
引言:理解docker如何做资源隔离,揭开容器的神秘面纱。
我们在启动一个docker容器之后,在容器内的资源和宿主机上其他进程是隔离的,docker的资源隔离是怎么做到的呢?docker的资源隔离主要依赖Linux的Namespace和Cgroups两个技术点。Namespace是Linux提供的资源隔离机制,说的直白一点,就是调用Linux内核的方法,实现各种资源的隔离。具体包括:文件系统、网络设备和端口、进程号、用户用户组、IPC等资源
Linux实现的Namespace包括多种类型:
Namespace类型
系统调用参数
隔离的资源
UTS
CLONE_NEWUTS
域名、主机名
IPC
CLONE_NEWIPC
进程间通讯(用到的消息队列、共享内存)
PID
CLONE_NEWPID
进程
Network
CLONE_NEWNET
网络设备、网络栈、端口
Mount
CLONE_NEWNS
挂载点
User
CLONE_NEWUSER
用户用户组
下面我们使用go语言演示一下各种资源隔离的实现效果:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">package mainimport ( "log" "os" "os/exec" "syscall")func main() { cmd := exec.Command("sh") cmd.SysProcAttr = &syscall.SysProcAttr{ Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS | syscall.CLONE_NEWUSER, UidMappings: []syscall.SysProcIDMap{ { ContainerID: 1, HostID: 1, Size: 1, }, }, GidMappings: []syscall.SysProcIDMap{ { ContainerID: 1, HostID: 1, Size: 1, }, }, } cmd.Stdin = os.Stdin cmd.Stdout = os.Stdout cmd.Stderr = os.Stderr if err := cmd.Run(); err != nil { log.Fatalf("run faild: %+v", err) }}</code>解释一下关键代码,我们调用exec.Command来达到c语言fork进程的效果,syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS | syscall.CLONE_NEWUSER表示新的进程中,各种类型的资源使用新的namespace。(画外音:docker也封装了一个包github.com/docker/docker/pkg/reexec可以创建子进程)
编译完上面的go代码,接下来是各种Namespace资源隔离的验证环节。
UTS的验证过程:

上图中,运行刚才编译完的代码,执行后进入一个shell环境,在shell环境中,修改hostname为xingzhou。

打开新的窗口,查看hostname,发现当前的hostname不变。
这就说明了,新创建的进程中hostname和主进程是隔离的。
IPC的验证过程:

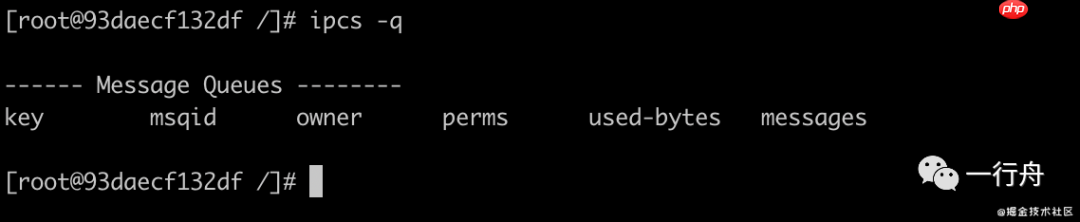
子进程:
执行ipcs -q命令, 查看Message Queues是空的执行ipcmk -Q命令,创建一个MessageQueues执行ipcs -q命令可以看到刚才添加的Queue宿主机:
执行ipcs -q命令看到,MessageQueues是空的。说明子进程和宿主机之间IPC是隔离的。
PID的验证过程:


