







rtx 3080 移动版训练大型语言模型的实用指南
本文旨在指导 GPU 资源受限的开发者如何利用 GRPO (Group Relative Policy Optimization) 训练大型语言模型。DeepSeek-R1 的发布使得 GRPO 成为强化学习训练大型语言模型的热门方法,因为它高效且易于训练。 GRPO 通过利用模型自身生成的训练数据进行迭代改进,目标是最大化生成文本的优势函数,同时保持模型与参考策略的接近性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
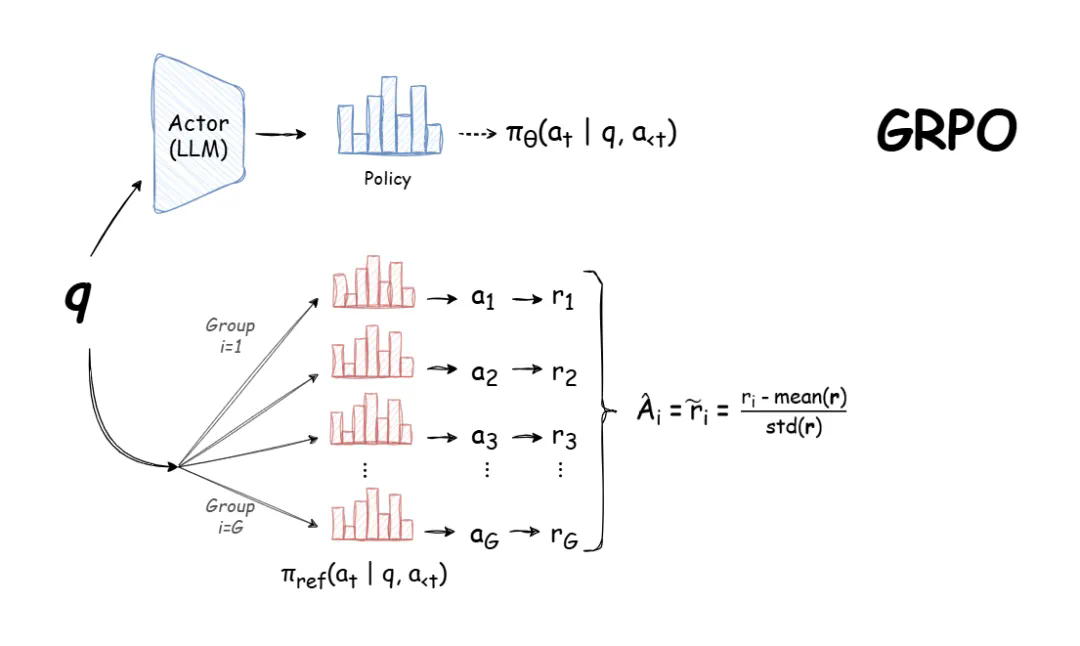
选择合适的模型大小和训练方法(全参数微调或参数高效微调 - PEFT)是训练的关键。本文作者 Greg Schoeninger (Oxen.ai CEO) 使用配备 16GB 显存的 RTX 3080 笔记本电脑进行实验,并分享了其经验。
 原文链接:https://www.php.cn/link/61d8c968f0a66dcf2b05982bdccb484b}}
原文链接:https://www.php.cn/link/61d8c968f0a66dcf2b05982bdccb484b}}
作者在使用 trl 库的 GRPO 实现时,遇到了显存不足 (OOM) 错误:
<code><ol><li><p><code>torch.OutOfMemoryError: CUDA out of memory.</code></p></li><li><p><code>Tried to allocate 1.90 GiB. GPU 0 has a total capacity of 15.73 GiB of which 1.28 GiB is free. </code></p></li><li><li><p><code>Including non-PyTorch memory, this process has 14.43 GiB memory in use. Of the allocated memory 11.82 GiB is allocated by PyTorch, and 2.41 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)</code></p></li></ol></code>
实验结果与内存需求分析
作者进行了一系列实验,测试不同模型大小(5亿到140亿参数)在 GSM8K 数据集上训练前 100 步的峰值内存使用情况,并比较了全参数微调和 PEFT 的内存需求。所有实验均在 Nvidia H100 上完成。
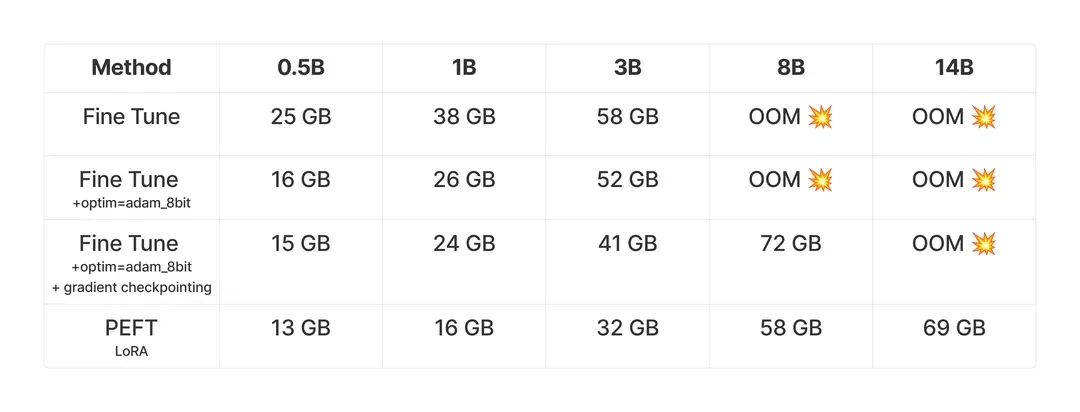
使用的模型包括:

GRPO 对内存需求高的原因在于其内部涉及多个模型(策略模型、参考模型、奖励模型)以及每个查询产生的多个输出。
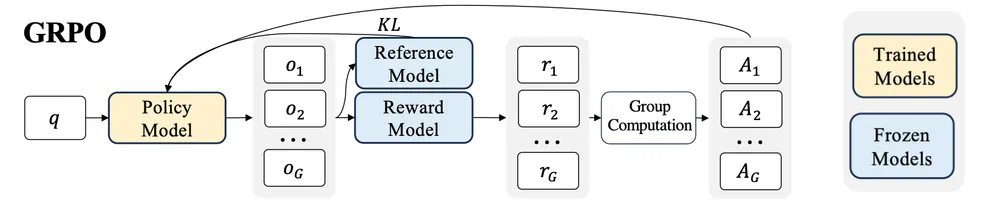
优化内存使用
8位优化器和梯度检查点技术可以有效减少内存占用。8位优化器更高效地存储优化器状态,而梯度检查点则通过在训练过程中拍摄快照来减少内存使用,虽然会降低训练速度。
代码示例
trl 库简化了 GRPO 的使用。以下代码示例展示了如何使用 trl 训练小型模型:
<code><ol><li><p><code>import torch</code></p></li><li><p><code>from datasets import load_dataset, Dataset</code></p></li><li><p><code>from transformers import AutoTokenizer, AutoModelForCausalLM</code></p></li><li><p><code>from trl import GRPOConfig, GRPOTrainer</code></p></li><li><p><code>import re</code></p></li><li><p><code>SYSTEM_PROMPT = """</code></p></li><li><p><code>Respond in the following format:</code></p></li><li><p><code><reasoning></reasoning></code></p></li><li><p><code>...</code></p></li><li><p><code></code></p></li><li><p><code><answer></answer></code></p></li><li><p><code>...</code></p></li><li><p><code></code></p></li><li><p><code>"""</code></p></li><li><p><code>def extract_hash_answer(text: str) -> str | None:</code></p></li><li><p><code>if "####" not in text:</code></p></li><li><p><code>return None</code></p></li><li><p><code>return text.split("####")[1].strip()</code></p></li><li><p><code>def get_gsm8k_questions(split = "train") -> Dataset:</code></p></li><li><p><code>data = load_dataset('openai/gsm8k', 'main')[split]</code></p></li><li><p><code>data = data.map(lambda x: {</code></p></li><li><p><code>'prompt': [</code></p></li><li><p><code>{'role': 'system', 'content': SYSTEM_PROMPT},</code></p></li><li><p><code>{'role': 'user', 'content': x['question']}</code></p></li><li><p><code>],</code></p></li><li><p><code>'answer': extract_hash_answer(x['answer'])</code></p></li><li><p><code>})</code></p></li><li><p><code>return data</code></p></li><li><p><code>def extract_xml_answer(text: str) -> str:</code></p></li><li><p><code>answer = text.split("<answer>")[-1]</answer></code></p></li><li><p><code>answer = answer.split("")[0]</code></p></li><li><p><code>return answer.strip()</code></p></li><li><p><code>def format_reward_func(completions, **kwargs) -> list[float]:</code></p></li><li><p><code>"""Reward function that checks if the completion has a specific format."""</code></p></li><li><p><code>pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"</code></p></li><li><p><code>responses = [completion[0]["content"] for completion in completions]</code></p></li><li><p><code>matches = [re.match(pattern, r) for r in responses]</code></p></li><li><p><code>return [0.5 if match else 0.0 for match in matches]</code></p></li><li><p><code>def accuracy_reward_func(prompts, completions, answer, **kwargs) -> list[float]:</code></p></li><li><p><code>"""Reward function that extracts the answer from the xml tags and compares it to the correct answer."""</code></p><div class="aritcle_card flexRow">
<div class="artcardd flexRow">
<a class="aritcle_card_img" href="/ai/1837" title="Mokker AI"><img
src="https://img.php.cn/upload/ai_manual/000/969/633/68b6c9b25e117919.png" alt="Mokker AI" onerror="this.onerror='';this.src='/static/lhimages/moren/morentu.png'" ></a>
<div class="aritcle_card_info flexColumn">
<a href="/ai/1837" title="Mokker AI">Mokker AI</a>
<p>AI产品图添加背景</p>
</div>
<a href="/ai/1837" title="Mokker AI" class="aritcle_card_btn flexRow flexcenter"><b></b><span>下载</span> </a>
</div>
</div></li><li><p><code>responses = [completion[0]['content'] for completion in completions]</code></p></li><li><p><code>extracted_responses = [extract_xml_answer(r) for r in responses]</code></p></li><li><p><code>return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]</code></p></li><li><p><code>def main():</code></p></li><li><p><code>dataset = get_gsm8k_questions()</code></p></li><li><p><code>model_name = "meta-llama/Llama-3.2-1B-Instruct"</code></p></li><li><p><code>model = AutoModelForCausalLM.from_pretrained(</code></p></li><li><p><code>model_name,</code></p></li><li><p><code>torch_dtype=torch.bfloat16,</code></p></li><li><p><code>attn_implementation="flash_attention_2",</code></p></li><li><p><code>device_map=None</code></p></li><li><p><code>).to("cuda")</code></p></li><li><p><code>tokenizer = AutoTokenizer.from_pretrained(model_name)</code></p></li><li><p><code>tokenizer.pad_token = tokenizer.eos_token</code></p></li><li><p><code>training_args = GRPOConfig(</code></p></li><li><p><code>output_dir="output",</code></p></li><li><p><code>learning_rate=5e-6,</code></p></li><li><p><code>adam_beta1=0.9,</code></p></li><li><p><code>adam_beta2=0.99,</code></p></li><li><p><code>weight_decay=0.1,</code></p></li><li><p><code>warmup_ratio=0.1,</code></p></li><li><p><code>lr_scheduler_type='cosine',</code></p></li><li><p><code>logging_steps=1,</code></p></li><li><p><code>bf16=True,</code></p></li><li><p><code>per_device_train_batch_size=1,</code></p></li><li><p><code>gradient_accumulation_steps=4,</code></p></li><li><p><code>num_generations=4,</code></p></li><li><p><code>max_prompt_length=256,</code></p></li><li><p><code>max_completion_length=786,</code></p></li><li><p><code>num_train_epochs=1,</code></p></li><li><p><code>save_steps=100,</code></p></li><li><p><code>save_total_limit=1,</code></p></li><li><p><code>max_grad_norm=0.1,</code></p></li><li><p><code>log_on_each_node=False,</code></p></li><li><p><code>)</code></p></li><li><p><code>trainer = GRPOTrainer(</code></p></li><li><p><code>model=model,</code></p></li><li><p><code>processing_class=tokenizer,</code></p></li><li><p><code>reward_funcs=[</code></p></li><li><p><code>format_reward_func,</code></p></li><li><p><code>accuracy_reward_func</code></p></li><li><p><code>],</code></p></li><li><p><code>args=training_args,</code></p></li><li><p><code>train_dataset=dataset,</code></p></li><li><p><code>)</code></p></li><li><p><code>trainer.train()</code></p></li><li><p><code>if __name__ == "__main__":</code></p></li><li><p><code>main()</code></p></li></ol></code>
trl 项目地址:https://www.php.cn/link/ccb8dbcf2c004cbbae8858760e4a22fa
超参数调整与VRAM估算
num_generations 超参数会显著影响 VRAM 消耗。建议在内存瓶颈解决前使用 num_generations=4。

GitHub 问题讨论:https://www.php.cn/link/3057aa0acb6d937295819f3d94f015e9
其他影响 VRAM 的因素包括 batch_size、gradient_accumulation_steps、max_prompt_length、max_completion_length 和 LoRA 的 target_modules。
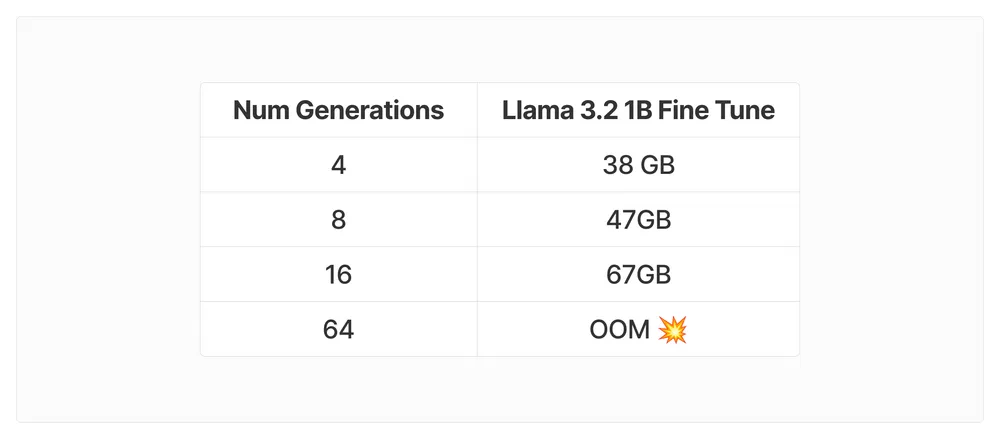
最后,作者分享了 10 亿参数 Llama 3.2 模型的训练结果,展示了 GRPO 在提高模型准确率方面的潜力。
通过合理的参数设置和优化技术,即使使用资源有限的 RTX 3080 移动版 GPU,也能有效训练大型语言模型。





























