本文介绍基于Paddle复现的PoseC3D模型,其以3D热图堆栈为人体骨架表示,用3D-CNN分类,较GCN方法在时空特征学习等方面更优。复现在UCF-101数据集上达87.05%的top1准确率,详述了网络结构、环境依赖、数据集、代码结构及训练测试等流程,还提及复现心得。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

人体骨架作为人类行为的一种简洁的表现形式,近年来受到越来越多的关注。许多基于骨架的动作识别方法都采用了图卷积网络(GCN)来提取人体骨架上的特征。尽管在以前的工作中取得了积极的成果,但基于GCN的方法在健壮性、互操作性和可扩展性方面受到限制。
在本文中,作者提出了一种新的基于骨架的动作识别方法PoseC3D,它依赖于3D热图堆栈而不是图形序列作为人体骨架的基本表示。与基于GCN的方法相比,PoseC3D在学习时空特征方面更有效,对姿态估计噪声更具鲁棒性,并且在跨数据集环境下具有更好的通用性。
此外,PoseC3D可以在不增加计算成本的情况下处理多人场景,其功能可以在早期融合阶段轻松与其他模式集成,这为进一步提升性能提供了巨大的设计空间。在四个具有挑战性的数据集上,PoseC3D在单独用于Keletons和与RGB模式结合使用时,持续获得优异的性能。
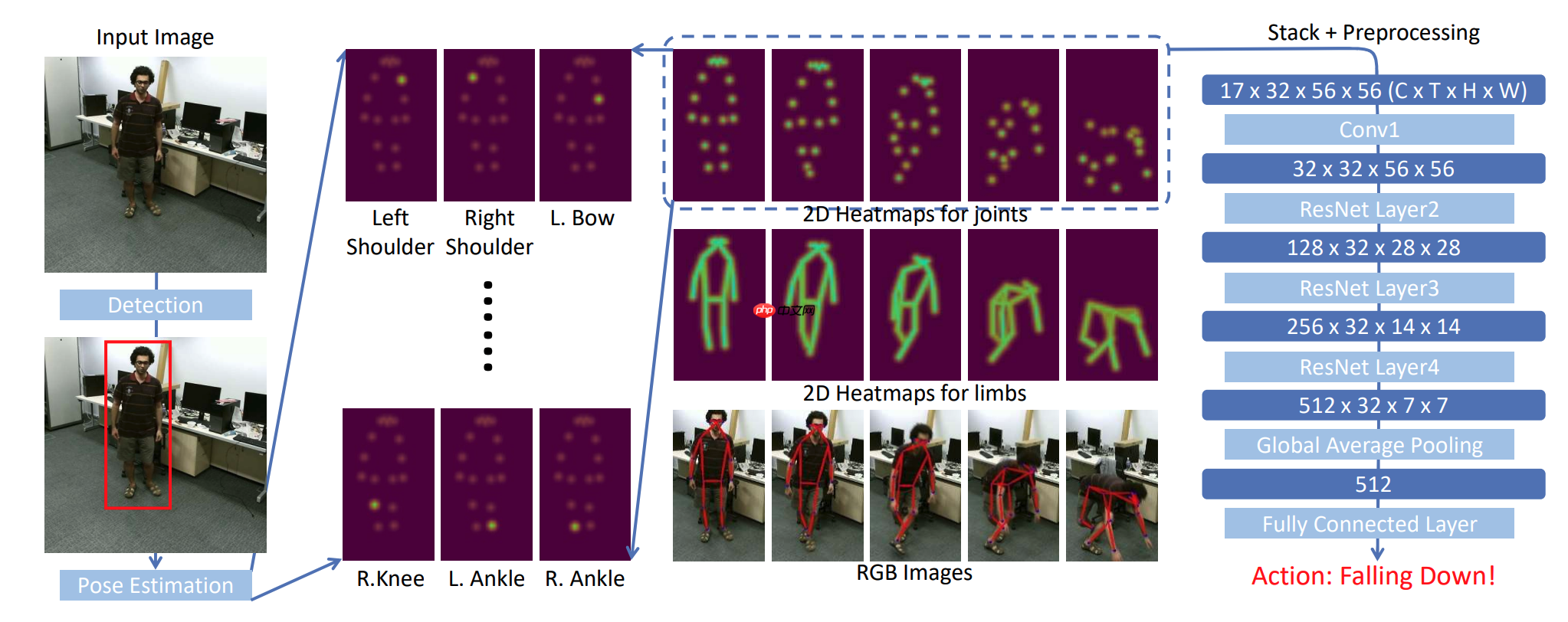
上图是网络架构,对于视频中的每一帧,首先使用两阶段姿势估计(检测+姿势估计)进行人体姿势提取。然后沿着时间维度堆叠关节或肢体的heatmap,并对生成的三维heatmap进行预处理。最后,我们使用3D-CNN对三维的heatmap进行分类。
在UCF-101数据集上spilt1的测试效果如下表。
| NetWork | epochs | opt | image_size | batch_size | dataset | top1 acc |
|---|---|---|---|---|---|---|
| PoseC3D | 12 | SGD | 56x56 | 16 | UCF-101 | 87.05% |
UCF-101以及预训练模型下载地址:
https://aistudio.baidu.com/aistudio/datasetdetail/140593
PaddlePaddle == 2.2.2
从第一节的图中可以看到,网络的主要结构由Resnet中的Layer构成,网络结构代码如下:
class ResNet3d(nn.Layer):
arch_settings = {
50: (Bottleneck3d, (3, 4, 6, 3)),
101: (Bottleneck3d, (3, 4, 23, 3)),
152: (Bottleneck3d, (3, 8, 36, 3))
}
上述代码定义了ResNet3d的网络类,以及定义了不同层数网络的配置。
def __init__(self,
depth,
pretrained,
stage_blocks=None,
pretrained2d=True,
in_channels=3,
num_stages=4,
base_channels=64,
out_indices=(3, ),
spatial_strides=(1, 2, 2, 2),
temporal_strides=(1, 1, 1, 1),
dilations=(1, 1, 1, 1),
conv1_kernel=(3, 7, 7),
conv1_stride_s=2,
conv1_stride_t=1,
pool1_stride_s=2,
pool1_stride_t=1,
with_pool1=True,
with_pool2=True,
style='pytorch',
frozen_stages=-1,
inflate=(1, 1, 1, 1),
inflate_style='3x1x1',
conv_cfg=dict(type='Conv3d'),
norm_cfg=dict(type='BN3d', requires_grad=True),
act_cfg=dict(type='ReLU', inplace=True),
norm_eval=False,
with_cp=False,
non_local=(0, 0, 0, 0),
non_local_cfg=dict(),
zero_init_residual=True,
**kwargs):
super().__init__() if depth not in self.arch_settings: raise KeyError(f'invalid depth {depth} for resnet') # 初始化网络参数
