞争 - 餐)>
- 这是一个图:
- 这种多头方法可以帮助模型从不同的角度理解文本,就像我们人类可能多次阅读句子以理解其含义的不同方面一样。 为什么注意力很重要
比以前的方法更好地处理远程依赖。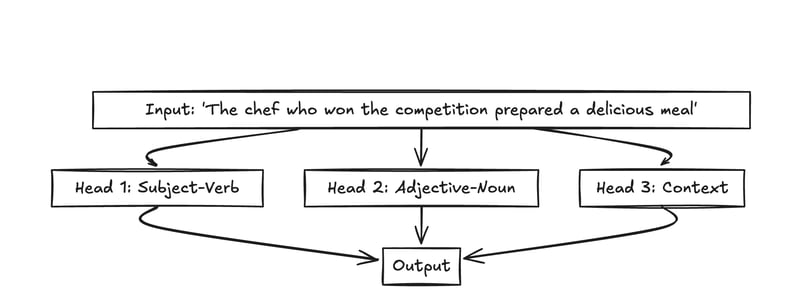 >
>
>
在单词之间创建可解释的连接。允许模型专注于相关信息,同时忽略无关的部分。
最近的发展和研究
-
LLM的领域正在迅速发展,并定期出现新技术和见解。以下是一些积极研究的领域:
- 上下文幻觉
- 大型语言模型(LLMS)有时会幻觉细节,并以对输入上下文不准确的未经证实的答案做出响应。
- 回顾镜技术分析了注意模式,以检测模型何时可能生成输入上下文中不存在的信息。
- 扩展上下文窗口
>研究人员正在努力扩展LLM的上下文窗口大小,使他们能够处理更长的文本序列。
结论虽然注意机制背后的数学可能很复杂,但核心思想很简单:在处理每个单词时,帮助模型专注于输入中最相关的部分。这允许语言模型更好地理解单词之间的上下文和关系,从而导致更准确和更连贯的响应。





