1.在容器内执行echo $$ 命令,看到当前进程号是1
2.在宿主机执行ps aux 看到启动的服务进程号是62
Network的验证过程:
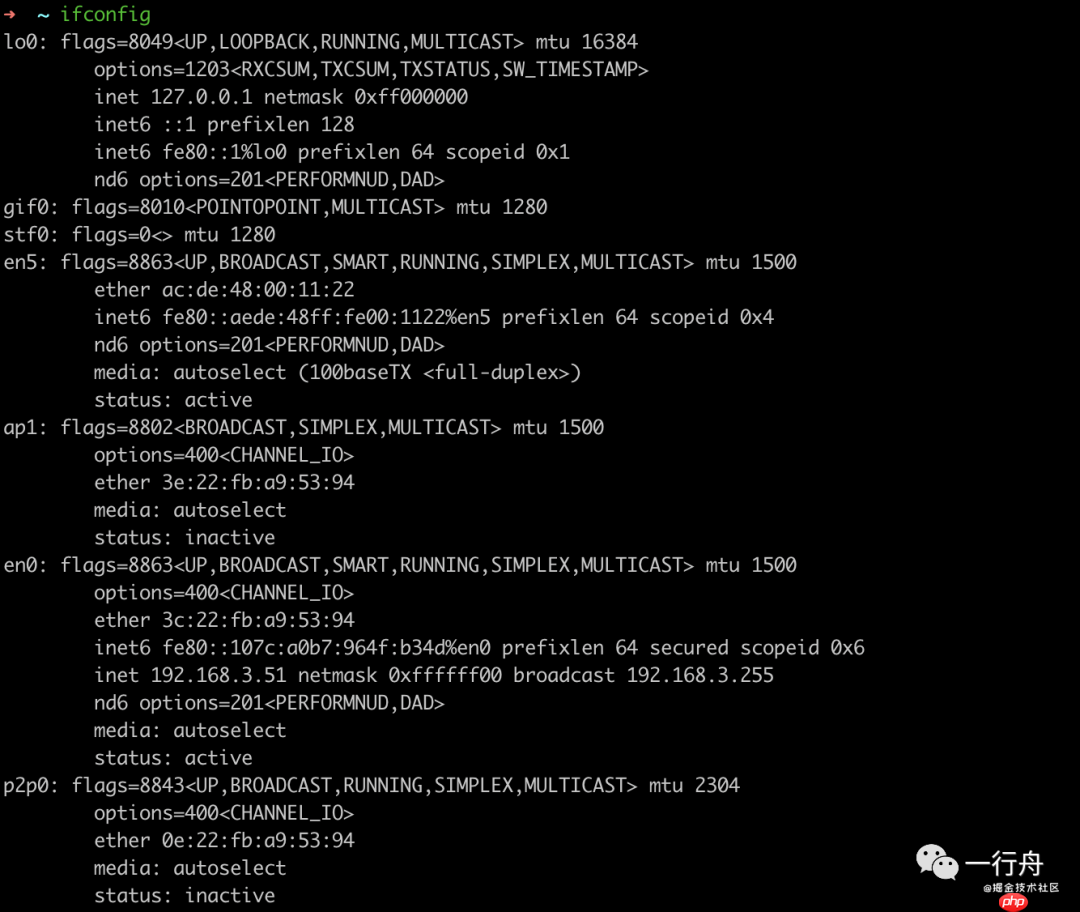
宿主机上执行ifconfig能看到网络设备信息,容器内看不到网络设备信息。
所以二者的Network的Namespace也是隔离的
Mount的验证过程:
容器内执行:


宿主机执行:

这就验证了Mount的Namespace创建成功,而且新的mount命令只会影响当前进程,并不会影响宿主机
User的验证:

然后介绍下Cgroups:
Cgroups是Linux内核提供的资源限制和隔离的机制,全称:Control groups。
Cgroups为每种可以控制的资源定义了一个子系统
具体包括:
cpu: 限制可以使用的cpu使用率cpuset:为进程单独分配cpu或者内存节点cpuacct:统计cgroups中的进程对cpu的使用报告memory:限制内存的使用blkio:限制进程的块设备io(块设备是指以“块”作为单位的设备,比如:磁盘、U盘)devices:控制进程能够访问哪些设备freezer:挂起或者恢复cgroups中的进程net_cls:标记cgroups进程的网络数据包,然后通过traffic control对数据包进行流量控制net_prio:限制进程网络流量的优先级ns:控制cgroups中的进程使用不同的namespace(不同linux版本对Cgroups子系统的实现略有差异,这里列举的内容仅仅作为参考)
docker就是调用cgroups的接口实现了不同容器对物理资源的控制。
docker依赖Linux的Namespace和Cgroups实现了进程的运行环境隔离。
docker在具体实现的时候,抽象了一个模块叫”libcontainer“,把Linux内核相关的API做了一层封装,包括Namespace、Cgroups、网络、设备等。
通过这一层抽象,增大了docker支持其他操作系统的可行性。
总结:Linux系统的虚拟化技术,为docker提供了底层技术支撑。
以上就是Docker如何实现资源隔离的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 672
672






