self.depth = depth
self.pretrained = pretrained
self.pretrained2d = pretrained2d
self.in_channels = in_channels
self.base_channels = base_channels
self.num_stages = num_stages assert 1 <= num_stages <= 4
self.stage_blocks = stage_blocks
self.out_indices = out_indices assert max(out_indices) < num_stages
self.spatial_strides = spatial_strides
self.temporal_strides = temporal_strides
self.dilations = dilations assert len(spatial_strides) == len(temporal_strides) == len(
dilations) == num_stages if self.stage_blocks is not None: assert len(self.stage_blocks) == num_stages # 保存卷积网络参数
self.conv1_kernel = conv1_kernel
self.conv1_stride_s = conv1_stride_s
self.conv1_stride_t = conv1_stride_t
self.pool1_stride_s = pool1_stride_s
self.pool1_stride_t = pool1_stride_t
self.with_pool1 = with_pool1
self.with_pool2 = with_pool2
self.style = style
self.frozen_stages = frozen_stages
self.stage_inflations = _ntuple(num_stages)(inflate)
self.non_local_stages = _ntuple(num_stages)(non_local)
self.inflate_style = inflate_style
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
self.norm_eval = norm_eval
self.with_cp = with_cp
self.zero_init_residual = zero_init_residual
self.block, stage_blocks = self.arch_settings[depth] if self.stage_blocks is None:
self.stage_blocks = stage_blocks[:num_stages]
self.inplanes = self.base_channels
self.non_local_cfg = non_local_cfg
上述代码初始化网络的超参数。
# 构建第一个 stem层
self._make_stem_layer()
self.res_layers = [] # 根据stage_blocks的内容构建网络。
# 这里的stage_blocks是(3, 4, 6)。
for i, num_blocks in enumerate(self.stage_blocks):
spatial_stride = spatial_strides[i]
temporal_stride = temporal_strides[i]
dilation = dilations[i]
planes = self.base_channels * 2**i
res_layer = self.make_res_layer(
self.block,
self.inplanes,
planes,
num_blocks,
spatial_stride=spatial_stride,
temporal_stride=temporal_stride,
dilation=dilation,
style=self.style,
norm_cfg=self.norm_cfg,
conv_cfg=self.conv_cfg,
act_cfg=self.act_cfg,
non_local=self.non_local_stages[i],
non_local_cfg=self.non_local_cfg,
inflate=self.stage_inflations[i],
