








爬虫时网站源代码与页面内容和 element 不一致解决方法
在爬取网页时,遇到网页源代码与页面内容和 ELEMENT 不一致的情况,可以考虑以下方法解决:
对于本例中的 58 同城工作页面,网页源代码显示申请和浏览人数为 0,而页面数据和 F12 中的 ELEMENT 内容却是一致的。这种情况说明实际数据并不是存储在 HTML 源代码中,而是动态加载的。
要解决此问题,需要找到动态加载数据的接口地址。通过分析页面源码或网络请求,发现以下地址可以获取申请和浏览人数数据:
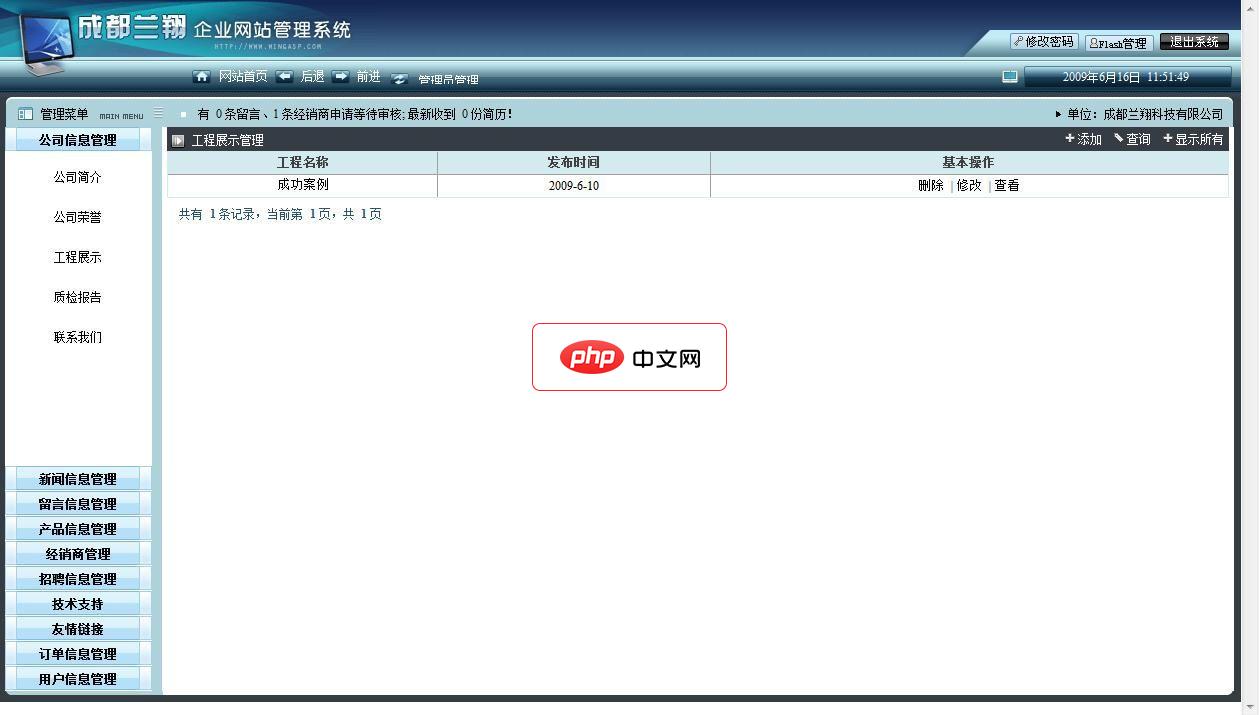
成都兰翔科技企业网站管理平台 2.1
下载
成都兰翔科技企业网站管理平台是一个网站管理系统。一个网站管理系统是把一个网站的内容(文字,图片,等等)与网站的组件分离开来,可以将各个页面连接到一起,可以控制页面的显示。通过这个系统,可以方便的管理,发布,维护网站的内容,而不再需要硬性的写HTML代码或手工建立每一个页面。 后台管理系统的大致(类似)功能:一.系统管理:管理员管理,可以新增管理员及修改管理员密码二.企业信息:可设置修改企业的各类信
向此地址发送请求,即可得到 JSON 数据,其中包含申请和浏览人数信息:
{
deliveryCount: 1141,
commentCount: 0,
infoCount: 4,
resumeReadPercent: 0,
referUrl: "",
nextUrl: "null"
}deliveryCount 即为申请人数,commentCount 为浏览人数。通过这种方式,即使网页源代码和 ELEMENT 中没有直接包含这些数据,也能成功爬取到所需的信息。

























