Html源码
post" action="../cmd.asp?act=SettingSav">
·BLOG的地址
·BLOG的名称
·BLOG的简介
·网站的标题
·网站的子标题
·主题名称
·界面样式名称
·BLOG版权说明
可以放置备案号和统计代码,支持HTML代码,可用'<br/>'标签换行
·BLOG所有者
·BLOG CLSID
Blog的唯一标识符,防止和同一空间其它Blog冲突,可随意设置为字母或数字的组合
·BLOG用户所在的时区
·主机服务器所在的时区
·BLOG 页面语言
·设置后台最新动态信息的Url地址
默认'http://update.rainbowsoft.org/info/',为空值则关闭此功能
·WEB编辑器
可设为fckeditor等,为空值则不启用WEB编辑
·允许上传文件的类型
以|做为分隔
·上传文件的最大字节数
·上传附件按"年/月"目录保存
·启用RSS的全文输出
·允许游客回复留言
·关闭评论功能
·关闭引用功能
·自定义留言本正文内容
支持HTML代码,可用'<br/>'标签换行
·最新评论及引用的数量
·文章存档列表的月份数量
为0表示不限
·最近发表文章的数量
·首页及列表页显示文章的数量
·管理页显示记录的数量
·RSS及ATOM显示文章的数量
·搜索显示文章的数量
·翻页条的条目数量
·启用单日志页面上下文章导航条
·相关文章条目数量
·启用评论和引用的倒序输出
·发表评论时启用验证码
·验证码图片中允许出现的字符
·验证码图片宽度
·验证码图片高度
·正文图片自动缩放宽度
超过此像素单位尺寸的图片自动缩小到该尺寸,为0则不使用该功能
·评论最长显示字符数
·侧栏Tags列表最大值
·静态文件后缀名
asp,html,shtml,htm
·日志存放目录
该目录必须已存在
·启用自定义静态日志目录功能
·自定义静态日志目录配置
可以是{%post%},{%category%},{%user%},{%year%},{%month%},{%day%},{%id%},{%alias%}之间的组合,可以用/分隔,系统初始化配置是{%post%}
·启用静态日志隐匿访问功能
开启匿名功能时自定义静态日志目录配置里必须包含有{%id%}或{%alias%}
·生成分类和按月归档的静态首页
·自定义分类和按月归档的静态首页配置
可以是{%post%}{%category%}之间的组合,可以用/分隔,系统初始化配置是{%post%}
·匿名访问分类和按月归档的静态首页
·单次重建文件数目
·单次重建文件后的间隔秒数
·UBB转换超连接标签
·UBB转换字体标签
·UBB转换代码框标签
·UBB转换表情标签
·UBB转换图片标签
·UBB转换多媒体标签
·UBB转换Flash标签
·UBB转换排版标签
·UBB自动链接认别
·评论输出No Follow标签
·日文转义为HTML字符
·表情图片配置字符串
·表情图片的尺寸
·WAP每页显示文章数
·WAP每页显示评论数
·WAP文章列表分页页码条长度
·WAP单页文章文字数
·WAP文章分页页码条长度
·WAP评论分页页码条长度
·WAP文件名
·允许WAP评论
默认不允许
·当前Z-Blog程序版本 :
<
script language="javascript">
需求
获取设置信息的key-value以及id
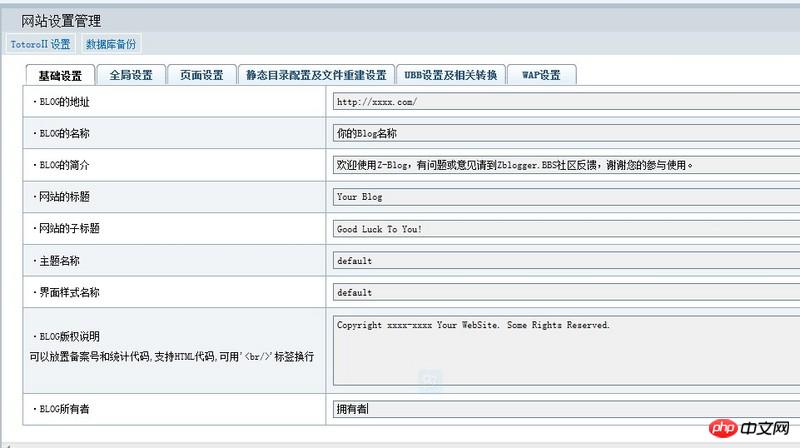
比如(图片中的第一行)
Key:Blog的地址
value:http://xxxxx.com
id:edtZC_BLOG_HOST
对应的正则表达式
(?.*?).*?id=\"(?.*?)\".*?value=\"(?.*?)\"
出现的问题
以上正则表达式会跳过标签为:textarea的内容(上图的倒数第二行)
所以,会出现以下结果:
key:BLOG版权说明可以放置备案号和统计代码,支持HTML代码,可用“br”标签换行
value:拥有者(匹配到最后一行)
id:edtZC_BLOG_COPYRIGHT



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号



 1
1 776
776

















像本问题这样,好好交代原本的需求X,就不会形成XY Problem的不良实践。赞一下。
很简单,
<input>的内容是在标签上边的value=""属性中的,<textarea>的内容是在标签里边用</...>括住的。你的正则表达式只能适应一种目的。另外求你别用正则这么分析HTML内容,因为源稍微一改就要疲于奔命改匹配,会死的。
好好的用一个HTML解析库,例如Python/Py3K的BeautifulSoup4。
另外无论是用正则凑合,还是真的用HTML解析库,都一个必要注意的问题:必须分解步骤,不要试图一次找准。必须先把表格分解成每一行(
<tr>...</tr>),然后在行内再做详细的查找。这样起码在出问题的时候,把问题能够约束在当前行之内,不会1行解析有问题就“牵一发而动全身”。