inflate_style=self.inflate_style,
with_cp=with_cp,
**kwargs)
self.inplanes = planes * self.block.expansion
layer_name = f'layer{i + 1}'
self.add_sublayer(layer_name, res_layer)
self.res_layers.append(layer_name)
self.feat_dim = self.block.expansion * self.base_channels * 2**( len(self.stage_blocks) - 1)
上述为构建网络的主要的代码,首先构建一个stem层,然后根据stage_blocks的内容,使用make_res_layer方法构建网络。
def make_res_layer(block,
inplanes,
planes,
blocks, spatial_stride=1, temporal_stride=1, dilation=1, style='pytorch', inflate=1, inflate_style='3x1x1', non_local=0, non_local_cfg=dict(), norm_cfg=None, act_cfg=None, conv_cfg=None, with_cp=False,
**kwargs):
inflate = inflate if not isinstance(inflate,
int) else (inflate, ) * blocks
non_local = non_local if not isinstance(
non_local, int) else (non_local, ) * blocks
assert len(inflate) == blocks and len(non_local) == blocks
downsample = None
# 判断是否需要进行下采样。当输入的通道和输出通道不相等,则根据planes * block.expansion缩减通道数。 if spatial_stride != 1 or inplanes != planes * block.expansion:
downsample = ConvBNLayer( in_channels=inplanes, out_channels=planes * block.expansion, kernel_size=1,
stride=(temporal_stride, spatial_stride, spatial_stride), bias=False, act=None
)
上述代码为make_res_layer方法,其中包含判断block是否需要进行下采样。当输入的通道和输出通道不相等,则根据planes * block.expansion缩减通道数。在block模块中会对通道数进行缩减。
layers = []
layers.append(
block(
inplanes,
planes, spatial_stride=spatial_stride, temporal_stride=temporal_stride, dilation=dilation, downsample=downsample, style=style,
inflate=(inflate[0] == 1), inflate_style=inflate_style,
non_local=(non_local[0] == 1), non_local_cfg=non_local_cfg, norm_cfg=norm_cfg, conv_cfg=conv_cfg, act_cfg=act_cfg, with_cp=with_cp,
**kwargs))
inplanes = planes * block.expansion
构建网络,downsample作为参数传递进去。
for i in range(1, blocks):
layers.append(
block(
inplanes,
planes, spatial_stride=1, temporal_stride=1, dilation=dilation, style=style,
inflate=(inflate[i] == 1), inflate_style=inflate_style,
non_local=(non_local[i] == 1), non_local_cfg=non_local_cfg, norm_cfg=norm_cfg, conv_cfg=conv_cfg, act_cfg=act_cfg, with_cp=with_cp,
