
进入主页,点击右上角“设为星标”,这样你就能比别人更快接收到优质文章。
Flink 的 Checkpoint 容错机制是其可靠性的基石,确保在某个算子因为异常退出等原因故障时,可以将整个应用流图的状态恢复到故障前的某一状态,保证应用流图状态的一致性。Flink 的 Checkpoint 机制基于“Chandy-Lamport algorithm”算法。
在应用启动时,Flink 的 JobManager 会为其创建一个 CheckpointCoordinator(检查点协调器),负责该应用的快照制作。
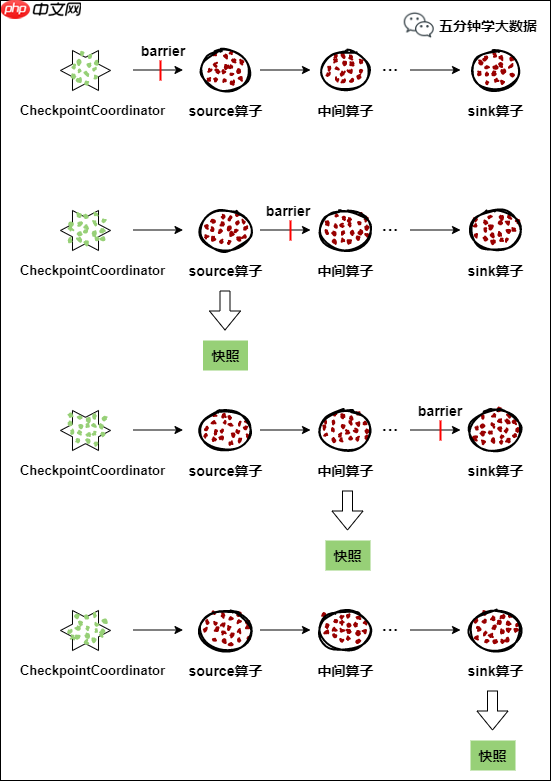
CheckpointCoordinator 周期性地向该流应用的所有 source 算子发送 barrier(屏障)。当某个 source 算子收到 barrier 时,会暂停数据处理过程,将当前状态制作成快照,并保存到指定的持久化存储中,最后向 CheckpointCoordinator 报告快照制作情况,同时向所有下游算子广播该 barrier,恢复数据处理。下游算子收到 barrier 后,也会暂停数据处理过程,将自身状态制作成快照,保存到指定的持久化存储中,向 CheckpointCoordinator 报告快照情况,并向自身所有下游算子广播该 barrier,恢复数据处理。每个算子按照上述步骤不断制作快照并向下游广播,直到 barrier 传递到 sink 算子,快照制作完成。当 CheckpointCoordinator 收到所有算子的报告后,认为该周期的快照制作成功;否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
文章推荐:Flink 可靠性的基石 - checkpoint 机制详细解析
Spark Streaming 的 Checkpoint 仅针对 Driver 的故障恢复做了数据和元数据的 Checkpoint。而 Flink 的 Checkpoint 机制更为复杂,它采用的是轻量级的分布式快照,实现了每个算子的快照及流动中的数据的快照。
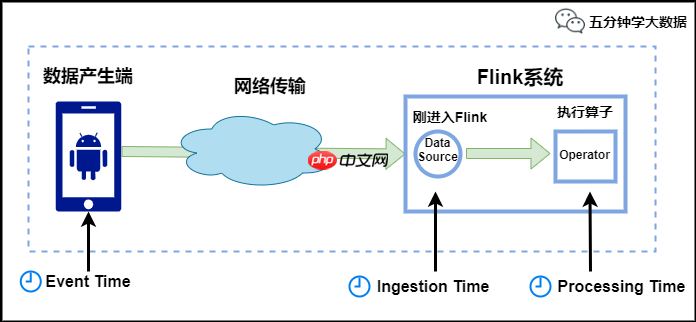
Flink 中的时间有三种类型,如下图所示:
2021-01-22 10:00:00.123
2021-01-22 10:00:01.234
2021-01-06 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计 1 分钟内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
Flink 中 WaterMark 和 Window 机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据 eventTime 进行业务处理。对于延迟的数据,Flink 也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据:
allowedLateness(lateness: Time)
sideOutputLateData(outputTag: OutputTag[T])
DataStream.getSideOutput(tag: OutputTag[X])
文章推荐:Flink 中极其重要的 Time 与 Window 详细解析
Flink 可以完全独立于 Hadoop,在不依赖 Hadoop 组件下运行。但是作为大数据的基础设施,Hadoop 体系是任何大数据框架都绕不过去的。Flink 可以集成众多 Hadoop 组件,例如 Yarn、Hbase、HDFS 等。例如,Flink 可以和 Yarn 集成做资源调度,也可以读写 HDFS,或者利用 HDFS 做检查点。
Flink 集群有以下三个角色:
在 Flink 中,每个 TaskManager 是一个 JVM 的进程,可以在不同的线程中执行一个或多个子任务。为了控制一个 worker 能接收多少个 task,worker 通过 task slot(任务槽)来进行控制(一个 worker 至少有一个 task slot)。
Flink 支持不同的重启策略,这些重启策略控制着 job 失败后如何重启:
Flink 通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几个步骤:
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
文章推荐:八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once
端到端的 exactly-once 对 sink 要求比较高,具体实现主要有幂等写入和事务性写入两种方式。
Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink 的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
Flink 在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink 提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
这道题问的比较开阔,如果知道 Flink 底层原理,可以详细说说,如果不是很了解,就直接简单一句话:Flink 的开发者认为批处理是流处理的一种特殊情况。批处理是有限的流处理。Flink 使用一个引擎支持了 DataSet API 和 DataStream API。
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上。此外,Flink 大量的使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序列化框架。
在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要支持数据的迟到现象,也就是 watermark 的处理逻辑。CEP 对未匹配成功的事件序列的处理,和迟到数据是类似的。在 Flink CEP 的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个 Map 数据结构中,也就是说,如果我们限定判断事件序列的时长为 5 分钟,那么内存中就会存储 5 分钟的数据,这在我看来,也是对内存的极大损伤之一。
文章推荐:详解 Flink CEP
--END--
以上就是Flink高频面试题,附答案解析的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 621
621






