**kwargs))
return nn.Sequential(*layers)
上述根据blocks中的数量构建网络,这里的block为Bottleneck3d层。主要是用来构建一个在通道数上类似瓶颈的一个层,与ResNet系列网络一致。
class ConvBNLayer(nn.Layer):
def __init__(
self,
in_channels,
out_channels,
kernel_size, padding=0, stride=1, dilation=1, groups=1, act=None, bias=None,
):
super(ConvBNLayer, self).__init__()
self._conv = nn.Conv3D( in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias_attr=bias)
self._batch_norm = nn.BatchNorm3D(out_channels, momentum=0.1)
self.act = act if act is not None:
self._act_op = nn.ReLU()
上述代码为网络的卷积的基本单元,通过该方法可以构建一个Conv3D+BN+Relu的结构。该结构也是Bottleneck3d模块的重要组成部分。
%cd /home/aistudio/PaddlePoseC3D !python train.py --dataset_root ../data/data140593/ucf101.pkl \ --pretrained ../data/data140593/res3d_k400.pdparams --max_epochs 12 \ --batch_size 16 --log_iters 100
!python -u test.py --dataset_root ucf101.pkl --pretrained best_model/model.pdparams
dataset_root: 训练集路径
pretrained: 预训练模型路径
输入文件v_BaseballPitch_g07_c01.pkl的视频如下图所示,同时可视化v_BaseballPitch_g07_c01.pkl文件。通过predict.py可预测出该文件的所属分类。
%cd /home/aistudio/PaddlePoseC3D !python predict.py --input_file v_BaseballPitch_g07_c01.pkl \ --pretrained best_model/model.pdparams
/home/aistudio/PaddlePoseC3D /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import imp Loading pretrained model from best_model/model.pdparams There are 217/217 variables loaded into Recognizer3D. File v_BaseballPitch_g07_c01 is class BaseballPitch

参数说明:
input_file: 输入文件,按照ucf-101.pkl格式。可以使用test_tipc/data中的predict_example.pkl数据进行测试。
pretrained: 训练好的模型
模型导出可执行以下命令:
!python export_model.py --model_path best_model.pdparams --save_dir ./output/
参数说明:
model_path: 模型路径
save_dir: 输出图片保存路径
可使用以下命令进行模型推理。该脚本依赖auto_log, 请参考下面TIPC部分先安装auto_log。infer命令运行如下:
!python infer.py --use_gpu=False --enable_mkldnn=False \ --cpu_threads=2 --model_file=output/model.pdmodel --batch_size=2 \ --input_file=validation/BSD300/test --enable_benchmark=True --precision=fp32 \ --params_file=output/model.pdiparams --save_dir output/inference_img
参数说明:
use_gpu:是否使用GPU
enable_mkldnn:是否使用mkldnn
cpu_threads: cpu线程数
model_file: 模型路径
batch_size: 批次大小
input_file: 输入文件路径
enable_benchmark: 是否开启benchmark
precision: 运算精度
params_file: 模型权重文件,由export_model.py脚本导出。
save_dir: 保存推理预测图片的路径
该部分依赖auto_log,需要进行安装,安装方式如下:
auto_log的详细介绍参考https://github.com/LDOUBLEV/AutoLog。
%cd /home/aistudio/ !git clone https://gitee.com/Double_V/AutoLog !cd AutoLog/ !pip3 install -r requirements.txt !python3 setup.py bdist_wheel !pip3 install ./dist/auto_log-1.2.0-py3-none-any.whl !bash test_tipc/prepare.sh test_tipc/configs/posec3d/train_infer_python.txt 'lite_train_lite_infer'!bash test_tipc/test_train_inference_python.sh test_tipc/configs/posec3d/train_infer_python.txt 'lite_train_lite_infer'
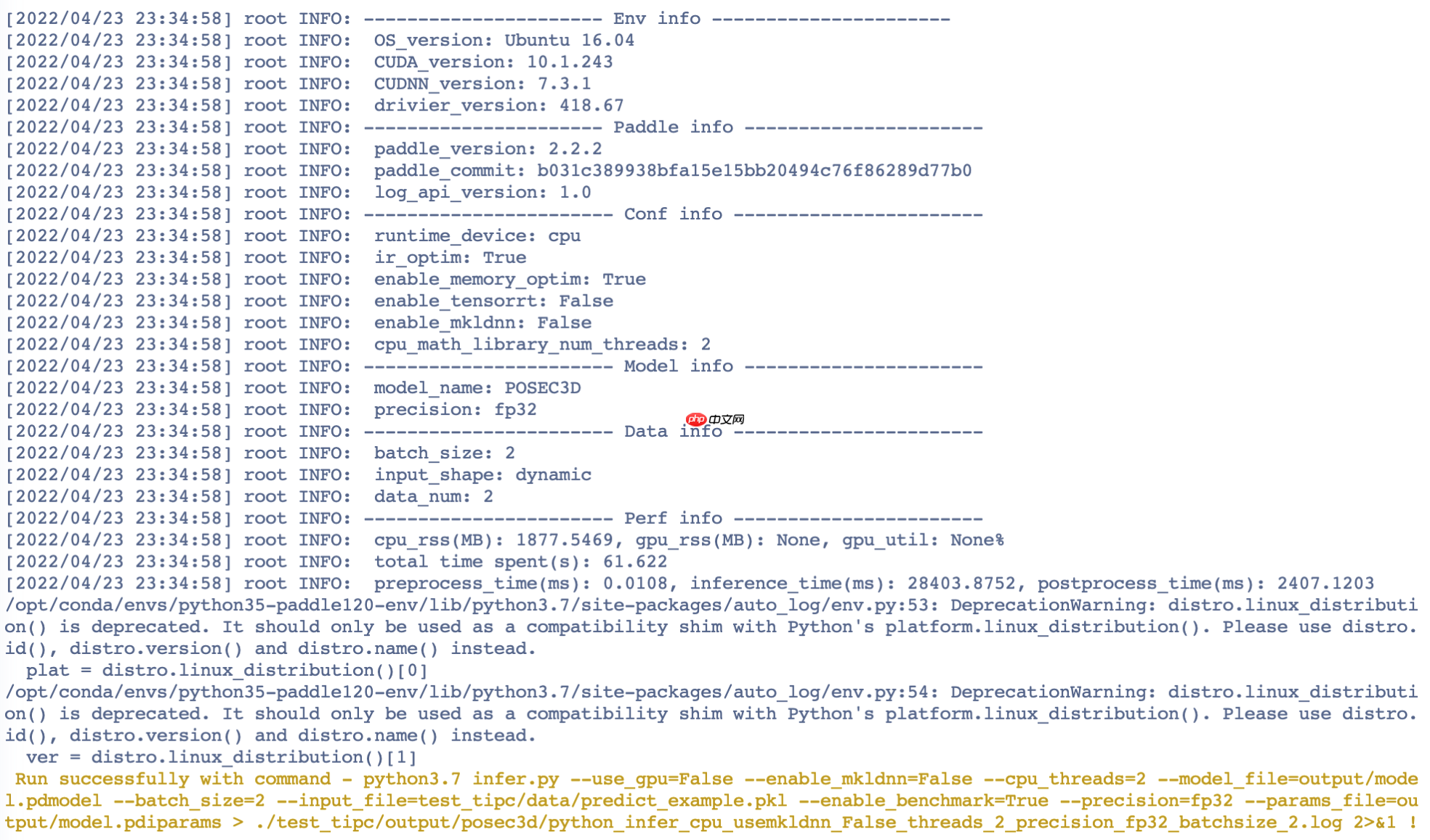
测试结果如截图所示:
PaddlePoseC3D ├── README.md # 使用说明 ├── datasets # 数据集包 │ ├── __init__.py │ ├── base.py #数据集基类 │ ├── file_client.py # 文件处理类 │ ├── pipelines │ │ └── transforms.py # 数据增强类 │ ├── pose_dataset.py # 数据集类 │ ├── dataset_wrappers.py # 数据集类 │ └── utils.py #数据集工具类 ├── models │ ├── __init__.py │ ├── base.py # 模型基类 │ ├── resnet3d.py # backbone │ ├── resnet3d_slowfast.py # backbone │ └── resnet3d_slowonly.py # backbone │ ├── i3d_head.py # c3d模型头部实现 │ └── recognizer3d.py # 识别模型框架 ├── progress_bar.py #进度条工具 ├── test.py # 评估程序 ├── test_tipc # TIPC脚本 │ ├── README.md │ ├── common_func.sh # 通用脚本程序 │ ├── configs │ │ └── posec3d │ │ └── train_infer_python.txt # 单机单卡配置 │ ├── data │ │ ├── example.npy # 推理用样例数据 │ │ └── mini_ucf.zip # 训练用小规模数据集 │ ├── output │ ├── prepare.sh # 数据准备脚本 │ └── test_train_inference_python.sh # 训练推理测试脚本 ├── timer.py # 时间工具类 ├── train.log # 训练日志 ├── test.log # 测试日志 ├── train.py # 训练脚本 └── utils.py # 训练工具包
| 信息 | 描述 |
|---|---|
| 模型名称 | PoseC3D |
| 框架版本 | PaddlePaddle==2.2.2 |
| 应用场景 | 骨骼识别 |
在之前的复现赛中复现过C3D,这次看到了PoseC3D的复现就参加了。复用了部分之前部分C3D的代码,所以这篇论文代码完成的速度比较快。参考repo使用的是8卡,我使用的Notebook的1卡V100环境,所以每个batch是参考repo的1/8,所以学习率也调整为原来的1/8。最终精度为87.05%跟源repo的87%基本一致,也是符合预期的。最后感谢飞桨举办本次比赛,也感谢AI Stuido提供算力支持。
以上就是骨骼点动作识别-基于Paddle复现PoseC3D的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 454
454




















